Tipps & Tricks sowie Artikel zum Thema Database Security
Inhalt :
- Unified Auditing Oracle 12c in Practice Teil 4 (new 14.06.2016 )
- Unified Auditing Oracle 12c in Practice Teil 3 ( 09.03.2016 )
- Unified Auditing Oracle 12c Teil 2 (update 10.01.2016 )
Unified Auditing Oracle 12c Teil 1 (update 26.11.2015 )
Mutmaßlich flächendeckende Wirtschaftsspionage in Deutschland
Wirtschaftsspionage und Datenbanken
Innentäter
Über die Sinnhaftigkeit von Regelauswertungen für einzelne Datenbankstatements
Warum kaum in Database Security investiert wird
Database Activity Monitoring - Hightech im Namen - das reicht !
Resolving Oracle Objects oder wie Oracle über 30 Jahre lang Stolpersteine pflegt
Secure PL/SQL Code - dynamic vs. static
- Internes JDBC Gateway Oracle ( Oracle intern + MS SQLSERVER Query )
Internes JDBC Gateway als Security Feature
- Auditing sysoperation und personalisierte High Privileged Accounts
Massendaten mit dem Oracle ERRORTRIGGER vermeiden
- LISTENER.LOG auslesen mit PL/SQL
DBMS_LOB und die Quantenmechanik
- Verteidigungsschild mit Oracle System Triggern am Beispiel DDL/DCL
- Sqlplus prüft Statements nach Shutdown immediate
- openACC mit GCC oder accULL
- 'CONNECT BY PRIOR' und 'WITH' Sortierung
- LEAD/LAG und ROW_NUMBER(), ein starkes Team
- LISTAGG Ersatz
- Privilegien unter Oracle - Schluß mit dem Eiertanz
BBS Pseudo Random Sequence Generator in Java
E-Mail Verschlüsselung und Dateiverschlüsselung für Anfänger Teil 1
Multilevel secure database encryption with subkeys
- Ist Oracle 12c durch SHA-2 angreifbar ?
- Sichere Erzeugung von Schlüsseln und deren Speicherort
- Oracle DB Security - Top 30
- Komplexität der Oracle Passwörter 10g / 11g
- Eingabe des Passworts und Abhängigkeiten vom Zeichensatz
- Remote OS Authentification
- Hash Funktionen DES und SHA-1 + Salt
- Unbekannte und unmögliche Passwörter
- Externe SHA-1 Verfizierung
- Passwort merken, wenn es 12 Stellen und mehr hat
- Oracle User Profiles
- Oracle Password Verification Function
- Oracle DES Hashes entfernen
- Erstmal keine Rechte - ein ungewohnter Ansatz für mehr Datensicherheit
- Forensik - Anzeichen für Datenmissbrauch
- Forensik - Top 5
- No SQL Injection
- Secure PL/SQL Programming ( updated 25.03.2013)
- Massivst Parallel - Performance unter Oracle
- SYS_GUID() als Default Function spart bis zu zwei Trigger
- Die
Macht der Virtual Columns
- Sqlplus / as sysdba ausschalten
- Data Treasures oder warum verschlüsseln nur bedingt hilft
- Der Versuch einer sicheren Datenbank über Open Source
Einleitung
Sie hören
immer öfter von SQL-Injection, DDL-Injection und weiteren teils
fortgeschrittenen Techniken um Angriffe gegen Datenbanken umzusetzen ?
Unser Eindruck ist, das der Rummel um diese realen Bedrohungen oft von den
eigentlichen Hausaufgaben im Bereich Datensicherheit ablenken.
Wir möchten Sie nicht verängstigen, sondern sensibilisieren.
Sie werden hier nicht den Tipp finden, wie man sich im Fall Oracle remote als
sysdba anmeldet, ohne das Passwort von sys zu kennen, oder wie man im
Datenbankblock die Verpointerung der originalen Sys.user$ auf eine eigene
xxx.user$ umbiegt.
Vielleicht gibt es diese Hintertüren ja überhaupt nicht, oder sie sind derart
aufwendig und komplex, das die Wahrscheinlichkeit der Ausnutzung sehr gering
sind.
Ausgehend von dem Begriff Hausaufgaben der mit Abstand
wichtigste Punkt : Passworte !
_________________________________________________________________________________________________________
Unified Auditing Oracle 12c in Practice Teil 4 (new 14.06.2016 )
Konzerndatenbanken sollten ein Basis Audit Policy Set besitzen, sowie eine Auditdatentransportlösung zum SIEM.
12c Datenbanken sollten minimal folgende Anteile/Messagetypen enthalten:
- 11g Basisset + neue kritische Privs/Actions/Roles sofern diese überhaupt mit Standardmitteln auditierbar sind!
- LOGON FAILED
- LOGON SUCCESS als Trigger
- ERROR als Trigger
- RMAN
- AUDIT
- EINIGE FIXED TABLES- nur auf Session Ebene!
- SYSCONTEXT
- DATAPUMP
- DIRECTLOAD
- RAS/RAC
LOGON SUCCESS muss nicht unbedingt als AUDIT POLICY abgebildet werden.
Die erweiterten Informationen des SYS.USER$ (LCOUNT, LAST_LOGIN, ... )
sind den Aufwand eines Triggers wert.
Beim Errortrigger sieht die Hauptbegründung etwas anders aus.
Zentrale Erfassung aller nicht abgefangenen Execeptions und kein Audit Policy Wust.
Aus einem 11g Basisset mit ca. 40 Audit Items werden so schnell 200 Items.
Dies hängt auch damit zusammen, das Oracle alle Auditmessagetypen außer den bekannten
Privs und Actions erstmals überhaupt über Unified Auditing auditierbar implementiert.
LOGON FAILED/SUCCESS, DIRECTLOAD uns DATAPUMP sind hierfür gute Beispiele.
Der DDL/DCL Trigger kann übrigens deutlich leichtgewichtiger über eine oder wenige Audit Policies abgebildet werden.
Die Datenbank arbeitet dann besonders bei Installationen deutlich flotter!
Jetzt beginnt der Tanz.
Je nach Auslegung der expliziten Audit Policies, minimal Session oder gar auf Statementebene, der möglichen Unterscheidung von
PDB'S sowie der grundsätzlichen Aktivierung entweder als erfolgreich oder als nicht erfolgreich, kommen selbst bei minimalistischer Auslegung allerhand Auditdaten in kürzester Zeit zusammen.
Die zusätzlichen möglichen Conditions in einer Audit Policy wurden in der vom Autor entworfenen Lösung nicht angewendet. Hier gilt es den Laufzeitbremseffekt dem Nutzen gegenüberzustellen.Prinzipiell sind diese Conditions einfach Filter die Datenmengen reduzieren können.
Zusätzlich kommt bei einer internen Auditdatentransportlösung (PL/SQL) z.B. im Push Verfahren ein kleiner Overhead für den Selbstschutz dieser Anwendung hinzu.
Das Problem ist die Sonderlocke, die sich hinter der View UNIFIED_AUDIT_TRAIL verbirgt. Ein Tabellenkonstrukt, vermutlich ein Secure File Derivat, das streng genommen überhaupt nicht beschreibbar ist, dafür jedoch weitgehenden Schutz vor Manipulationen der üblichen Art liefert.
Jeder Zugriff auf die Unified_Audit_Trail bei Counts > 100.000 kann schon wehtun. Ab 1 Mio Auditdatensätze wird es irreal.
Es gibt keine Chance der Zugriffsoptierung. Wenn auch noch CLOB Felder wie 'sql_text' in einer Auditdatentransportlösung mitübertragen werden, bekommt man zusätzlich schnell Schwierigkeiten mit dem PGA Memory wenn nicht allerhand Vorsorge bei der Programmierung diesbezüglich getroffen wird.
Um es mal einfach auszudrücken, Unified Auditing ist für folgende Einsatzzwecke konzipiert.
Wenig Audit Policies, noch weniger Audit Items und idealerweise alles nach dem Transport löschen.
Realistisch ist solch ein Szenario nicht. Allein die Löschlogik würde zudem Lücken im Auditdatenstream zulassen.
So nicht!
Will man hingegen die Auditdaten zyklisch in Tranchen (event_timestamp von-bis) versenden, wird es schnell teuer.
Eine Möglichkeit wäre eine recht hohe Frequenz eines Auditdatenjobs, der versucht die Auditdatenmenge generell recht klein zu halten.
Versuchen kann man es, doch was passiert, wenn z.B. hinterlegte Passwörter für den Datenbank Connect nicht vollständig geändert wurden. Zyklische Connect's von Agent's, Monitoren usw. erzeugen in kürzester Zeit hohe Auditdatenmengen.
Optionale Vorhaltepuffer, die z.B. den DBA's nun weitgehend unbedenklich Informationen über die letzten 24 Stunden geben ohne gelöscht zu werden treiben die Größe des Unified_Audit_Trail tendenziell in die Höhe.
Die Manipulation der Auditdaten ist auf Lowlevel Ebene zwar denkbar, doch kann dies mit Plausibilitätsprüfungrn und Checksummen als Bestandteil des Transportmechanismus, vergleichsweise einfach im SIEM erkannt werden.
Die Ablage der Checksummen muss natürlich selbst überwacht werden.
Im Sinne einer minimalen Gesamtbelastung, sollte die Auditdatentransportlösung zudem weitgehend von 'breiten' Zwischentabellen im Sinne der Verdichtung sowie komplexen internen Jobläufen befreit sein.
Alles unter einen Hut zu bringen fordert schon etwas Einsatz, den gewiss jeder nicht treiben will.
Fazit:
Aus Sicht des Autors ist das Unified Auditing in der aktuellen Form (12.1.0.2) operativ als Konzernlösung praktisch nicht einsetzbar.
Es ist möglich, doch der Aufwand und die Komplexität sprengt den üblichen Rahmen einer operativen Security Lösung.
Oracle sollte hier dringenst nach bessern.
1.a) Normale evtl. Partitioned Tables ohne update,delete,merge,truncate, drop
1.b) Extern abgelegte und geschützte Tabelle im Filesystem
2.) Clob Marker <= 32k und > 32K
2.) PK für UNIFIED_AUDIT_TRAIL
3.) Purge auf Basis beliebiger Ausdrücke/Spalten
4.) Vorhaltepuffer per DBMS_AUDIT_MGMT über Stunden und Anzahl einstellbar.
5.) Aggregationstemplates vor der Ablage im Unified_Audit_Trail
6.) 'Translate any SQL' und 'Inherit any Privilege' sollten auditierbar sein.
Kommentar :
Wenn Oracle ein Pseudo Feature namens Unified Auditing entwickelt hätte und es eigentlich um Audit Vault Lizenzen gehen sollte, wäre dies schon nicht mehr dreist sondern unverfroren.
Wer seine Datenbank schützen will muss ordentlich bezahlen, sei es mit ASO bzw. mit Audit Vault, usw.. Eine Regelung die nicht nur vielen Agencies in die Hände spielt.
Das die Probleme mit dem PGA Speicher erstmals mit der Version 12c massiv auftreten hat hoffentlich nichts mit
der In-Memory Option und deren Verkauf zu tun.
In diesem Sinn ein P(r)ost-greSQL auf freie Software.
Am 5.7.16 spricht übrigens Richard Stallmann in Frankfurt/Main.
Unified Auditing Oracle 12c in Practice Teil 3 ( 09.03.2016 )
Herleitung der Aussage :
Die Auditierung von Oracle Datenbanken ist flächendeckend machbar bei akzeptablen Kosten für die Datenbank.
Pure Unified Auditing ist die Konfiguration bzw. Zielkonfiguration vieler 12c Datenbanken.
Was sollte man beachten, wenn man eine Transportlösung von Auditdaten, konkret Auditmessages, in Richtung SIEM entwickelt ?
Die Gliederung der Audit Policies sollte minimal über die Audittypes welche Oracle vorgibt, erfolgen.
- Standard
- FineGrainedAudit
- XS
- Database Vault
- Label Security
- RMAN_AUDIT
- Datapump
- Direct path API
Eigene Audittypes könnten z.B. LOGON SUCCESSFUL und LOGON FAILED sein.
Letzterer ist sinnvollerweise durch eine Audit Policy abbildbar.
Die interessanten Informationen hingegen erhält man über den Audittype LOGON SUCCESSFUL, der über
einen AFTER LOGON Trigger abgebildet werden sollte.
Wenn man nun für jeden seiner Messagetypen ein eigenes Format entwickelt, erzeugt das allerhand Aufwand im SIEM.
Alle Informationen statisch in ein Messageformat abzubilden kann man, muss es aber nicht.
Key/Value benötigt generell mindestens eine Umformung.
Besser ist folgender Aufbau: Header, Standard Payload und erweiterte Payload, die auf die jeweiligen Audittypen abgestimmt sind.
Rein auf Performance darf man hier nicht optimieren. Man muss den bitteren Fakt miteinbeziehen, das Datenbank Security Know How erst sehr spät in der Kette der Auswertungs- Bewertungs- Prozesse vorhanden sein wird und dies in nicht mal 1% aller Fälle.
Daher sind die Vorbereitungsarbeiten bezgl. Auditmessages wie die Gliederung, das Messageformat und mögliche Vorbewertungen von besonderer Bedeutung.
Das Thema Vorbewertung wird oft ohne trifftiges Argument von der SIEM Auswertungsseite kategorisch abgelehnt.
Der Autor hält dies für nicht sinnvoll. Mitunter bekommt man den Verdacht, das lizenzrechtliche Gründe von bestimmten SIEM Produkten eine Rolle bei dem Thema spielen. Stichwort : Datenvolumina. Wer etwas vor der Versendung filtert, aggregiert und/oder vorbewertet, wird im Schnitt weniger Daten an ein SIEM versenden als Systeme die dies nicht tun.Zudem können Auswertungs und Bewertungsprozesse hinter dem SIEM optimiert werden.Dies im Sinne der Datensicherheit und der eingesetzten Manpower.
Der Knackpunkt liegt in der Erkennung von reinen Datenbankangriffen, wenn es soetwas überhaupt gibt, bzw. in der Vorbewertung eines Sicherheitsvorfalls.
Beispiel : 'grant dba to public'. Ohne Zweifel in nahezu allen Datenbanken außer denjenigen der Kommune 69, ein schwerer Sicherheitsvorfall.
Wie kommt es zu solch einem Statement ?
Entweder war es ein Spielkind, ein Anteuscher der den eigentlichen Angriff über einen anderen Weg überdecken will, oder vielleicht ein Pentester.
Der DDL/DCL Trigger führt sein Revoke sofort aus und alle Daten bezgl. 'grant dba ...' werden mit einem sehr hohen Kritikalitätsfaktor an das SIEM versendet.
Hier wird sogar aktiv eingegriffen. Noch so ein Thema, bei dem die 'Gelehrten' gerne in Wallung kommen.
Das Beispiel mit 'grant dba to public' dürfte in heutigen Zeiten nahezu überall ein 'no go' sein. Bis die Auswertungs- und Bewertungs- Prozesse nach üblichem Ablauf den Revoke Befehl bei einem Security DBA in Auftrag geben, kann je nach
Effektivität des Gesamtablaufs eine gehörige Zeit mit den sozialistischen DBA Rechten vergangen sein.
Datenstrukturen :
Oracle hat das Unified_Audit_Trail deutlich breiter ausgelegt im Vergleich zur klassischen sys.aud$.
Trotz der vielen Attribute in der View Unified_Audit_Trail gibt es Auditszenarien, die höchst individuelle Informationen benötigen.
Warum Oracle hier keine asynchrone Anreicherung der Unified Auditing Daten anbietet, ist unverständlich.
Der Vorschlag lautet :
Audit Policies schreiben mit Bedingungen in einer Flagdatenstruktur. Wenn dort mehrere Flags für einen potentiellen Sicherheitsvorfall eintrudeln, die einer definierten Granularität entsprechen, wird asynchron eine frei definierte PL/SQL Procedure/Function ausgeführt, welche die zusätzlichen Daten in eine per referenzieller Integrität verknüpften Subtabelle der Unified_Audit_Trail schreibt.
z.B. via Key/Value. Den Zeitpunkt für diese Ausführung entscheidet die 'schlaue Datenbankversion 12c' selbst.
Da es soetwas derzeit noch nicht gibt, muss man ggfs. auf Database Trigger bzw. auf die 'sys_events' Architektur zurückgreifen.
Drei Database Trigger stehen bei Härtungen praktisch immer zur Diskussion.
- LOGON
- ERROR
- DDL/DCL
Der Logon Trigger ist ein After LOGON Trigger und damit die Variante Successful.
Neben der LoginTime, LastLoginTime, den CountFailedLogins können noch etliche weitere Informationen über den betrffenden Acount via sys.user$ und sys.dba_users ermittelt werden.
Der Trigger macht Sinn gerade im Vergleich zu einer Audit Policy auch wenn er bei den ganzen Informationsermittlungen Kosten verursacht. Eine Filtertabelle, welche festgelegte Loginvorgänge aus dem Triggercontext herausfiltert, sollte zur Absicherung gegen Massendaten implementiert werden. Ein Monitoringccount, der sich alle paar Sekunden einloggt, könnte ansonsten die Datenmengen ohne Aggregation gewaltig in die Höhe treiben.
Der After Error Trigger ist ein spezieller Kandidat.
Kann er doch die nicht behandelten Exceptions Ihrer Software unbarmherzig ans Tageslicht befördern.
Diese können gerade bei Kaufsoftware und je nach Release, extrem große Datenmengen ohne Aggregation erzeugen.
Diesen Anteil sollte man zyklisch mitlaufen lassen jedoch nicht generell bzw. im Aggregationsmodus. Wenn man seine Pappenheimer kennt, sind temporäre Filter durchaus zulässig.
Ein zweiter Anteil sind diejenigen Errors, die typischerweise mit Exploits bzw. deren Vorbereitung erzeugt werden können.
Dieser Anteil sollte generell mitlaufen. Wie man die beiden Anteile unterscheidet ist kein Hexenwerk dafür harte Arbeit.
Der DDL/DCL Trigger sollte nur sehr rudimentär oder überhaupt nicht verwendet werden.
Ein vergleichbare Audit Policy mit den wichtigsten DCL und DDL Actions/Privs kostet um den Faktor 30 weniger.
Gefährliche Grants wie z.B. "grant dba to public" würde ich mit einer aktiven Revoke Gegenmaßnahme im Trigger belassen.
Damit der Name Unified Auditing seinen Namen verdient, kann man etwas nachhelfen. Falls Database Trigger verwendet werden, können die Daten über eine simple Audit Bypass Policy von der Triggertabelle in das Unified Audit Trail umgeleitet werden, ohne das in die Triggertabellen geschrieben wird! Default dort "Rollback" statt "Commit Write".
Bleibt die Implementierung der eigentlichen Versendung von Auditdaten.Direkt oder mit Zwischenschritten.
Empfohlen wird das Push Verfahren und die direkte Versendung.
Hier steht die Lastverteilung im Vordergrund.
Das ist kein Gimmick sondern das zentrale Akzeptanzfeature für die Einführung von flächendeckendem Auditdatentransport.
Ohne eine ausgefuchste Lastverteilung werden viele Datenbanken nur äußerst rudimentär oder überhaupt nicht auditiert.
Die Lastverteilung sollte parametrierbar sein z.B. über eigene Application Context Key/Value Paare.
Was ist in einem solchen Sektion alles zu tun ?
Wir haben z.B. Messageviews die auf der Unified_Audit_Trail aufsetzen.
Wir haben zumindest bei Spalte 'SQL_TEXT' ein Clob, welches eine Aufteilung der Messages in teilweise recht viele Einzelmessages durchführt und wir haben eine Versendelogik vielleicht einen TCP/IP Socket.
All dies performant mit dem speziellen Tabellentyp der Basistabellen der Unified Audit Trail abzubilden ist selbst für einen alten Hasen allerhand Aufwand.
Die Tabelle Unified_Audit_Trail verhält sich bezgl. Performance nicht wie eine gewöhnliche Tabelle ohne Indizes.
Spätestens ab 50.000 Datensätzen wird jeder Zugriff auf das Unified Audit Trail äußerst kostenintensiv.
Daraus folgt, das man eine lastverteilende Logik entwickeln sollte, die ein Anwachsen des Unified Audit über einen definierten Schwellwert für maximal einen Tranchenlauf erlaubt.
Teuer sind vor allen die Bestimmungen von Timestamps, die für den Purge des Unified Audit Trail zwangsweise durch Oracle Vorgaben notwendig sind.
So ein Timestamp im Unified Audit Trail ist nicht eindeutig. Das gilt ebenso in Verbinding mit der Entry_id und der Instance_id.
Gelöscht wird, wenn das Package DBMS_AUDIT_MGNT dazu aufgelegt ist in der Logik ' echt kleiner' bzw. 'echt älter'.
Bis 12.1.0.1 ist der Purge absolute Glückssache bei Größen bis zu 1500 Datensätzen.
Ab 12.1.0.2 wurde dies im Schnitt auf etwa 800 Datensätze reduziert.
Konkret bedeutet das, das wenn z.B. 10000 Datensätze per Purge entfernt werden sollen, das bis zu 1500 / 800 Datensätze je nach DB Version nicht entfernt werden.
Dafür ist die fehlerhafte Purge Prozedur schnell. Vermutlich wird asynchron im Hintergrund gelöscht. Dies muss allerdings
erst noch nachgewiesen werden.
Wer jetzt noch einen Vorhaltebuffer mit einer Anzahl von jüngsten Datensätzen konkurrierend in Stunden und einem absolutem Wert angibt, der kann die Auditdaten zwar versenden, entfernt werden sollten diese Daten aus den unterschiedlichsten Gründen jedoch nicht.
Meist ist so ein Vorhaltepuffer ein Zugeständnis an die DBA Truppe. Diese hat i.d.R. gute Gründe, die jüngsten Auditdaten z.B. des letzten Tages direkt einsehen zu können. Natürlich besteht ein Restrisiko das DBA Fehler oder DBA Angriffe aus dem Unified_Audit_Trail herausgelöscht werden könnten. Dies würde allerdings zu Lücken im Unified_Audit_Trail führen.Daher sollten
nicht alle zyklischen Aktionen gegen die DB über die Filterlogik herausgefiltert werden. Kontrollaggregate können einen Nachweis
für den regulären Betrieb ohne Eingriffe liefern.
Weiterhin ist die fehlerhafte Purge Funktion des Package DBMS_AUDIT_MGMT eine weitere Abschreckung.
Insgesamt steht der Autor auch hier auf der pragmatischen Seite. Die Vorteile des Vorhaltebuffers für den Gesamtbetrieb wiegen stärker als das beschriebene Restrisiko. Sicherheit beinhaltet auch die Begriffe Stabilität und Konsistenz.
Die Lastverteilung erfolgt z.B. über Parameter wie : max. Messages / Tranchenlauf (5000) und dies alle 5 Minuten im Zeitraum
19:00-5:00
Wenn man diese ganzen Fälle performante implementiert hat und die Lastverteilung funktioniert, steht einer Einführung der
Transportlösung nichts mehr im Wege.
Codierungsrichtlinien und Test
Die performante Implementierung ist ein Paradebeispiel für die bedingte Gültigkeit von den vielen klugen Ratschlägen, wie ein PL/SQL Programm aussehen sollte. Bei mir kam jedenfalls eine sehr kompakte
Procedure heraus. Diese hat allerdings eine Komplexität mit mindestens dem Faktor 5 -10 gegenüber der 'Vorschrift'.
Dafür arbeitet sie recht flott und fast alle potentiellen Fehler sind in ca. 200 Zeilen zu finden.
Noch dazu ist das Gesamtprojekt bezgl. Code auf eine Person aktiv + 1 Person Review ausgelegt.
Selbst in einem 80 Personen Projekt würde ich diese Prozedur verteidigen.
Wer sich die Mär von einer gleichmäßig verteilten Komplexität ausgedacht hat, weiss ich nicht.
Wenn es Komplexitätspeaks gibt, kann das Vereinfachungen im Rest des Quellcodes bedeuten.
Beide Aspekte vereinfachen das Testen vom Gesamtaufwand her wesentlich.
Lieber in 50 x 200 Zeilen 95 % der Fehler nachweisen als in z.B. 200.000 Lines of Code einen gleichmäßig, umfassenden und insgesamt gigantischen Testaufwand betreiben.
Testen wurde in 1980er/1990er Jahren gerne unterbewertet. Heute würde ich sagen: Es wird teilweise übertrieben.
Absicherung des Transportmechanismus
Wichtigste Regel : Push Verfahren
Wer etwas nachdenkt, wird eine einfache Maßnahme entdecken, welche die Unversehrheit des Transportmechanismus ohne künstliche Datensendungen zu jedem Laufzeitpunkt sicherstellt. Die Gesamtheit der Datensendungen kann im SIEM einfach überprüft werden.
Die Absicherung der Auditdaten gegen Manipulation sowie die Absicherung der Metadaten des Transportmechanismus gegen Manipulationen ist nach meiner Meinung mit Abstand der komplexeste Teil des Gesamtprojekts. Als kleiner Wink sei die das Wort Audit genannt.
Eigene Designfehler oder auch nicht:
Anfänglich hatte ich wunderschöne Parallel Pipelined Tablefunctions entworfen. Einmal um die Messages aufzusplitten und einmal für die Versendung. Die jeweiligen 'dicken Cursor' Ausdrücke hatten allerdings ihren Preis.
Die Parameter PGA_AGGREGATE_LIMIT der 12c musste auf 10GB hochgezogen werden um Fehlermeldungen beim Parallelisierungsgrad 8 zu vermeiden.
Ein typischer Copy/Paste Fehler, der allerdings durch die Tatsache entsteht, das die Hints in Oracle unglücklicherweise mit Remarks verwechselt werden können.
Wenn Tablefunction A mit dem Parallelisierungsgrad 8 einen Cursor mit dem Aufruf einer weiteren Tablefunction B ebenfalls mit dem Parallelisierunggrad 8 erhält, dann laufen bis zu 64 Prozesse!
Wer jedoch seine Auditdaten in einem kleinen Zeitfenster ohne ein Limit von Kosten verarbeiten will, kann sich dieses Ansatzes annehmen.
Quasi der Turbo mit Ladedruck 2,0 bar, solange der spannungsfreie Motorblock dies mitmacht.
Interessant ist, das selbst Socketkommunikation per Parallel Query sauber parallelisiert werden kann, wenn man einige Regeln befolgt.
Diese Regeln sind allerdings Betriebsgeheimnis ...
Unzulänglichkeiten von Oracle im Kontext Unified Auditing:
Bis 12.1.0.1 kein Audit auf Fixed Tables in PDB's möglich.
Setter Audit's der RAS Policy ebenfalls bis 12.1.0.1 PDB's nicht möglich.
Fehler beim Purge bis mindestend 12.1.0.2. Einige Datensätze werden zu 90% nicht gelöscht.
Purge nur auf Timestamp Basis ist nicht sinnvoll. Alternativ über ID von / bis
Index Ermöglichung auf Basistabellen der Unified_Audit_Trail.
Erweiterung der Conditions von Audit Policies mit Aufruf eigener Procedures/Functions zur Datenanreicherung.
Ein Mini API basierend auf sys_events bzw. komplett individuell. Ergebnisse in eine Key/Value Audittabellle.
Gesamtperformance:
Was kostet weniger : Ein SUV mit 3 to Realfahrgewicht und 300PS oder ein Mittelklassewagen mit 1,4 to und 150PS ?
Der SUV ist die Datenbankversion 12c im Pure Unified Auditing Mode. Viele neue Funktionen der 12c verlangen zwangsläufig nach einer Auditierung. Die gefährlichsten neuen Funktionen lassen sich zudem mit dem den neuen Allheilmittel Unified Auditung überhaupt nicht auditieren.
Das Ergebnis einer einzelnen Audit Policy kann günstiger sein als das Ergebnis der klassischen Audit Statements Pendants, muss es aber nicht. Die Auswertungszeit ist zwar nicht günstiger, jedoch die Datenmengen können deutlich reduziert sein.Insgesamt kann dies ein Vorteil bedeuten, jedoch nur bei einer sorgsamen Balance von Bedingungen in Audit Policies und deren Nutzen in Bezug auf Datenreduktion bzw. in Bezug auf den Gesamtablauf z.B. Vorbewertung.
Die Gesamtbelastung der Auswertungen einer 12c liegt bei einer hinreichend* bemessenen Härtung jedoch höher als bei hinreichend bemessenen Härtung der Version 11g. Die Tricks der Queued Write für das Unified Audit Trail kann einiges von dieser Gesamtbelastung wettmachen. Dies allerdings zu Lasten der Gesamtsicherheit. Cached Auditing Data. Darauf muss man ersteinmal kommen.
In jedem Fall ist das Löschen der Auditdaten in der Datenbank 12c deutlich effizienter als die schnellste Commit Point orientierte Löschroutine z.B. der sys.aud$.
Mit dem Mixed Mode könnte man übrigens tatsächlich etwas Gesamtbelastung einsparen, allein durch sys_operations=true.
Die Übernahme der Aud-Files in das Unified_Audit_Trail ist das eigentliche Killerfeature des Mixed-Mode.
Fazit : Unified Auditing und auch Pure Unified Auditing ist ein Schritt in die richtige Richtung. Es sollte weiterentwickelt werden.
Die Datenbankversion 12c abzusichern erfordert deutlich mehr Aufwand im Policy Design im Vergleich zur Version 11g.
Das Policy Design kann je nach Händchen ein Gewinn sein oder ein Schuß in das berühmte Knie werden. Der Schlüssel sind wenige optimierte Bedingungen mit einem hohen durchschnittlichen Nutzwert.
Die Zwänge die Oracle dem Unified Auditin auferlegt und damit die Security Fraktion in ein sehr starres Korsett zwingt, sollten überdacht werden. Den Denkansatz das Auditing als Nicht DBA Task nahezu durchgängig abzubilden soll dennoch ausdrücklich gelobt werden. Der Teufel steckt allerdings wie immer im Detail.
Die Auditierbarkeit von DataPump, DirectLoad, RMAN, AUDIT, SYS CONTEXT sowie RAS, teilweise nicht abschaltbar, ist aus Sicht der Datenbanksicherheit ein echter Gewinn.
Mit solchen Auditdaten werden Sie nicht nur vielen illegalen Datenabziehern auf die Schliche kommen.
* hinreichend in dem Sinn: Machbarkeit mit den Mitteln des Unified Auditing.
z.B. 'Translate Any Sql' und 'Inherit Any Privileges' erfordern erhebliche individuelle Zusatzmaßnahmen um diese überhaupt auditierbar zu machen.
Unified Auditing Oracle 12c Teil 2 (new 10.01.2016 )
Mit dem Artikel von Uwe Hesse über den Performance Impact von Unified Auditing fühlte sich der Autor an die Zeiten der Oracle 7,8,9 Vorführungen erinnert, die mit teils undokumentierten Caching-Parametern, die jeweilige Datenbankversion als regelechten Turbo auswiesen. Damals wurden vor den Vorführungen alle relevanten Tabellen für einen bestimmten Use Case in den Memory geladen, der Transaction und Write Overhead deaktiviert und der Tanker Oracle wurde zum Porsche Turbo.
http://uhesse.com/2015/07/31/less-performance-impact-with-unified-auditing-in-oracle-12c/
In dem Artikel wird eine einzelne Audit Policy erstellt die ein einzelnes Select auf eine Anwendertabelle auditiert.
Ein identisches Select Statement wird 100000 Mal aufeinander folgend ausgeführt um den Performance Impact zu messen.
Ob die Auswertung von 100000 Select's die unterschiedlich ausfallen sich bezgl. Performance Impact anders darstellen, erfahren wir nicht.
Gemessen wird:
Auswertung Audit Policy mit Erkennung 100000 identischer Statements + Write Overhead in eine 'Read only Table'.
Wenn man den Performance Impact bzgl. Auditing von 11c und 12c vergleichen will, sollte man einges bedenken:
Ein direkter Vergleich von Audit 11g mit Create Policy - Audit 12c, macht nur bei vergleichbarem Security Level Sinn.
In jedem Fall sollte der Security Level einer Oracle 12c nicht niedriger als der einer 11g sein.
Da ein 11g Audit immer Immediate Write und ohne Caching in der SGA abgearbeitet wird, ist der Vergleich mit der Unified Auditing Einstellung
EXECUTE DBMS_AUDIT_MGMT.SET_AUDIT_TRAIL_PROPERTY
(
...
=> DBMS_AUDIT_MGMT.AUDIT_TRAIL_IMMEDIATE_WRITE);
durchzuführen.
Vergleicht man 11g Audit mit 12c Queued Audit Write vergleicht man Äpfel mit Birnen.
Das Caching von Auditdatensätzen ist deswegen gefährlich, weil Angriffe genau aus diesem Grund mit Forcierungen von ORA-600 Fehlern, wenn nicht gar dem vollständigem Stillstand der Oracle Datenbank abgeschlossen werden könnten.
Dies kann neben dem Sinn der Verschleierung des Angriffs zusätzliche kostenintensive Schäden verursachen.
Der Vorteil für die Angreifer besteht darin, das diese mit Zero Day Exploits arbeiten können, die wahrscheinlich nicht nachvollzogen werden können. Die Methoden zur Forcierung von Ora-600 Fehlern und Stillstand der gesamten DB sind offenbar nur sehr bedingt bei den bekannten Security Researchern bekannt.Entweder entwickeln diese wenig oder sie nutzen nicht die gesamten Funktionalität der Datenbank aus.
Wenn man nun 11g Auditing mit 12c Pure Unified Auditing Audit Write Immediate vergleicht, macht es weiterhin wenig Sinn eine einzelne Auditpolicy für ein Select Statement zu erstellen und dieses identische Select in einem Loop 100000 Mal durchlaufen zu lassen.
Das ist praxisfremd und wirkt ein wenig hingetrickst auf die Nutzung von mehrstufigen Caches der Oracle DB mit dem gewünschten Nachweis, das Unified Auditing weniger Performance Impact verursachen (muss).
Etwas eindimensional. Warum?
- Erstens nur eine Policy.
- Zweitens eine optimierte Erkennung von identischen Statements im Memory der 12c im Gegensatz zu 11g.
- Drittens die Queued Write Audit Einstellung, zumindest in dem Artikel von Uwe Hesse.
Realistischer ist da schon folgender Vergleich:
1.) Ein komplettes 11g Audit Set z.b. ein Hardening Audit Set mit seiner Abbildung via Audit Policies in 12c Pure Unified Auditing
2.) Dies vorerst im Non-Multitenant(Single Instance) Mode der 12c, der mittlerweile deprecated ist.
3.) Jeweils mit der identischen Einstellung in Bezug auf 'force logging' auf Datenbankebene.
Mit Force Logging kann auch bei 12c mit Pure Unfified Auditing sys_operations=true ergebnistechnisch erzwungen werden.
Auch wenn der MOS-Artikel bekannt ist, läuft sicher nicht jede Oracle Datenbank in diesem Modus.
https://oraculix.wordpress.com/2009/06/18/risiken-bei-der-verwendung-von-nologging/
Hat man das Audit Set Hardening Basic mit z.B. 30-40 Audit Statements in einer 11g flach abgebildet, gibt es bei dessen Abbildung
über Audit Policies unzählige Varianten, die entscheidend für die Performance sein können.
Die einen schreiben soviele Actions und Privs wie möglich in eine oder wenige Audit Policies.
Andere strukturieren gerne und enden mit einer Anzahl von vielleicht 5 oder 15 Audit Policies.
Fängt man an bestimmte unnötige Auditdateneinträge des 11g Audit Sets über mehr oder minder
komplizierte Bedingungen der Audit Policy Syntax der 12c herauszufiltern, oder versucht Redundanzen akribisch mit Bedingungen zu eleminieren, kann dies zu einem deutlichen Performance Impact
führen. Nicht zwangsläufig durch eine Audit Policy jedoch in einer Gesamtbetrachtung realistischer Einsatzszenarien.
Mit den Conditions wird u.a. ein Werkzeug geliefert um die Datenmengen zu kontrollieren. Dies wird allerdings an einer recht ungeschickten Stelle mit allerhand Kosten erkauft. Besser sind Postffilter / Postaggregations.
Mit diesem Mttel lassen sich auch Redundanzen herausfiltern.
Zsätzlich kommen noch neue Privs und Actions der 12c hinzu, die in einem Basic Hardening nicht fehlen sollten.Diese neuen Privs und Actions sind teilweise nicht über Unified Auditing auditierbar. Der Aufwand dies doch zu realsieren kostet einiges.
Wenn man schon den Performance Impact von Unified Auditing in den Fokus stellt, das darf man die Zwangsmaßnahmen von
Oracle nicht vergessen.
Diese sind, auch wenn sinnvoll, gleich ob Pure oder Mixed Mode, implizite, nicht vorinstallierte Audit Policies,
die folgende Actions bzw. Privs auditieren und nicht deaktivierbar sind und die Datenbank nicht gerade schneller machen.
RMAN Operations
CREATE AUDIT POLICY
ALTER AUDIT POLICY
DROP AUDIT POLICY
AUDIT
NOAUDIT
EXECUTE of the DBMS_FGA PL/SQL package
EXECUTE of the DBMS_AUDIT_MGMT PL/SQL package
ALTER TABLE attempts on the AUDSYS audit trail table (remember that this table cannot be altered)
Top level statements by the administrative users SYS, SYSDBA, SYSOPER, SYSASM, SYSBACKUP, SYSDG, and SYSKM, until the database opens. When the database opens, Oracle Database audits these users using the audit configurations in the system—not just the ones that were applied using the BY clause in the AUDIT statement, for example, but those that were applied for all users when AUDIT statement does not have a BY clause or when the EXCEPT clause was used and these users were not excluded.
All configuration changes that are made to Oracle Database Vault
In dem erwähnten Artikel von Uwe Hesse wird übrigens ein wenig vorschnell auf sysdba Auditierung geschlossen und der Eindruck erweckt diese wären lückenlos.
Audit könnte den einen Teil erklären. Top level Statements von SYS, SYSDBA, SYSOPER, SYSASM, SYSBACKUP, SYSDG, and SYSKM den anderen.Alterativ RMAN. Oder 'force logging'.
Jetzt kommen noch einige neue Features des Unified Auditing:
Actions Components wie Datapump und Direct Load sowie Application Context Parameter waren bislang nicht direkt auditierbar, machen jedoch Sinn.
Hinzu kommem minimal die beiden Oracle Audit Policies für RAC Systeme.
Schlußendlich noch das Thema sys_operations=true, das eigentlich in jedem Hardening Konzept bis 11g eine wichtige Rolle einnimmt und lückenlos sein sollte. Selbst wenn dies die Auditierung von ellenlangen SQL-Scripten beinhaltet.
Dies kann in einer 12c mit den Mitteln des Pure Unified Auditing nur über die Datenbankeinstellung 'force logging' erreicht werden.
Ohne force logging wird es mühsam alle sys operations samt Fehler zu auditieren.
Ohne einen System Database Trigger After Error wird es gewiss nicht gehen.
Nun kommt die ersten Stufe der Transformationen des Vegleichs.
12c Singletenant:
Hier funktionieren einige Audit Policies z.B. auf Fixed Tables nicht.
Gleiches gilt für 12c Multitentant, zumindest für die PDB's.
Nun zum Löschen
Wer ein truncate in einem laufenden operativen System auf sys.aud$ absetzt, hat das Auditing im Sinn seiner Bedeutung nicht verstanden.
In einem Hardenung/Audit Konzept wird für gewöhnlich partiell gelöscht und zwar zeit und/oder mengenorientiert.
Die Gründe liegen nah. Performance Impact ( Verteilung über die Zeit) und festgelegte Verfügbarkeit jüngerer Auditdatensätze für Analysen. Dies ist zweifelos einer der teuersten Punkte der 11g Implementierung.
Man kann zwar über Delete direkt mengenorintiert löschen, doch ist die sys.aud$, egal in welchem Tablespace sie sich befindet,
eine normale Tabelle im read-write Mode.
Hier hat das Unified Auditing mit den Fixed Table ähnlichen CLI... Tables einen deutlichen Performancevorteil.
Der Nachteil besteht jedoch in der eindimensionalen Purge Logik, die ausschließlich über das Packages DBMS_MGMNT erfolgen muss. Löschen via Delete ist jedenfalls nicht möglich.
Die Löschungen erfolgen entweder full oder bis zu einem vorher gesetzten Zeitstempel.
Mengenlöschungen abhängig von der Gesamtzahl der Auditdateneinträge im Unified Audit Trail sind nur mit teuren Count Operationen zu erkaufen und machen den eigentlichen Performancevorteil der Purge Routine schnell zunichte.
Folgende Löschregel ist nicht ungewöhnlich : Wenn die Anzahl der Auditdatensätze die maximal einen Tag alt sind, z.B. kleiner als 100.001 ist, dann lösche alles das älter als ein Tag ist.
Hier nochmals die Anteile einer minimalen Härtung aus Sicht des Auditing für 12c Pure Unified Auditing:
- Transform your 11g Hardening Audit Set to 12c via Create Audit Policy - if possible!
- New Privs /Actions 12c via Create Audit Policy
- Action Components
- Audit Application Contexts
- optional RAC/RAS Policies
- New Privs/Actions via Eigenbau, weil nicht direkt auditierbar!
Risiken bzgl. höherem Performance Impact 12g:
- Formulierung der Audit Policies - Anzahl
- Formulierung der Audit Policies - Bedingungen
- Formulierung der Audit Policies - Teilersatz für sys_operations =true wenn DB nicht im ' force logging' Mode
- Formulierung der Audit Policies - ohne Bedingungen - Datenredundanz
- Eigenbau für nicht direkt auditierbare Privs/Actions!
- Implizite Audit Policies von Oracle erzwungen
- Datenbank im 'force logging' Mode statt Punkt 3
Die Anteile einer minimalen Härtung aus Sicht des Auditing für 11g:
Einstellungen: DB,extended, sys_operations=true
- Hardening Audit Set via Audit
Fazit :
Wichtig ist dem Autor die Gesamtbetrachtung von Security und Performance in einem operativen System das zumindest ein Basic Hardening besitzt und einen wie auch immer abgebildeten Transportmechanismus für Auditdaten zum SIEM besitzt.
Eine einzelne Audit Policy als Indikator für den Performance Impact zu verwenden ist einfach unseriös.
Es gilt die Gesamtbelastung des Auditing inkl. Transport ( Push Verfahren ) zu ermitteln und im Konzernumfeld sind Möglichkeiten der Verteilung dieser Gesamtbelastung zusätzlich von großer Bedeutung auch wenn diese die Gesamtbelastung erhöhen.
Macht es bei bestimmten Datenbanken Sinn, teure Operationen des Auditing inkl. Transport über 24 Stunden möglichst gleich zu verteilen, gibt es andere Datenbanken, die in bestimmten Zeitfenstern größere Belastungen klaglos verkraften.
Wenn man ein Hardening bzw. Auditing Konzept zwischen 11g und 12c Pure Unified Auditing vergleicht, kann allein der
Geschwindigkeitsvorteil bei Erstellung der Aud Files / XML oder der Abtransport über syslog, besser syslog-ng, in der Gesamtbelastung für das Datenbanksystem den Performance Sieger 11g ergeben. In Audfiles zu schreiben ist weniger Ressourcenbelastend, selbst im Vergleich zu einer optimierten CLI... Table in einem Read ähnlichen Mode und direkt via syslog erst recht. Ist es da nun? Nein.
Sieht man es weniger dogmatisch und nutzt den Mixed Mode der 12c, ist nach Ansicht des Autors der Sieger in Bezug auf Security und Performance Impact eindeutig die 12c. Man kann die Vorteile beider Auditimplementierungen nutzen und so die
jeweiligen Präferenzen für Security und Performance genau in dieser Reihenfolge abbilden.
Wer den Einsatz von Auditing vorrangig vom Performance Impact abhängig macht, arbeitet letztendlich für Nachrichtendienste oder für die Konkurrenz!
Unified Auditing Oracle 12c (update 26.11.2015 )
Die neuen Möglichkeiten des Unified Auditing sind interessant, wirken jedoch leider nicht zu Ende gedacht, geschweige denn umgesetzt.
Das soll wohl auch so sein wie die erweiterten Audit Events der kostenpflichtigen AUDIT VAULT Option anschaulich dokumentieren.
Soll Unified Auditing nun ein vollständiger exklusiver Ersatz für alle bisherigen Auditoptionen sein oder nicht ?
Eher nicht, wie Oracle selbst dokumentiert.
You cannot audit the following system privileges:
- SYSASM,
- SYSBACKUP,
- SYSDBA,
- SYSDG,
- SYSKM,
- SYSOPER,
- TRANSLATE ANY SQL
- INHERIT ANY PRIVILEGES,
Die Admin Privilegien mit hunderten von Einzelprivilegien lassen sich schon mal nicht auditieren.
Zwei neue und nicht unkritische Funktionalitäten lassen sich ebenfalls nicht audititieren, jedenfalls nicht im Sinne von USE.
Audit insert, update, delete on sys.aud$ by access;
funktioniert dies bei der/den Tabellen hinter der View Unified_Audit_Trail in beiden Fällen nicht.
Die Audittabelle des Unified Auditing ist ja auch vom Typ Read-Only, jedenfalls für fast alle.
Weiterhin sind die altbekannten SQL-Shortcuts
- Audit role
- Audit profile
- Audit database link
nicht so über Audit Policies abbildbar, auch nicht wenn der Mixed Mode aktiv ist.
SQL-Shortcuts sind in diesem Kontext Gruppierungen von Privilegien.
Das bedeutet, man wird zu einer gewissen Geschwätzigkeit in der Formulierung der Policies gezwungen.
So kann man zwar jede dieser SQL-Shortcuts der alten Audit Statement Konvention in eine Audit Policy transformieren, doch verkehrt sich hier nicht nur der Parsing und Memory Overhead nach ersten Tests in einen Performancenachteil statt einem theoretischen Performancevorteil, es sein denn, man nutzt einen Cachingmechanismus der eine gewisse Anzahl von Auditdatensätzen puffert bevor diese in die Audittabelle geschrieben werden.
Ob das der Weisheit letzter Schluß ist, Auditdaten im Memory zu puffern, bezweifelt der Autor.
Auch dem Caching Effekt sind insgesamt Grenzen gesetzt wenn ab einem bestimmten Punkt die Auswertungslogik auf Lowlevel Ebene primär die CPU belastet und das Schreibproblem zweitrangig wird.
Ein Designfehler oder nur eine Frage des Umgangs ?
Pseudofeature für den Hochglanzprospekt oder in definierten Grenzen ein Fortschritt ?
Aus
Audit role;
wird mit Unified Auditing jedenfalls
CREATE AUDIT POLICY ka_role_2_4
ACTIONS
CREATE ROLE,
ALTER ROLE,
DROP ROLE,
SET ROLE;
Will man nun SYSDBA, SYSBACKUP, ... Privilegien mit Unified Auditing auditieren, bleibt einem ohne Mixed Mode nichts anderes übrig als ein Monster von Audit Policy Typ (viele) Actions zu schreiben, welche einige Hundert Privileges aus DBA_SYS_PRIVS ( DBA, SYS, <Roles>) via ACTIONS für alle Accounts mit eben SYSDBA, SYSBACKUP, ... protokolliert.
Da braucht es dann allein für diese eine Audit Policy einiges an Speicher.
Alternativ kann man gleich ACTIONS ALL für all diese Accounts als Audit Policy hinterlegen.
Für beide Varianten hat man zusätzlich die Pflege der Userlist an der Backe!
Oder man beläßt den Default Mixed Mode und sys_operations=true ist ab der Version 12c sogar die Default Einstellung.
Es drängt sich der Verdacht auf, das die Mixed Mode Default Einstellung die einzig sinnvolle Einstellung ist.
Warum ?
Viele kleine Audit Policies mit einem funktional begrenzten Laufstall klingen zwar gut, können aber durch die Auswertungsoverhead, hier jetzt auf Lowlevel Ebene, eine Datenbank gehörig belasten.
Zwei extreme und bewußt überzogene Ansätze :
Man schreibt viele feingranulare Audit Policies welche die aufkommende Auditdatenmenge die letztendlich in eine Audittabelle geschrieben werden muss, so gering wie möglich hält und zahlt dies mit teils komplexen Auswertungsregeln zur Laufzeit der Datenbank.
Oder man protokolliert vereinfacht gesagt nahezu alles mit und schreibt diese Massendaten ohne den Low-Level Auswertungsaufwand in die Tabelle. Anschließend filtert und aggregiert man die Massendaten bevor es Richtung SIEM geht.
Bei dem ersten Ansatz kommt man wie McAfee/Intel mit seinem Activity Monitoring Tool irgendwann immer in ein Zeitproblem.
Ein theoretisches Feature das an den Sportwagen mit 500 PS erinnert der durch hunderte von Sicherheitsfunktionen die Nennleistung praktisch nie auf die Straße bekommt und effektiv ein 200PS Auto mit 1,8 to ist.
Der zweite Ansatz muss bei den heutigen Techniken der SAN's mit Caches samt Virtualisierung nicht der Schlechteste sein.
Der Autor hätte sich eine eigene optionale Datenbankblockstruktur für Read Only Tabellen gewünscht, die den gesamten Transaktionsoverhead herausläßt.
Eine Partitioned Read-Only Tabelle bei der lediglich eine aktive Partition Parallel Stream orientierte Schreibvorgänge in eine extrem performante Datenbankblockstruktur zulässt. Dies natürlich nur für den Auditmechanismus.
Wenn man jetzt noch den Multitenant Ansatz hinzunimmt und man 90% seiner Auditpolicies auf CDB$ROOT verlagert und sich nicht in feingranularen Policies verliert, den Mixed Mode schön beläßt, kommt man einer sinnvollen Architektur ein wenig näher.
Die Frage stellt sich nun, warum es das Unified Auditing eigentlich gibt ?
Der Name sagt es. Es geht um die Vereinheitlichung der Datentöpfe in die Auditdaten geschrieben werden und das ist für sich betrachtet durchaus ein Fortschritt.
Die Audit Policies sind ein Beiwerk, quasi die Verpackung, von der sich natürlich alle ernsthaften Sicherheitsfachleute magisch angezogen fühlen.
Knackpunkt ist allerdings die einfache Übernahme der AUD Files in das Unified Audit Trail.
Diese Vereinheitlichung ist Gold wert. Das kann jeder nachvollziehen der sich über die Jahre mit den verschiedenen Formaten der
AUD Files samt Transaktionsverhalten (APPEND) näher beschäftigt hat.
Hat man den Mixed Mode aktiviert und stellt sicher, das sys_operations=true bleibt, werden
die AUD Files Inhalte in das UNIFIED AUDIT TRAIL mit
übertragen.Die erfolgreich übertragenen 'AUD' Files sollen anschließend implizit gelöscht werden. Letzteres kann der Autor auf der aktuellen Oracle Developer VM 12c leider nicht bestätigen. - November 2015EXEC DBMS_AUDIT_MGMT.LOAD_UNIFIED_AUDIT_FILES;
Sind nun alle Auditeinträge der AUD Files mit derart wenig Aufwand im Unified Audit Trail, können mit Filtern bzw. Aggregaten nicht nur diese Anteile der Auditdaten konsolidiert, sprich minimiert werden, bevor diese an das SIEM versendet werden.
Ein Balancing zwischen OLD Auditing und NEW Unified Auditing wird zudem ermöglicht, bevor die eine oder andere 12c Installation zu stark durch das Auditing insgesamt belastet wird.
Man bedenke, das umsichtige DBA's mit der 12c nicht direkt auf Multitenant gehen werden.
Dies ist allerdings nach ersten Tests für Unified Auditing die denkbar ungünstigste Variante aus Sicht der Last/Performance.
Wenn irgendwann Multitenant tatsächlich Einzug in die Firmen hält, ist ein Verlagerung des Auditing Overhead durch die
konsequente einheitliche Nutzung über CDB$ROOT möglich und verspricht tatsächlich eine deutliche Entlastung der PDB's.
Das alles heißt übersetzt : Nutzt den Mixed Mode und Ihre habt bis auf sys.aud$ eine Auditdatentabelle/View nämlich Unified Audit Trail. Idealerweise im Multitentant Mode mit mehr als einer PDB!
Falls Ihr ohne klassische Audit Statements auskommen könnt, gibt es keinen Aufwand zur die Pflege der sys.aud$ im Kontext SIEM.
Einen bedeutenden Nachteil hat allerdings auch der Mixed Mode:
Es existiert keine Querverbindungen zwischen beiden Auditmechanismen.
Etwas wie
CREATE AUDIT POLICY ka_role_classic_2_4
PRIVILEGES ROLE;CREATE AUDIT POLICY ka_role_classic_2_4
ACTIONS ALL FOR ROLE;
funktioniert leider nicht.
Sinngemäß wäre dies ein 'Audit Role' im Audit Policy Wrapper.
Neben dem erwähnten Performancevorteil wären die Auditdaten auch gleich im richtigen Topf, nämlich dem Unified Audit Trail.
Der Parser der Create Audit Policy Funktion ist übrigens ziemlich tolerant und erkennt mitunter nicht den eigentlichen Scope durch den nachgeschalteten Freischaltungsschritt. Andererseits lässt er Dinge durchgehen die nicht funktionieren.
CREATE AUDIT POLICY KA_AUD$_2_4
ACTIONS ALL ON SYS.AUD$;
AUDIT POLICY KA_AUD$_2_4;
Wenn wir schon bei Parsern sind und das Caching noch mit einbeziehen, kann folgender Test überraschende Ergebnisse liefern:
Eine Audit Policy wurde deaktiviert. Testschema ohne Reconnect im SQL-Developer mit Befehl der die nun deaktivierte Audit Policy betrifft.
Wer jemals Hot Cache Implementierungen geschrieben hat, erkennt in vielen Programmen eine Kraut und Rüben Architektur
nur durch die Nutzung derselben z.B. SQL Developer.
Von einem Unified Auditing hätte man eigentlich ein Package erwarten können, das Auditdaten aus PL/SQL und SQL in das Unified Audit Trail umleitet, doch dieses Manko kann, wie wir noch sehen werden, mit einem simplen Eingriff ausgeglichen werden.
Weiter mit dem Konzept von Unified Auditing
Schlimm wird es wenn bestimmte Privilegien überhaupt nicht auditierbar sind, oder um es genau zu formulieren:
Die Erkennung der Verwendung des Privilegs ist in potentiell vorhandenen Auditdatensätzen ohne Zusatzmaßnahmen nicht möglich.
Das gilt für z.B.
- INHERIT ANY PRIVILEGES,
- TRANSLATE ANY SQL
sowie für erzeugte Fehler durch 'sys as sysdba', 'sysbackup' usw.
Für die Fehler bleibt nur ein After Error Trigger auf Datenbankebene übrig.
Bei den beiden neuen Privilegien Inherit any Privileges und Translate any SQL ist es ohne eigene Compliance/Logik nur schwer möglich, die Nutzung zu erkennen und direkt auditieren kann man, wie Oracle selbst einräumt, diese nicht.
Oracle lernt bezgl. der Balance zwischen Funktionalität und Sicherheit offenbar nur sehr langsam.
Bei 'Inherit any Privileges' ist zudem der implizite Grant an Public zu überdenken.
Sicherer ist eine Whitelist von Trusted Usern.
Die eigentliche Nutzung des Privilegs ist damit aber auch nicht auditierbar.
Bei 'Translate any SQL' überkommt einen gar das Gefühl es mit einer eingebauten Backdoor zu tun zu haben.
Ein derart tief angesetzter Hook, der auch mit Audit Policies keinerlei Aufschluss über die Nutzung des Privilegs
gibt, ist schon heftig.
Für die beiden neuen Privilegien werden Lösungen zur Auditierung in einem eigenen Artikel erörtert.
Weiterhin sind in den Audit Policies keinerlei SYS EVENTS direkt abfragbar.
Ein entscheidender Nachteil.
Daraus folgt i.d.R die Nutzung von Triggern auf Datenbankebene.
DDL/DCL System Trigger auf Datenbankebene können bei der Auditierung unbedingt notwendig bis sinnvoll sein.
Rein protokollierend als Afer DDL/DCL Trigger oder blockierend als Before DDL/DCL Trigger.
Letztere Variante besitzt neben dem Protokollanteil eine aktive Komponente.
Wird die Security Compliance eingehalten geht der Befehl durch, ansonsten wird geblockt.
'Grant dba to hacker' könnte ein Beispiel sein oder die Erstellung von Usern,
die eines der hoffentlich 'ungefakten' Standardprofile zugeordnet bekommen müssen. Falls nicht, wird es diese User nie geben.
Oracle hat in der Datenbank 12c übrigens einen Grant Trigger auf Datenbankebene implementiert.
Mit solch einem Before Grant oder Before DDL/DCL Trigger könnte man übrigens vielen Exploits der Showtruppe, die aus einigen Researchern besteht, einfach einen Riegel vorschieben. Diese Leute könnten sich dann endlich den weniger spektakulären Angriffen aus dem regulär privilegierten Umfeld widmen. Genau diese Angriffe aus dem Innern von regulären Usern, dürften nach Schätzung des Autors den Löwenanteil aller Angriffe aus Sicht der Kosten/Schäden ausmachen.
Ein After Error Systemtrigger auf Datenbankebene ist ebenfalls dringend zu empfehlen.
Man sieht damit welche Qualität Anwendungen hinsichtlich Exceptions besitzen und viele Angriffsmuster erzeugen Fehler
die i.d.R. nicht abgefangen werden.
Mit folgender Audit Policy könnte man formal den Errortrigger nachbauen:
AUDIT POLICY KA_SEC_ERRORS_1_3 ACTIONS ALL;
AUDIT POLICY KA_SEC_ERRORS_1_3 whenever not successful;
Wer jetzt meint, dies wäre identisch mit einem After Error Systemtrigger, der irrt.
Versuchen Sie mal einen Fehler als 'sys as sysdba' oder 'sysbackup' zu erzeugen und Sie werden diesen lediglich in der
Tabelle des After Error Systemtrigger finden und nicht im Unified_Audit_Trail.
Warum Oracle derart grundlegende Funktionaltäten aus dem neuen Auditing ausblendet, ist vielfach interpretierbar.
Gerade DBA's stehen bedingt durch die Privilegienfülle, berechtigt oder nicht, praktisch immer im Fokus.
Klevere DBA's wünschen sich zumindest in Europa eine lückenlose Protokollierung ihrer Tätigkeiten damit sie jederzeit nachweisen können, das sie bei einem Sicherheitsvorfall eben nicht direkt aktiv waren. Mit dem Event-Actor Prinzip sollte dies in auch in Europa möglich sein. Indirekt beteiligt können DBA's zwar immer noch an Angriffen sein, doch dies ist eine andere Geschichte.
Bleibt wie oben schon erwähnt eben die Empfehlung eines After Error Trigger.
Dort hat man es allerdings wieder mit vergleichsweise großen Datenmengen zu tun und sollte das Thema Filter
evtl auch vor der Versendung an das SIEM näher beleuchten.
Ein After ( succesful) Logon Trigger ist für sich betrachtet durchaus über Audit Policies abbildbar.
Wenn man allerdings den Last Login Timestamp normaler User ermitteln möchte oder die bewußte
Nichtprotokollierung des Last login normaler User, kommt man um einen After Logon Trigger
nicht herum.Die lückenlosen Logins aller Admin User funktionieren natürlich auch mit einem After Logon Trigger.
Für den erfolglosen Login schreibt man dann noch eine Audit Policy.
Wenn man nun diverse SYS EVENTS samt zugehörigen Triggern einsetzt,
entsteht folgender Overhead im Scope Auditdatentransport zu einem SIEM :
- Jeder Trigger enthält nativ den PLSQL/JAVA Code und eben keine eigenen Prozedure Calls um Abhängigkeiten zu vermeiden.Vorsicht besonders beim After Logon Trigger!
- Jeder Trigger schreibt seine Erkenntnisse üblicherweise in eine (eigene) Tabelle.
- Jeder Trigger läuft durch diese DML Operation üblicherweise unter dem Pragma Autonomous.
- Im Exceptionhandler wird ein Rollback abgesetzt und zur Sicherheit ein Eintrag ins Alert.log
über sys.dbms_system.ksdwrt( 3, bla bla) geschrieben.
Nun entstehen so meist allerhand Tabellen und der individuelle Transport zum SIEM ( pro Tabelle ) und die anschließende Teillöschung der Tabellen muss geregelt werden.
Wie wäre es, diese Auditdaten der diversen Audit-Triggertabellen ins Unified Audit Trail umzuleiten.
Der Clou wäre, im Erfolgsfall den Auditdatensatz nicht redundant in die Triggertabelle zu schreiben.
Wenn das Schreiben ins das Unified Audit Trail nicht möglich ist, wird versucht zumindest in das Alert.log
zu schreiben.
So ein Trigger sieht etwa so aus:
Event : After Error
Scope : Database
Filter sind optional und werden dringend empfohlen.
create or replace TRIGGER secmon_after_error_trg
AFTER SERVERERROR ON DATABASE
--
-- Revision $_KA_D
--
DECLARE
PRAGMA AUTONOMOUS_TRANSACTION;
sql_text ORA_NAME_LIST_T;
v_stmt CLOB; -- SQL statement causing the problem
n NUMBER; -- number of junks for constructing the sql statement causing the error
v_program VARCHAR2(64);
v_serial number;
v_sid number;
v_stuck number;
v_flag number;
v_msg varchar2(32767);
cursor c1 is
select filter_logic, filter_regexp
from secmon.cfg_filter
where filter_object = 'ORAERROR'
order by filter_logic desc;
BEGIN
--
-- Skip everything in case of an archiver stuck
--
select count(*) into v_stuck from v_$archive_dest where destination is not null and status = 'ERROR';
IF (v_stuck > 0)
THEN
NULL;
ELSE
select program,serial#,sid into v_program,v_serial,v_sid from gv_$session where sid=sys_context('USERENV', 'SID');
n := ora_sql_txt(sql_text);
IF n >= 1
THEN
FOR i IN 1..n LOOP
v_stmt := v_stmt || sql_text(i);
END LOOP;
END IF;
for n in 1..ora_server_error_depth loop
-- default - all errors will be logged
v_flag := 0;
for irec in C1 loop
if irec.filter_logic = 'BLACK' then
if regexp_like(sys_context('USERENV','OS_USER') || '~' ||
sys_context('USERENV','SESSION_USER') || '~' ||
sys_context('USERENV','HOST') || '~' ||
sys_context('USERENV','TERMINAL') || '~' ||
v_program || '~' ||
sys_context('USERENV','IP_ADDRESS') || '~' ||
to_char(ora_server_error(n)), irec.filter_regexp, 'i')
then
v_flag := 1;
exit;
end if;
end if;
end loop;
if v_flag = 0 then
insert into secmon.oraerror
(
id,
log_date,
os_user,
session_user,
isdba,
instance_nr,
host,
terminal,
program,
client_ip,
serial#,
sid,
scn,
err_nr,
err_msg,
sql_text,
err_cnt,
err_min_log_date
) values
(
secmon.secerror_seq.nextval,
current_timestamp,
sys_context('USERENV','OS_USER'),
sys_context('USERENV','SESSION_USER'),
sys_context('USERENV','ISDBA'),
sys_context('USERENV','INSTANCE'),
sys_context('USERENV','HOST'),
sys_context('USERENV','TERMINAL'),
v_program,
sys_context('USERENV','IP_ADDRESS'),
v_serial,
v_sid,
sys.dbms_flashback.get_system_change_number(),
ora_server_error(n),
ora_server_error_msg(n),
v_stmt,
0,
NULL
);
end if;
end loop;
COMMIT WRITE BATCH NOWAIT;
end if;
EXCEPTION
WHEN others THEN
rollback;
sys.dbms_system.ksdwrt(3,'ORA-20100: DATABASE TRIGGER SECMON_AFTER_ERROR_TRG ERRROR !!!! '||SQLERRM );
END secmon_after_error_trg;
/
Mit ein paar kleinen Änderungen können wir die Daten in das Unfied Audit Trail umleiten.
Wir schreiben die Daten z.B. in Key/Value Manier in einen String.
v_msg := '';
v_msg := '#log_date='||current_timestamp||
'#os_user='||sys_context('USERENV','OS_USER')||
'#session_user='||sys_context('USERENV','SESSION_USER') ||
'#isdba='||sys_context('USERENV','ISDBA')||
'#instance_nr='||sys_context('USERENV','INSTANCE') ||
'#host='||sys_context('USERENV','HOST') ||
'#terminal='||sys_context('USERENV','TERMINAL')||
'#program='||v_program ||
'#client_ip='||sys_context('USERENV','IP_ADDRESS') ||
'#serial#='||v_serial ||
'#sid='|| v_sid ||
'#scn='|| sys.dbms_flashback.get_system_change_number()||
'#err_nr='||ora_server_error(n) ||
'#err_msg='||ora_server_error_msg(n) ||
'#sql_text='||v_stmt ||
'#err_cnt='||0 ||
'#err_min_log_date='||NULL;
Diesen String fügen wird in den Original Insert ein.
Die Stelle ist eigentlich egal. Wenn man Memory Exceptions miteinkalkuliert, dann vielleicht eher am Anfang.
Die Oracle DB ist in C/C++ geschrieben und PL/SQL ist eigentlich nur ein Wrapper.
...
if v_flag = 0 then
insert into secmon.oraerror
(
id,
log_date,
os_user,
session_user,
isdba,
instance_nr,
host,
terminal,
program,
client_ip,
serial#,
sid,
scn,
err_nr,
err_msg,
sql_text,
err_cnt,
err_min_log_date
) values
(
secmon.secerror_seq.nextval,
current_timestamp,
sys_context('USERENV','OS_USER'),
sys_context('USERENV','SESSION_USER'),
sys_context('USERENV','ISDBA'),
sys_context('USERENV','INSTANCE'),
sys_context('USERENV','HOST'),
sys_context('USERENV','TERMINAL'),
v_program,
sys_context('USERENV','IP_ADDRESS'),
v_serial,
v_sid,
sys.dbms_flashback.get_system_change_number(),
ora_server_error(n),
ora_server_error_msg(n),
v_msg||' END OF KEY VALUE#ORIGINAL SQL_TEXT='||v_stmt,
0,
NULL
);
end if;
...
Dann müssen wir noch den COMMIT WRITE BATCH NOWAIT direkt hinter dem Insert enfernen
und gegen ein Rollback austauschen.
rollback;
Der Knackpunkt kommt jetzt:
Wir schreiben eine Audit Policy für Insert Statements auf unsere Triggertabelle.
Create Audit Policy ka_audit_help_fcts_1_4
ACTIONS INSERT ON SECMON.ORAERROR;
Und aktivieren das gute Stück.
Audit Policy ka_audit_help_fcts_1_4
Ein Fehler provoziert man schnell:
Select * from ka.rally_cars;
ORA-904 ...
Was passiert jetzt :
Der Errortrigger springt an und setzt einen Insert Statement ab.
In dem Insert Statement wird an der Stelle SQL_Text der komplette Datensatz als Key/Value übergeben
inklusive dem SQL_TEXT der den Error verursachte.
Die Audit Policy springt an und protokolliert das Insert Statements auch wenn es im Normalfall mit Rollback
zurückgefahren wird.
Interessant ist, das für ein tatsächliches Schreiben bei Autonomen Transaktionen ein Commit notwendig ist.
Das Absetzen des Insert-Statements scheint hingegen für sich betrachtet schon hinreichend für die Auslösung der Audit Policy Events zu sein. Das Rollback kann dies nun auch nicht mehr ungeschehen machen.
Aus Sicherheitgründen ist die Protokollierung des Versuchs eines Inserts durchaus sinnvoll und zeigt uns die implizite Wirksamkeit der Beispiel Audit Policy, nämlich whenever successful + whenever not successful.
Da es sich hierbei intern um ein Bind Aktion handelt, sind die Daten im Feld SQL_BINDS des Unified Audit Trail direkt auslesbar.
Man kann dies als Nested Insert vorstellen.
Im Normalfall gibt es keinen Entrag in der Tabelle des After Error Trigger, eben durch die Rollback Anweisung.
Wenn es knallt, wird minimal ein Eintrag in das Alert.log geschrieben.
Dies könnte man dahingehend erweitern, als man prüft, ob der Key Value Sting valide ist, und diesen
ebenfalls in das Alert.log schreibt.
Letzter Schritt ist das Auslesen dieser Nested Auditdateneinträge (SQL_BINDS) und daraus logisch einen formalen Auditdatensatz bzw. eine Message gemäß Format für das SIEM zu erzeugen.
Kein Hexenwerk.
Damit hat man ein Muster, um ein umfassendes Unfied Auditing zu implementieren.
Abschließend könnte der Trigger dann etwa so aussehen :
create or replace TRIGGER secmon_after_error_trg
AFTER SERVERERROR ON DATABASE
--
-- Revision $_KA_D
--
DECLARE
PRAGMA AUTONOMOUS_TRANSACTION;
sql_text ORA_NAME_LIST_T;
v_stmt CLOB; -- SQL statement causing the problem
n NUMBER; -- number of junks for constructing the sql statement causing the error
v_program VARCHAR2(64);
v_serial number;
v_sid number;
v_stuck number;
v_flag number;
v_msg varchar2(32767);
cursor c1 is
select filter_logic, filter_regexp
from secmon.cfg_filter
where filter_object = 'ORAERROR'
order by filter_logic desc;
BEGIN
--
-- Skip everything in case of an archiver stuck
--
select count(*) into v_stuck from v_$archive_dest where destination is not null and status = 'ERROR';
IF (v_stuck > 0)
THEN
NULL;
ELSE
select program,serial#,sid into v_program,v_serial,v_sid from gv_$session where sid=sys_context('USERENV', 'SID');
n := ora_sql_txt(sql_text);
IF n >= 1
THEN
FOR i IN 1..n LOOP
v_stmt := v_stmt || sql_text(i);
END LOOP;
END IF;
for n in 1..ora_server_error_depth loop
-- default - all errors will be logged
v_flag := 0;
for irec in C1 loop
if irec.filter_logic = 'BLACK' then
if regexp_like(sys_context('USERENV','OS_USER') || '~' ||
sys_context('USERENV','SESSION_USER') || '~' ||
sys_context('USERENV','HOST') || '~' ||
sys_context('USERENV','TERMINAL') || '~' ||
v_program || '~' ||
sys_context('USERENV','IP_ADDRESS') || '~' ||
to_char(ora_server_error(n)), irec.filter_regexp, 'i')
then
v_flag := 1;
exit;
end if;
end if;
end loop;
v_msg := '';
v_msg := '#log_date='||current_timestamp||
'#os_user='||sys_context('USERENV','OS_USER')||
'#session_user='||sys_context('USERENV','SESSION_USER') ||
'#isdba='||sys_context('USERENV','ISDBA')||
'#instance_nr='||sys_context('USERENV','INSTANCE') ||
'#host='||sys_context('USERENV','HOST') ||
'#terminal='||sys_context('USERENV','TERMINAL')||
'#program='||v_program ||
'#client_ip='||sys_context('USERENV','IP_ADDRESS') ||
'#serial#='||v_serial ||
'#sid='|| v_sid ||
'#scn='|| sys.dbms_flashback.get_system_change_number()||
'#err_nr='||ora_server_error(n) ||
'#err_msg='||ora_server_error_msg(n) ||
'#sql_text='||v_stmt ||
'#err_cnt='||0 ||
'#err_min_log_date='||NULL;
if v_flag = 0 then
insert into secmon.oraerror
(
id,
log_date,
os_user,
session_user,
isdba,
instance_nr,
host,
terminal,
program,
client_ip,
serial#,
sid,
scn,
err_nr,
err_msg,
sql_text,
err_cnt,
err_min_log_date
) values
(
secmon.secerror_seq.nextval,
current_timestamp,
sys_context('USERENV','OS_USER'),
sys_context('USERENV','SESSION_USER'),
sys_context('USERENV','ISDBA'),
sys_context('USERENV','INSTANCE'),
sys_context('USERENV','HOST'),
sys_context('USERENV','TERMINAL'),
v_program,
sys_context('USERENV','IP_ADDRESS'),
v_serial,
v_sid,
sys.dbms_flashback.get_system_change_number(),
ora_server_error(n),
ora_server_error_msg(n),
v_msg||' END OF KEY VALUE#ORIGINAL SQL_TEXT='||v_stmt,
0,
NULL
);
end if;
end loop;
rollback;
end if;
EXCEPTION
WHEN others THEN
rollback;
sys.dbms_system.ksdwrt(3,'ORA-20100: DATABASE TRIGGER SECMON_AFTER_ERROR_TRG ERRROR !!!! '||SQLERRM||'#'||nvl(v_msg,'No Key/Value Data' );
END secmon_after_error_trg;
/
Den vollständigen Insert samt COMMIT in den Exception Handler zu kopieren, kann theoretisch Sinn machen.
Praktisch wird es, wenn es knallt, zu mindestens 90% an der Triggertabelle liegen. Wenn das Unified Audit Trail Probleme bereitet, tangiert dies unseren Trigger nicht, da dies eine eigene asynchrone Transaktion ist.
Wer auf Nummer sicher gehen will, z.B. bei hochkritischen Datenbanken, der kann den Redundanz-Ansatz fahren.
Stufe 1:
- Immer ins Unified Audit Trail umleiten
- immer ins Alert.log schreiben. Standardcode+Exception Handler
Stufe 2:
- Immer in die Triggertabelle schreiben
- Immer ins Unified Audit Trail umleiten
- immer ins Alert.log schreiben. Standardcode+Exception Handler
Zyklische Konsistenzcheck's zwischen allen 2 oder 3 Datenbasen lassen Manipulationen der Auditdaten
recht einfach erkennen. Der Angreifer muss sich schon auskennen, und wenn nicht, kann ihm dies zum Verhängnis werden.
Falls die Redundanz der Auditdaten in der Triggertabelle gewählt wurde, ist ein Löschen dieser Daten relativ zum erfolgreichen Transport + relativ zum erfolgreichen Konsistenzcheck notwendig. Ein simples Truncate ist nicht hinreichend.
Fazit mit Kommentar :
Da die wenigsten Firmen direkt auf Multitenant gehen werden, ist das Unified Auditing skeptisch zu betrachten.
Die Umsetzung von Unified Auditing wurde halbherzig durchgeführt. Kommerzielle Interessen von Oracle (Audit Vault ) und mutmaßliche Langzeitinteressen ( 35 Jahre+) von US-Agencies liest man regelrecht aus der Umsetzung des Unified Auditing heraus. Die partielle Ausklammerung von z.B. 'sys as sysdba' aus diversen Auditfunktionalitäten ausgenommen sys operations spricht Bände. Einen 'sys as sysdba' sollte es nicht geben!
Zudem drängt sich dem Autor die typische Situation heutiger Projektabwicklungen auf, die im Fall Unified Auditing ursprünglich wohl die Ablösung des klassischen Auditing zum Ziel hatte.
Die fehlenden Querverbindungen in der Nutzung beider Mechanismen auf rein funktionaler Ebene bestätigen dies.
Dann wurde wahrscheinlich irgendwann auf die Vereinheitlichung der Audittabellen reduziert und damit man es besser verkaufen kann wurden Audit Policies angedacht und in einer ersten Version bereitgestellt.
Dann hat es wohl mit der Performance Probleme gegeben. Stichworte : Parser und Write Overhead.
Die Idee ein Caching bei Auditdatensätzen einzuführen stellt sich aus Sicht des Autors als ein letzter Rettungsring dar.
Dieser Rettungsring wird, Glück muss man haben, auch noch als Performancebooster verkauft. In-Memory war eben in!
Zum Schluß hat wahrscheinlich irgendein Manager festgelegt das Oracle 12c per Default im Mixed Mode läuft.
Eine sinnvolle Entscheidung!
p.s. Wenn Oracle bei aller Kritik, den einen oder anderen Vorschlag für sein Auditing adaptieren will und soetwas wie eine Anerkennung ausdrücken wollte, dann sei auf den erwähnten Sportwagen verwiesen. 1:18 wäre schon ok!
Innentäter (update 29.03.2015)
Anlaß sind die Meldungen über Kreditanträge der Firma Kreditech, welche im Netz kursieren würden.
Die Firma selbst behauptet, es sei kein Zugang von außen auf die Daten möglich und nie möglich gewesen.
Daraus folgt nach reiflicher Überlegung: Es kann sich nur um Innentäter handeln.
Über ein Caching System seien die Daten abgezogen worden. Gut möglich.
http://www.heise.de/security/meldung/Kreditantraege-von-Kreditech-kursieren-im-Netz-2584198.html
Nach Schätzungen werden 80-90% aller Angriffe auf Daten von Innentätern durchgeführt.
Zwei Themenblöcke ergeben sich hieraus aus Sicht der Data Security :
A.) Wie geht man mit Mitarbeitern um und wie schätzt man seine Kollegen ein ?
B.) Wurden uns mit In Memory Datenbanken und Megadatenbanksystemen mit zigfach verschachelten Cachingsystemen permanente Security Leaks verkauft ?
Themenblock A wurde schon vielen bekannten Experten behandelt. Die Meinung des Autors ist sehr dezidiert.
Vertrauen ist gut, Kontrolle ist besser. Die meisten Mitarbeiter sind anständig bis maximal ein wenig neugierig.
Der Rest ist faktisch kriminell.
Entscheidend ist allerdings, wie schnell heutzutage ein harmloser Mitarbeiter zum Kriminellen werden kann.
Wie ein Bit kippt, kippen heutzutage Mitarbeiter aus den unterschiedlichsten Motiven innerhalb eines Synapsensprungs.
Der Begriff des 'Schläfers', dem selbst nicht bewußt ist, das er ein 'Schläfer' ist, drängt sich dem Autor auf.
Die Gründe hierfür sind vielfältig.
Ersteinmal wird es vielen Mitarbeitern wirklich leicht gemacht Vertrauen im Hinblick auf Daten zu missbrauchen.
Hinzu kommen Egoismus, Geltungsdrang, Streben nach Anerkennung und all dies, das ist entscheidend, ohne irgendein Limit!
Je nach Charakter intelligent verdeckt bis hin zum Koch'schen Paradigma.
Dies ist ein gesellschaftliches Problem, welches eng mit unserer politischen und wirtschaftlichen Ordnung zusammenhängt.
Interessant ist die Falschbild vieler Innentäter bezgl. Entdeckung und deren Folgen. Überschätzung der eigenen Bedeutung und die Negierung altbekannter Unternehmensregeln kommen hinzu. Einige Unternehmen sind schon Konkurs gegangen, weil sie sich von Mitarbeitern getrennt haben, die gegen Unternehmensgrundsätze verstoßen haben.
Der Rausschmiss erfolgt bei rein persönlichen Bereicherungen praktisch immer.
Ein subjektives Resumee :
Zusammenfassend und stark vereinfacht wird nicht nur in Deutschland ein Volk von Superegoisten herangezüchtet, die jeweils, das ist der Unterschied, auf ihren Einsatz warten.
Das ist leider eine schöne Vorlage für Innenminister und ihre Geheimdienste.
Wie geht man nun mit den Mitarbeitern um ?
Da seltsamerweise sensible Daten häufig in Brot und Butter Datenbanken zu finden sind, helfen psychologische Tricks nichts, solange die Trennung der Daten zugriffstechnisch und physisch nicht erfolgt ist.
Konkret könnte man bei unverfänglichen Daten, die separiert abgelegt werden, ( eigene Instanz/DB/...) den Begriff Vertrauen partiell wieder einführen.
Viele Firmen stellen sich hier in ihrer Art der Datenhaltung allerdings selbst ein Bein bzw. gehen mit ihren Daten so um wie z.B. ein Bastler mit Abstellplatz in seiner Garage. Teile und herrsche ist somit der zweite altbekannte Spruch, der dringenst Anwendung finden sollte.Solange dies nicht umgesetzt wird, bleibt leider nur der Generalverdacht.
Das dies ein unmöglicher Zustand ist, wird jeder Einsehen, der die Nähe zur Argumentation von Innenministerien und Geheimdiensten erkennt, die uns alle generell unter Verdacht stellen und uns Tag und Nacht überwachen bzw. ausspionieren.
Bringt man Mitarbeiter nicht in Versuchung, kann man ihnen eher vertrauen. Ein überschaubarer Kreis von Mitarbeitern darf mit kritischen Daten umgehen wobei hier die vollständige Zugriffskontrolle z.B. via Logging in dem Pflichtenheft stehen sollte.
Themenblock B behandelt die Gefahr von gigantischen Cachingsystemem ( z.B. SGA von Oracle ) und In Memory Datenbanken allgemein.
Nein, der Autor glaubt nicht, das diese Techniken nur entwickelt wurden, um mehr oder minder intelligenten Database Security Maßnahmen auszutricksen. Dies natürlich unter dem Deckmantel der Performance.
Auch glaubt der Autor nicht, das ein ominöser Masterplan den Big Data Hype als Resteverwertung der Geheimdienstauswertungen in der zivilen Wirtschaft implementiert hat, um den Bedarf an Auswertungen bis runter auf eine Person im Zeitfenster Samstags 12:00- 13:15 überhaupt erst zu wecken. Obwohl, so ganz auschließen kann man es auch nicht;-)
Interessant ist, das bei nüchterner Betrachung von vielen Big Data Auswertungen wieder der Faktor Neugierde auftaucht.
Da wird ausgwertet, was das Zeug hält. Ob es der eigenen Firma einen Nutzen bringt, sei mitunter dahingestellt.
Das auch hier zwischen Neugierde und krimineller Enegie nur Nuancen liegen, dürfte jeder schon selbst an sich beobachtet haben.
Wie schon im Themenblock oben, empfielt der Autor wieder die Trennung der Daten, nicht nur logisch sondern physisch.
Eigene Oracle Instanzen oder besser physikalisch separate MS SQL Datenbanken mit kritischen Daten und andere Instanzen ( z.B.NO SQL ) für weniger kritische Daten.
Je kritischer die Daten, umso mehr Aufwand sollte betrieben werden um die direkte Anbindung an Internet und Intranet zu vermeiden.
Eigenentwickelte sichere Cachingsysteme zur vollständigen Kontrolle sind ein Ansatz wenn es denn ohne Intranet und Internet nicht geht.
Nun wird es richtig technisch.
Performance in Datenbanken kann je nach Paranoiafaktor als trojanisches Pferd angesehen werden.
Caching von SQL Statements, Zugriffsplänen, deren Resultsets usw. und von In Memory Datenbanken ganz zu schweigen.
Performance Monitoring, Debugging von Datenbankanwendungen, Betriebssystemroutinen, usw.,- all das sind sind potentielle Angriffe auf kritische Daten die in irgendwelchen Speicherbausteinen ihr Dasein mehr oder minder lang fristen.
Für Non In Memory Datenbanken muss die Entscheidung zwischen Security oder Performance als führendes Ziel fallen.
Maßnahmen wie sich selbstzerstörende PLSQL Routinen wurden in einem Artikel auf dieser Seite beschrieben. Flushing weiterer Cachingsbereiche ist nicht trivial, bezogen auf die Verweildauer der Daten in Cachingsystemen umsetzbar. Forcieren von diversen Algorithmen wie LRU, Garbage Collection usw. mit eingehergehendem Sizing der jeweiligen Memory Bereiche stellen die klassische Performance Arbeit praktisch auf den Kopf, bringen jedoch einen deutlichen Schutz zumindest was die Wahrscheinlichkeit von Angriffen angeht.
Bei richtigen In Memory Datenbanken sieht es dagegen finster aus. Hier fallen dem Autor erstmal systemnahe Memory Schutz und Monitoring Funktionen ein. Spezielle Linux Varianten( open source) könnten dies umsetzen.
Weiterhin ist eine automatisierte physikalische Umschichtung von kritischen Daten per Algorithmus ein Themengebiet, das den Autor schon einige Zeit beschäftigt. Kein DBA, kein Admin, kein Wartungstechniker von SAN Systemen weiss genau, wo die kritischen Daten nun konkret liegen.Wenn man gar einen Pool von Datenbanken unterschiedlicher Hersteller definiert und z.B. ein JDBC Gateway besitzt, findet der Begriff Cloud in diesem Kontext eine treffendere Anwendung als bislang üblich.
Ganz allgemein kann die Abkehr vom überbordenden Monitoring ( Performance) hin zum modernen Logging bei vielen isolierten kritischen Datenbanken helfen, solange keine sicheren Betriebssysteme bezogen auf Memory Angriffe existieren.
Zum Schluß sei noch bemerkt, das der Autor die persönliche Bewaffnung in einer mitunter nicht ungefährlichen Welt aus Prinzip ablehnt.Bezogen auf den Datenschutz gilt genau das Gegenteil!
Über die Sinnhaftigkeit von Regelauswertungen für einzelne Datenbankstatments
Datenbankstatements werden regelbasiert überwacht und darauf basierende Events an ein SIEM weitergeleitet.
Die einfachste Lösung wäre theoretisch alle Datenbankstatements via Event an ein SIEM weiterzuleiten.
Bei Applikationsmonitoring in Datenbanken können allerdings schon mal einige Milliarden Events für 10-20 Datenbankstatements
in wenigen Wochen zusammenkommen. Wahrscheinlich kein so guter Ansatz.
Die grundsätzliche Unterscheidung von kritischen und nicht kritischen Datenbankstatements scheint ersteinmal sinnvoll.
Die Einstufung der Datenbankevents als Folge einer Einschätzung des jeweiligen Datenbankstatements auf seine Gefährlichkeit hin, ist eine Kernaufgabe von DAM Tools.
Für diese Einstufung sind allerdings Informationen notwendig. Diese vom DAM Tool bereitgestellten Informationen kann man Regelattribute nennen. Beispiele : STATEMENT, OBJECT (tabelle , ...), OSUSER, DBUSER, APPLIKATION, IP, TIMESTAMP, ...
Die Einstufungen der Events sind abhängig von der Kritikalität und erfolgen üblicherweise in Stufen wie z.B. 'info - high', manchmal auch 'critical'. Wichtig ist das dies auf Basis eines einzelnen Statements erfolgt. Die Behandlung der DAM Events erfolgen auf DAM Seite entweder vor oder nach der Ausführung des Datenbankstatements. Konkret kann ein spezielles DAM Tool einen Abbruch der Datenbanksession mit z.B. 'TERMINATE SESSION' bewirken, bevor das Statement ausgeführt wird.
Ein anderes DAM Tool kann Statements blocken, bevor diese ausgeführt werden.
Die weitere Behandlung bzw. Verarbeitung der Events wird sinnvollerweise in ein SIEM verlagert.
Ob man auf Basis eines einzelnen Statements überhaupt die Kritikalität beurteilen kann und wann man guten Gewissens automatisiert Eingriffe in ein Datenbanksystem vertreten kann und wann nicht, soll dieser Artikel beleuchten.
Kann man basierend auf einem einzelnen Datenbankstatemt einen Abbruch überhaupt ableiten oder bedarf es zusätzlicher Informationen, sprich zusätzlicher Events, seien es nun weitere Datenbankevents bzw. Events anderer Zuieferer wie OS, Network, usw. ?
In den Beispielen werden die weit verbreiteten Datenbanken des Herstellers Oracle V.9-V.11g verwendet.
Hier ein Beispiel für zwei sinnhafte Regeln, die wenig Spielraum für Interpretationen lassen.
DBA's sollen nicht auf Applikationsdaten zugreifen.
Vereinfacht bei Oracle : Alles was nicht 'SYS','SYSTEM', 'SYSAUX',... ist, ist verboten.Punkt!
Passiert es doch, soll ein Event an das SIEM weitergeleitet werden.
Nun gibt es innerhalb der Applikationsdaten besonders kritische Daten, konkret Tabellenspalten wie z.B.
Kreditkartennummer, Kontostand, Laborwerte Leber, ....
Wenn der DBA darauf zugreift soll jeweils ein eigener Event einer höheren Kategorie ausgelöst werden.
Aus beiden Regeln folgen nun streng genommen zwie Events, falls der DBA z.B. die Spalte Kontostand mit z.B. Select
abfragt. Er greift sowohl auf Applikationsdaten als auch auf mindestens eine kritische Spalte zu.
Und hier beginnt das große Durcheinander bei einigen DAM Herstellern, die sich damit brüsten exakt und schnell die jeweiligen Anforderungen abbilden zu können.
McAfee Database Activity Monitoring kann z.B. keine Tabellenspalten über Regelattribute auswerten.
Tabellen erkennen kann man über das Regelattribut 'OBJECT'.
Alternativ als Workaround könnte man das Statement auf Spaltennamen in der Regel untersuchen.
STATEMENT contains ('KONTO.KONTOSTAND','KONTO.KONTONR',... )
Große Anwendungen können schon mal einige hundert wenn nicht tausende kritische Spalten enthalten.
Praktisch ist dies wegen der Dauer der Prüfung und der Architektur des McAfee DAM Tools nicht machbar.
Wer sagt, das die Spalte im Statement direkt erkennbar ist. Alle Prozeduren, die nicht 'on the fly' erzeugt werden,
könnte man mit einem Regelobjekt hinterlegen, sofern diese Prozeduren kritische Spalten verwenden.
Bei großen Anwendungen werden diese allerdings ebenfalls sehr zahlreich auftreten und müssten einzeln verglichen werden.
Werden gar 'on the fly' Prozeduren erzeugt, wird es ganz bitter. Kann man eine Namenskonvention erkennen und zur Regelausführungszeit all die Informationen überhaupt ermitteln ?
Weiterhin werden bei McAfee DAM Tool beide Events in unseren Fallbeispiel zu einem Event zusammengefasst der die höherwertige Einstufung enthält. Zumindest werden die beiden Regeln die 'gezündet' haben ausgewiesen.
Die Folge davon ist, das ein SIEM mit ziemlich vielen höherwertigen Events geflutet werden kann.
Nach dem Motto, könnte ja sein, das es kritisch war.
Weiterhin muss das SIEM zwangsläufig die Nachverarbeitung ( Postprocessing) für die Ermittlung derjenigen Events selbst durchführen, die tatsächlich mit kritischen Spalten zu tun haben. Es muss eine Arbeit übernehmen, die der Autor vom DAM Tool erwarten würde.
Das SIEM selbst wird außerdem noch nach eingehendem Datenvolumen lizenziert.
Hier wurde offensichtlich einiges nicht zu Ende gedacht.
Aber der Reihe nach ...
Begrifflichkeiten :
Database Activity Monitoring Tools (DAM) können Datenbankstatements überwachen. Es gibt zwei grundsätzliche Methoden.
Netzwerk und Memory/Data Dictionary*. Diese können kombiniert auftreten.
Innerhalb des Memory/Data Dictionary Ansatzes gibt es mindestolge ens zwei Methoden.
- Vor der Ausführung des Datenbankstatements
- Nach der Ausführung des Datenbankstatements
Ansatz 1 :
Netzwerk ( zum Datenbankserver ):
Man sieht nicht zwangsläufig die Wahrheit.
Beispiel : Über das Netzwerk wird die Abfrage 'select * from wochentag' erkannt.
'wochentag' ist allerdings eine View auf die Tabelle 'kundenstamm'.
Diesen Ansatz als Einzigen zu verwenden, ist meiner Ansicht nach nicht zielführend.
Ansatz 2:
Memory - vor der Ausführung des Datenbankstatements.
Der Sinn ist, die Option für einen Abbruch der Datenbanksession zu erhalten.
Nachteil : Das Zeitfenster zwischen Erkennung des tatsächlichen Statements 'select * from kundenstamm' und Ausführung ist extrem kurz. Die Menge der auswertbaren Regeln und Regelattribute sind aus Zeitgründen begrenzt.
Der erste Fehler bei diesem Ansatz besteht darin, das die Menge der
Informationen für die schwerwiegende Behandlung wie den Abbruch der
Datenbanksession meist nicht vorliegt und dies architekturbedingt.
Noch schlimmer wird es, wenn dieser Ansatz der Einzige ist, der im DAM Tool implementiert wurde.
Bei jeder Regel, die nicht 'Terminate Session' als Behandlung enthält ca.99,99%, begibt man sich freiwillig in Zeitnot bzgl. Komplexität von Regelauswertungen und in eine begrenzte Sicht, nämlich auf genau ein Datenbankstatement mit begrenzten Informationen.
Beispiel eines Sicherheitsvorfalls der illegale Zugriffe auf kritische Daten nach Spaltenliste xy per Event an ein SIEM senden soll.
Illegale Zugriffe auf kritische Spalten sind etwas anderes als potentiell illegale Zugriffe auf kritische Tabellen. Macht der Begriff kritische Tabellen isoliert betrachtet überhaupt Sinn ?
Das McAfee DAMP Tool kann z.B. das Objekt über Regelattribute abfragen, etwa eine Tabelle in der kritische Spalten enthalten sind. Ob kritische Spalten im Datenbankstatement beteiligt sind, oder eben nicht, kann nicht ermittelt werden.
Nach Meinung des Autors wird dies bei diesem Ansatz nie ermittelbar sein
Ein möglicher Grund :
Zeitlich nicht machbar in der kurzen Zeit nach Erkennung des Statements und vor Ausführung des Statements.
Da übrigens nicht alle RDBMS Datenmodelle von Datenbankprofis mit relationalem Verständnis erstellt wurden, finden sich auch schon mal Tabellen mit einigen hundert Spalten samt zugehörigen Prozeduren mit entsprechend vielen Parametern.
Spalten werden mit Datensätzen verwechselt usw.
Von Nested Tables ganz zu schweigen.
Jetzt alle Zugriffe auf 'kritische Tabellen' ohne Betrachtung der Spalten per Event an ein SIEM zu liefern gleicht eher einer Flutung des SIEM mit einem hohem Potential von False Positives als einer professionellen Datenbanküberwachung.
Und warum ? Weil ein Postprocessing fehlt, bevor es in Richtung SIEM geht.
Wenn man sich nun noch vor Augen hält, das einige SIEM Hersteller die Lizenzkosten nach eingehendem Datenvolumen berechnen, kein besonders intelligenter Ansatz.
Ansatz 3:
Memory - nach der Ausführung des Datenbankstatements.
Für 99,99% der Regelauswertungen wie Behandlungen ein sinnvoller Ansatz.
Ein Postprocessing ist jederzeit möglich, da abgesehen von der Kritikalität besonderer Angriffe, keine extreme Zeitnot
besteht.
Nachteil : Der Abbruch der Datenbanksession ist zwar möglich, jedoch erst nach der Ausführung des triggernden Datenbankstatements.
Das ein Abbruch der Datenbanksession nach dem ersten Datenbankstatement bei bestimmten Angriffen durchaus Sinn machen kann, liegt auf der Hand.
Vorteil : Man kann über interne Oracle Tabellen die Anzahl der verarbeiteten Datensätze erkennen und bewerten.Bei Datenabzug und Datenmanipulationen ein nicht unwichtiger Vorteil. Teilweise sind für solche Auswertungen die AWR Tabellen notwendig, welche implizit über das Enterprise Manager Pack lizenziert sind.
Die Kombination aller drei Ansätze würde Sinn machen.
Bei einer statischen Architektur für ein DAM Tool tendiert der Autor zu Ansatz 3.
Begriffswirwarr
Wo der genaue Unterschied zwischen Database Auditing, Database Monitoring und Database Activity Monitoring (DAM) liegt, wissen vielleicht die Produktmanager. Ich kenne den Unterschied ehrlich gesagt nicht!
Gibt es passives Monitoring und wenn ja, wie unterscheidet es sich vom aktiven Monitoring ?
Der Begriff Database Activity Monitoring with Prevention, kurz DAMP, macht hingegen halbwegs Sinn.
Damit ist eine Uberwachung gemeint, die in einem extrem kurzen Zeitfenster erfolgt, in dem direkt nach Erkennung des tatsächlichen Statements und vor der Ausführung per Regel evaluiert wird, ob es samt Session abgebrochen wird oder nicht.
Uber den Sinn eines solchen Features kann man herrlich diskutieren.
Ob die Existenz eines solchen Features Grundlage fur die Gesamtarchitektur des DAM Tools sein sollte, kann hinterfragt werden.
Fakt ist, das der Autor keine produktive Installation des McAfee DAMP Produkts kennt, auf der eine Regel die Eventbehandlung 'Terminate Session' tatsächlich durchführt. Selbst dann nicht, wenn es einen der äußerst seltenen Fälle betrifft, bei der dies Sinn machen könnte.
Übrigens können Regeln leicht verändert werden, sodaß diese niemals zünden können. Dies ist allerdings ein eigenes Themengebiet.
Wie sichert man DAM Systeme selbst ab ?
Die Gründe fur die Nichtverwendung von 'Terminate Session' sind meist recht einfach :
- Wer will schon um 3:00 geweckt werden ?
- Wie hoch sind die Kosten eines Abbruchs der Datenbanksession im Verhältnis zum Nichtabbruch ?
Wie schwierig die Entscheidung für oder gegen einen automatisierten Abbruch sein kann, soll folgendes Beispiel erläutern :
Ein Tool namens Hacker.exe verbindet sich um 3:00 pm von einer hauseigenen Machine gegen die Produktionsdatenbank mit dem Privileg sysdba und führt einen Datenbankexport durch.
Viele würden sagen : Der Fall ist klar 'Terminate Session', was sonst!
Security ist meist eng mit dem Begriff Kosten verbunden.
- Was kostet Security ?
- Was kostet ein Sicherheitsvorfall ?
- Was kostet der Abbruch einer Datenbankoperation + Session inklusive der Folgen ?
Besonders interessant ist die Frage der Kosten eines Abbruchs von Datenbankstatements bzw. einer Session.
Der Abbruch einer Datenbanksession ist nicht das Stoppen einer ganzen Datenbankinstanz.
Wenn die vorgebliche Angreiferdatenbanksession kein 'False Positive' ist, sind die Kosten des Abbruchs abhängig von der Art des Angriffs, sowie von dessen Folgen z.B. in bestimmten Zeitfenstern.
Formal kommt unser Angreifer wie schon erwähnt ganz offensiv mit :
Hacker.exe um 3:00 pm von einer hauseigenen Machine. Verbindet sich gegen die Produktionsdatenbank 'Devisen_Z' mit dem Privileg sysdba und führt einen Gesamtdatenbankexport durch.
Fur die folgenden Angriffsszenarien 1 und 2 soll Hacker.exe tatsachlich ein eigenes Tool sein, das z.B. den Datenbankexport als auch beliebige Datenbankstatements absetzen kann.
Fur die beiden Angriffsszenarien 1 und 2 wird als zweiter Schritt der Versuch der Löschung der Datenbankinstanz einkalkuliert.
Angriffsszenario 1 :
Falls unser Angreifer vor dem Datenbankexport einige interne Datenbankjobs, welche z.B. das 'Auto Devisengeschäft' betreiben, solange aussetzt, bis sein Datenbankexport fertig ist und dann potentiell die Datenbank löscht, kann es günstiger sein zu terminieren.
Warum ?
Sobald die Job's für das 'Auto-Devisengeschäft' wieder eingeschaltet werden, gibt es keine Verluste.
Verluste durch einkalkuliertes Databaserecovery und der Schaden durch den Datenverlust fallen weg.
Knackpunkt : Wird erkannt, das neben dem Datenbankexport, die Jobs ausgesetzt wurden ?
Wir benötigen also mindestens zwei Regeln auf Statementebene :
- Erkennung der Jobaussetzungen
- Erkennung des Datenbankexports
Kann das jeweilige DAM Tool Regeln jeweils nur auf Statementebene anwenden, gibt es die Gesamtsicht der zwei Operationen schlichtweg nicht, jedenfalls nicht auf DAM Tool Ebene. Somit wird vielleicht jeweils ein 'High' Event an das SIEM weitergeleitet. Für das Terminieren der Datenbanksession ist es dann meist zu spät wenn diese im SIEM eintrudeln.
Angriffsszenario 2:
Zieht der Angreifer einfach nur die Daten ab, ohne Aussetzung des 'Auto Devisengeschafts', kann die Nichtterminierung günstiger sein.
Warum ?
Weil die Gewinne durch das 'Auto-Devisengeschaft' zumindest bis zum Löschen der Datenbank in dieser Zeitspanne größer sind, als die Verluste in der Zeitspanne des einkalkulierten Database Recovery in Verbindung mit dem Schaden durch den real zu erwartenden Datenverlust. Dies hängt vielleicht mit Handelsplätzen, Datendurchsatz und anderen Faktoren zusammen.
Angriffsszenario 3 :
Ein Mitarbeiter, der für einen Geheimdienst tätig ist, benennt expdp.exe in Hacker.exe um und ändert mit dem speziellen Tool seiner Wahl den Wert fur Module
als auch den des Modulhash. Die DAM-Regeln für umbenannte Executables greifen ins Leere.
Die Anwendung wird lediglich als 'unknown' erkannt, kommt allerdings von einer bekannten Maschine und der Osuser/Dbuser mit sysdba Privilegien ist auch bekannt.
Allenfalls kommt bei einem solchen Bewertung ein 'Medium' als Event heraus.
Der Datenbankexport soll übrigens eine reguläre Datensicherung sein, die um diese Zeit immer läuft, allerdings normalerweise mit einem der Tools aus (expdp.exe,exp.exe,rman.exe )
Das Löschen der Datenbank wird naturlich nicht stattfinden.
Die Kür erfolgt durch die mögliche automatische Ubernahme von 'Hacker.exe' in die Whitelist der Regelsätze bzw. Regelobjekte (expdp.exe,exp.exe,rman.exe, Hacker.exe )
In Folge kommt noch nicht mal ein 'Medium' Alert vom DAM System wenn 'Hacker.exe' aktiv wird.
Die Anwendung ist nun legalisiert und gehort zum Inventar. Unser Mitarbeiter entwickelt derweil fleißig sein neue bösartige 'Hacker.exe' fur die Varianten
1 und 2. Das Ganze nennt man Angriffsvorbereitung mit einem eingebauten Detection-Honeypot fur Securitytools.
Unabhängig von diesen Szenarien, kommt die Gefahr von False Positives hinzu.
Allein diese Betrachtung gibt einen ersten Einblick in die Komplexität von Angriffserkennungen und möglichen Reaktionen/Entscheidungen basierend auf diesen.
Selbst die vorgeblich eindeutig 'böse' Nutzung von verdächtigen Oracle Procedures/Functions z.B. des Identity Change, sollte nicht ohne Zusatzinformationen zu einem 'Terminate Session' führen. Vielleicht wurde ja ein Troubleshooter für eine wichtige Standardanwendung für zwei Tage eingekauft und dieser Mensch kommt mit einem eigenen Analysetool im Gepäck.
Er würde es nicht nutzen können.
Ist es überhaupt moglich in Datenbanksystemen vor der Ausführung von Datenbankstatements solche potentiellen Komplexitäten zu erkennen ?
Nach Meinung des Autors ist es äußerst selten möglich, ein geschlossenes eindeutiges Angriffsmuster und alle Folgen mit gängigen DAM Architekturen zu erkennen, da zu diesem Zeitpunkt die Sicht auf ein Statement bzw. eine Aktion verengt ist.
Es gibt keine ubergreifende Sicht auf andere Datenbankevents, jedenfalls nicht praktisch.
Es gibt keine übergreifende Sicht zu anderen Events von z.B. OS, Network und anderen Securitysystemen wie DLP usw.
Nimmt man neben der klassischen Statementüberwachung fur den Datenbankbetrieb noch Applikationen hinzu, wird es noch schwieriger extrem gefährliche Aktionen eindeutig zu erkennen und diese auch noch mit einem 'Terminate Session' zu behandeln. Ganz zu schweigen von der Unmöglichkeit bei bestimmten Anwendungen jedes Statement
einer bestimmten Sicherheitsklassifikation im Zuge einer Nachvollziehbarkeitspolicy zu erfassen.
Einige typische Standardanwendungen die unter Oracle laufen, erzeugen schon mal mehrere Milliarden identische Statements für (dbuser, applikation, osuser,host ) in wenigen Wochen. Das diese Massenstatements nicht selten kritische Tabellen betreffen, liegt auf der Hand.
Diese Massen von Events in einer relationalen DAM Datenbank einzeln zu speichern, um sie nach der Weiterleitung an ein SIEM gleich wieder zu löschen, hat den Sinn eines Festplattentests, nicht mehr und nicht weniger. Ok, vielleicht kann man noch einen Denial of Service daraus machen.
Wie könnten alternative Ansätze aussehen ?
- Preprocessing
- Postprocessing mit Eventaggregation
Diese nach Möglichkeit im SIEM. Realistisch ist dies allerdings nicht, da meist das Know How für die Erkennung von Datenbankangriffen auf Bais von korrelierten Einzelevents auf SIEM Ebene und nachgeschalteten Security Einheiten nicht hinreichend vorliegt.
Ein Postprocessing vor dem SIEM und hinter denjenigen DAM Tools die generell und ausschließlich Statementbasiert arbeiten, kann sinnvoll sein.
Als Beispiel für einen der seltenen Fälle, bei denen ein 'Terminate Session' sinnvoll sein kann, soll die berühmte Datenbank eines Herstellers von schwarzer Brause dienen.
Wie sich das schwarze Gebräu zusammensetzt ist ein Betriebsgeheimnis und dies gilt es zu schützen.
Operativ werden allenfalls ein oder zwei Personen auf diese Datenbank lesend und schreibend zugreifen dürfen.
Dies mit etlichen Sicherheitsvorkehrungen. Falls nur eine Regel für all die Sicherungen nun verletzt würde, kann ein 'Terminate Session' durchaus Sinn machen, falls die Produktion läuft. Wenn die Maschinen für die Gebräu Zusammensetzung aus irgendeinem Grund abgestürzt sind und ohne Daten sind, wird selbst aus dieser 'Tresordatenbank' eine operative Datenbank, zumindest kurzzeitig. Und schon wäre das 'Terminate Session' zu brachial sprich zu teuer.
Fazit :
Eine sinnvolle und flexible Architektur fur ein Database Activity Monitoring Tool zu entwerfen, ist nicht trivial.
Schade ist, das einige Hersteller von existierenden DAM Tools Schwächen in deren Architektur bei Präsentation und spätestens beim Verkauf nicht aufzeigen. Dies gilt besonders beim Einsatz solcher Tools in der Fläche und bei einem Nachvollziehbarkeitsanspruch aller Datenbankstatements bestimmter Kritikalitätsklassen.
Tipps :
Interessenten für DAM Tools sollten Sie sich nicht mit Trivialbeispielen bei der Präsentation und den ersten POC's zufrieden geben. Messen Sie bei einem POC mal die Systembelastung verursacht durch eine 'Catch All' Regel auf einem Produktivsystem, welches Hot Standby abgesichert ist. Einmal mit Speicherung der Events auf Logfile Ebene und evtl. einmal mit der Speicherung der Events im DAM-RDBMS. Prüfen Sie, ob mit den vorhandenen Regelattributen der geforderte Grad an Granularität überhaupt abgebildet werden kann und wenn ja mit welchen Kosten. Gibt es ein Postprocessing als Feature des DAM Tools oder müssen Sie es selbst realisieren ? Ist die Wartung und Pflege bei hunderten oder gar tausenden von Regeln über alle Ihre Datenbanken mit dem DAM Tool überhaupt möglich ? Erfolgt die Speicherung derDatenbankenevents in einer DAM Datenbank und wie lange werden diese Events dort gespeichert ?
Generell kann der OODA Loop Ansatz auf alle Database Security Monitoring Processes and Tools angewendet werden.
https://www.schneier.com/blog/archives/2014/11/the_future_of_i.html
Warum man einen theoretischen Spezialfall wie 'Terminate Session' zum Standardkonstruktionssprinzip eines DAM Tools ernennt und sich bei den Regelauswertungen generell und freiwillig in zeitliche Not begibt, ist für den Autor nicht nachvollziehbar.
'Terminate Session' vor der Datenbankstatementausführung basierend auf der eingeschränkten Sicht auf exakt ein Statement, ist bei näherer Betrachtung ein theoretisches Feature und nach Meinung des Autors noch dazu an der falschen Stelle.**
* Bei Oracle werden bestimmte interne Datenbankinformationen vom Memory auf Tabellen eines speziellen Typs abgebildet.
** Ein zugegebenermaßen drastischer Vergleich ist die nachweislich in Florida erfolgte Tötung eines harmlosen Jugendlichen, der zufällig ein Kapuzenshirt trug, welches bei angstbefallenen und daher bewaffneten Anwohnern eines Gründstückes als Synonym für eine gefährliche Gang galt. Auslöser für die Erschießung des Jugendlichen durch den Grundstücksbesitzer war, das der Jugendliche in Ermangelung eines Gehweges am Grundstück des Anwohners über den Rand des Grünstreifens entlanglief und damit formal auf dem Grundstück.
Database Activity Monitoring - Hightech im Namen - das reicht ! (new 06.06.2014)
Von einem bekannten Sportartikel Hersteller hieß es jahrelang, er verkaufe hauptsächlich Luft oder besser "AIR".
Die Luft wurde noch dazu mit Nummern versehen, damit es etwas hermacht z.B. "AIR 180".
So mancher Hersteller von DAM Software verkauft zwar keine Luft, doch sind einige Architekturen dieser Tools oft nur ein Pseudoschutz.
Der Gedanke von der Verwaltung von Teilmengen von Security Leaks zwängt sich dem Autor bei mancher Tool-Suite auf.
Oder etwas plakativ :
Der Deutsche neigt zur Verwaltung und der Amerikaner hat's gemerkt.
Warum bestimmte Architekturen im Bereich DAM nur geringen praktischen Schutz bieten, wird im folgenden Artikel herausgearbeitet.
Database Activity Monitoring, kurz DAM, klingt ja schon irgendwie beeindruckend.
Was hat es damit nun auf sich ?
Active bedeutet lediglich, das etwas außer dem Auditing bzw. Monitoring passieren kann.
Dies kann ein Alert eine Logmessage und/oder die Weiterleitung an ein SIEM sein.
SIEM bedeutet Security Incident and Event Management System. Eine Datenhalde für alle Arten von Audit/Log Daten außer denen, die schon vorher gelöscht wurden.
Wenn übrigens nichts weiter passiert außer '...log > /dev/null', heißt es immer noch Activity Monitoring.
Mehr ist nicht dahinter.
DAM's arbeiten generell in Realtime. Das klingt schon wieder nach High Tech, bedeutet allerdings auch nicht mehr,
als das zum Zeitpunkt des Erkennens eines SQL-Statements, etwas passieren kann.
Das dies bezogen auf die 100ige Gewißheit über die Auswirkungen eines Statement bei Netzwerkmonitoring und Query Based Architekturen generell nach der Ausführung des Statements passiert, wird von den Herstellern meist nicht erwähnt. Besser wäre hier eine exaktere Angabe z.B. Realtime before Execution oder Realtime after Execution.
DAMP nennt Ron Ben Nathan die Steigerung von DAM Systemen. P steht hierbei für Prevention. Jetzt kann endlich mal etwas passieren, das aktiven Schutz bedeutet. Noch bevor das Statement den eigentlichen Datenbankserver erreicht, kann dieses abgefangen und verändert werden oder ganz heftig, die Session kann terminiert werden.
Soweit dies wiederum auf der Netzwerkstrecke ( Client Richtung Server ) erfolgt, ist dies allerdings auch wieder nur viel Wind um fast nichts.
Warum ?
Welcher Angreifer verschafft sich mühsam über Privilegieneskalation den Zugriff auf kritische Daten und greift einfach ganz banal mit dem Originalnamen wie z.B. Creditcard darauf zu.
Eine harmlos klingende View z.B. "Titles" wird mindestens eingesetzt um den Zugriff auf die Creditcard Tabelle zu verschleiern.
DAM Produkte, welche lediglich auf das Netzwerk ( Client -> Db Server) zugreifen, sind somit mit einer simplen View oder einem Synonym für diese Art von Angriffen komplett auszuhebeln.
Redologs enthalten in der Regel keine Informationen über Select Statements, sodaß diese Architektur nicht für den Statementstyp "Select" hilft.
Die alternative SQL-Query Based Poll Technik war entweder extrem teuer oder extrem durchlässig, sodaß praktisch kein Hersteller diese noch einsetzt.
Bleibt nur ein Polling auf die Speicherbereiche an denen die Statements quasi 'nackig' dastehen. Dies ist nicht nur bei Oracle nach Erstellung der Ausführungspläne.
Dann sehen wir endlich die Basistabellen/Tabellen Funktionen und sehen die mehr oder minder kunstvollen SQL Konstrukte der SQL-Injection's samt Ausführungsplan, noch bevor diese ausgeführt werden.
Dieses Polling erfolgt i.d.R. nicht über eine SQL Abfrage, sondern durch extrem schnelles Auslesen der entsprechenden Hauptspeicherbereiche. Bei Linux/Unix und Oracle über den Shared Memory der SGA.
Der Overhead soll bei einem bekannten Hersteller im Regelfall bei ca. 3-5 % liegen.Dies ist um Welten günstiger als der klassische Performance Analytic Poller 'select * from v$sqlarea', der sich 'Overall' meist selbst zum größten Performance Problem macht.
Selbst bei dieser Speicherauslesetechnik kann es bei z.B. 5000 vollkommen identischen Statements zu Verlusten kommen. Angriffe, die hierauf basieren, erscheinen vielen als theoretisch konstruiert, aber abgesehen von einem möglichen DDOS Effekt könnten diese ziemlich ausgefuchst sein.
Hinter tausenden identischen Statements kann u.a. eine Angreifer-Session verborgen sein, die bei geschickter Anordnung, klassisch im hinteren Teil der vielen identischen Statements,potentiell unerkannt bleiben kann.
Der Sinn von tausenden vollkommen identischen Statements könnten z.B. Last und Peformance Tests bzw. Test bezgl. Caching SAN / DB , Cached Cursors, Function Cache, SGA, PGA und deren Verhalten sein.
Ein Beispiel aus der Produktion :
Das zumindest bei nicht direkt über den Host gesteuerten Geldautomaten viele identische Zugriffe nahezu zeitgleich stattfinden können, kann sich jeder vorstellen, der an einem Geldautomaten zwischen 11:00 - 12:00 Geld abheben will.
Die Prüfung allein der alten BLZ bzw. Teilen der aktuellen IBAN kann sich, je nach Programmierung, durchaus um 11:00 - 12:00 auf hunderte wenn nicht tausende vollkommen identische Statements hochschaukeln.
Wenn nun die Angreifer Session nach der BLZ auf das eigentliche Konto samt PIN ( Hash+Salt) zugreift, sollten diese Zugriffe in jedem Fall isoliert erkannt werden.
Ob das immer so ist, wird in einigen Use Cases für einen Hersteller von DAM Software aktuell getestet.
Wenn solch ein Statement Sensor mit dem Auslesen des Hauptspeicher zeitlich nicht mehr hinterherkommt, sind Lücken oder Sprünge die logische Konsequenz. Diese Sprünge dürfen allerdings nie über andersartige Statements erfolgen. Das Sicherheitsrisiko eines Sprungs über eine von von vielen identischen BLZ Vergleichsabfragen ist nach meiner Meinung isoliert betrachtet, recht überschaubar.
Die Moral von der Geschichte : Passen Sie auf, wenn spezielle Aktionen bei Ihnen ablaufen, die meist mit Annomalien bezgl. SQL Statements im Vergleich zum Standardbetrieb ablaufen.
Die Empfehlung von Oacle für die Produkte Audit Vault + Firewall einfach Exceptions zu definieren und das diese mal alle bestehenden Whitelist bzw.Blacklists überschreiben, greift mir zu kurz und ist das gefundene Fressen für ausgefuchste Angreifer.
Nicht die bestehenden Filter müssen überschrieben werden sondern deren Behandlung. Das ist zumindest ein Weg um die Anomalie zum Standardbetrieb zu erkennen.
Tipp : Legen Sie Ihre Filter Logiken mengenorientiert und unabhängig von den Behandlungen aus.
Das dem großen Datenbankriesen das Thema Database Security trotz eines Thomas Kyte noch nicht in Fleisch und Blut übergegangen ist, merkt man an dieser Stelle nur zu deutlich.
Wann hat der Schakal sein Attentat geplant ? Bei einem besonderen Anlaß mit vielen Menschen und mangeldem Schutz für sein eigentliches Ziel. So machen es clevere Angreifer auch.
Die beste Tarnung sind viele Menschen oder Session's, am Besten außerplanmäßige Session's!
Noch ein Wort zu den ausschließlich auf dem Netzwerk basierenden DAM Tools. Wenn man auf der Wegstrecke Client zu Server ein Select Statement abgreift, kann z.B. über eine vorbereitete Key Value Struktur ( Fast Refresh ) über den Namen des abgefragten Datenobjekts( View, Synonym, Table Function, ... ) recht schnell die
tatsächliche Tabelle/Tabellenfunktion ermittelt werden, welche sich dahinter verbirgt. Für SQL Injection's gibt es auch einen Ansatz, der allerdings den Rahmen dieses Artikel sprengen würde.
Diese Objektauflösung erfolgt in der Zeit, in der die eigentliche Abfrage im Datenbankserver das Ergebnis ermittelt.
Jetzt kann die DAM Regel greifen und mehr oder minder subtil reagieren.
Solange das reale Ergebnis noch nicht zurückgesendet wurde, hat DAM das Gesetz des Handeln auf seiner Seite.
Notfalls einfach die Session terminieren ist irgendwie langweilig und brutal. Außerdem vergibt man viele mögliche forensische Spuren um den Angreifer vielleicht am Arbeitsplatz um die Ecke zu stellen. Wie wäre es, den Angreifer vorläufig in Sicherheit zu wiegen. Wenn er schon auf die Creditcard Tabelle zugreift, dann bekommt er auch Creditcard Daten, allerdings künstlich erzeugte und nicht reale. Hierfür muß nicht unbedingt in den Ausführungsplan eingegriffen werden.
Dafür muss die Wegstrecke Server zu Client manipuliert werden, allerdings an der richtigen Stelle und mit Daten aus einer künstlich erzeugten Session. Damit hat man die Möglichkeit Angreifer zumindest eine gewisse Zeit in Sicherheit zu wiegen. Warten Sie allerdings nicht zu lange mit diesem Ansatz ...
Mit dieser Konstruktion könnte so mancher DAM Hersteller seinen DAM Tool deutlich mehr "Grip" verleihen, ohne in den jeweiligen Speicherarchitekturen von diversen Herstellern versinken zu müssen samt derer diffizilen Pflege.
Bezogen auf diesen Tipp dürfen sich die entsprechenden Hersteller gerne mit mir in Verbindung setzen und mein Konto ist übrigens bei ...
Fazit :
Netzwerkstrecken zum Datenbankserver auf SQLStatements hin abzuhören, hört sich toll an, ist allerdings für echte Angreifer nur ein Witz.
Nehmen Sie sich etwas Zeit, die jeweiligen Produkte auf ihren praktischen Nutzen hin zu überprüfen.
Wer verwalten will soll verwalten, wer schützen will soll schützen.
Resolving Oracle Objects oder wie Oracle über 30 Jahre lang Stolpersteine pflegt (new 03.06.2014)
Die trickreich mitgeschnittene Abfrage über das Netzwerkwerk
"Select cust_nr from scott.customer where upper(firstname||lastname) like '%JEFF%BECK%' ;"
sieht recht harmlos aus.
Leider lassen einige Hersteller für Database Activity Monitoring Software die Kunden in diesem Glauben.
Was wir eben nicht wissen ist, welche Table(s)) /Table Function's sich tatsächlich hinter dem Objekt "SCOTT.CUSTOMER" letztendlich verbergen.
Hier die üblichen Verdächtigen :
- eine andere Table oder Tables ( indirect, cascading )
- eine View oder View's ( direct/indirect cascading)
- ein Synonym private oder public oder Synonym's ( direct, cascading)
- eine Table Function* oder Table Function's ( direct/indirect cascading )
- ...
oder ein Mischmasch aus einigen oder allen dieser Objecttyp's.
Direct bedeutet, die Objecttypen sind über das Data Dictionary direkt miteinander verbunden.
Indirect bedeutet das Gegenteil. Beispiel : Eine Table basiert auf dem Inhalt eines Join's zweier Table's via asynch. Process.
Die Tatsache, daß sich der Bezüge evtl. über das Data Dictionary auflösen lassen, ändert nichts am Status 'Indirect'.
Synonym's sind nahezu jedem bekannt und offensichtlich recht leicht aufzulösen.
"select * from all_synonyms where synonym_name = 'CUSTOMER' gibt uns die Bezüge im Klartext aus.
Synonym Owner, synonym name, table_owner , table_name
Aber Vorsicht !
Die Spalte "TABLE_NAME" ist irreführend.
Hinter "TABLE_NAME" können sich auch View's verbergen.
Hoppla, auch Procedure's können sich hinter "TABLE_NAME" verbergen und noch allerhand andere Objecttyp's.
Ob nun historisch gewachsen oder nicht, Oracle hatte genug Zeit dies geradezubiegen.
Korrekterweise müsste nicht nur diese View den Object_Name und den Object_Type enthalten.
Da es nicht so ist, kann man für die Auflösung von einigen Objecttype's die Procedure
"DBMS_UTILITY.NAME_RESOLVE" verwenden.
Für z.B. Synonym's funktioniert dies auch.
Eine der gefährlichsten Maskierungen von Table's sind View's.
Hier versagt aus irgendeinem Grunde die Procedure "DBMS_UTILITY.NAME_RESOLVE".
Wer sich nun über den OBJECT_TYPE Baum eines Top_Level Objekts nach unten durchhangeln will, hat allein für VIEW's einige Hürden zu meistern..
Nehmen wir an ein Top Level Object, ein Public Synonym, zeigt auf eine View.
Diese View zeigt auf ein Private Synonym welches widerrum auf eine andere View zeigt.
Diese View basiert auf einer Table Function, welche auf zwei Tabellen zugreift und zwar Creditcard und Customer_Address.
Public Synonym
View in schema A
Private Synonym in schema B
View in schema C
Table Function in schema D
Two Tables in schema E
Wir beginnen damit den Object Typ des TOP LEVEL Object's zu ermitteln über "DBA_OBJECTS".
Dann checken wir die "DBA_SYNONYMS"
Wenn wir dort fündig wurden, müssen wir herausfinden, welcher Objecttyp sich hinter dem "TABLE_NAME" verbirgt.
Um zu checken ob es VIEWS sind, müssen wir die DBA_VIEWS überprüfen.
Hier kommt der nächste Stolperstein.
Den Bezug von einer konkreten View zu einem oder mehreren Objekten darunter kann man nur über die Spalte "TEXT" die zu allem Überfluss auch noch den Uralt Datentype "LONG" besitzt, ermitteln.
Damit man in LONG Spalten suchen kann, benötigt man eine Konverierungsfunktion von LONG ZU CLOB !.
Mit DBMS_LOB.INSTR kann es dann losgehen.
Hat man nun endlich die Objekte der ersten Stufe unterhalb der VIEW geht es am besten rekursiv weiter, bis alle Blätter samt den jeweiligen Objekt Typ's aufgelöst sind.
Wichtig : Hinter Views und Table Functions können sich jeweils mehrere Objects mit unterschiedlichen Objecttyp's auf einer Ebene verbergen.
Das beschriebene TOP DOWN Verfahren ist ja ganz nett als Info, wird logisch allerdings meist als Forensik Methode eingesetzt.
Anders herum kann man schon mehr damit machen.
Wenn wir uns mit einer Prozedur, ausgehend von einer Menge kritischer Tabellen z.B. Creditcard, Customer_Address, durch alle darüber liegenden Objecttyp's hangeln und diese einem Plausibilitätscheck oder zumindest einer Freischaltungsverfahren unterziehen, kann mit einfachen Hashfunktionsaufrufen überprüft werden, ob sich an dem Objecttyp's Überbau etwas geändert hat.
Wer Lust hat, kann erweiterte Prüfungen einbauen und z.B. im Recylebin und in Datenbankblöcken nach Hinweisen auf gelöschte Objekttyp's Ausschau halten.
Über den Tellerrand schauen :
Parallel zur Cascade der Objecttyp's macht es Sinn sich den relevanten Privilegienbaum anzuschauen und zwar mit allen direkten und indirekten Privilige's.
Äuch diese sollten bezgl. Änderungen regelbasiert verfolgt werden. Die Gesamtbetrachtung nur dieser beiden Anteile kann einiges über das Potential für Angriffe, dem Stand von Vorarbeiten für Angriffe oder einer bereits existierenden Infrastruktur für oder von erfolgten Angriffen aussagen. In jedem Fall erklimmen Sie damit die nächste Stufe oberhalb der typischen Baselines im Database Security Umfeld.
Das es dann eigentlich ers richtig los geht, sollen die nächsten Schritte andeuten :
Suche nach allen gefundenen Objectnames im Quellcode der Stored Procedures/Functions.
Checken Sie, ob wirklich nur der original Oracle Code obfuscated ist.
Suche der Objectnames in z.B. V$_SQLAREA ...
Denken Sie an vorsichtige Angreifer, die eventuell kritische Teildaten in eigenen Tabellen mit unverdachtigen Bezeichnungen evtl.verschlüsselt abspeichern.Checken Sie alle verschlüsselten Spalten, ob diese wirklich operativ zu ihrem regulären Betriebsablauf gehören. Kalkulieren Sie auch Angriffe ein, die als oder in reguläre Abläufen getarnt sind.
Fazit :
View's sind allein und in Kombination mit anderen Objecttyp's eine simple und höchst gefährliche Form zur potentiellen Maskierung von Zugriffen auf kritische Table's/Table Function's.
Oracle hatte mehr als 30 Jahre Zeit, die Stolpersteine im nativen Data Dictionary zu bereinigen um die Auflösung von allen Objecttyp's zu vereinfachen. Die Ausrede abwärtskompatibel sein zu müssen zählt nicht, da man mit einer simplen Namenskonvention für OLD_DATADICTIONARY_VIEWS den Uralt Code mit einem Replace/Codebasis warten kann.
Anders ausgedrückt, bedeuten die Stolpersteine nach meiner Erfahrung, das kaum jemand solche Prozeduren geschrieben hat.
Jedenfalls nicht für den Zweck einer vollständigen Auflösung.
Tipp :
Entwickeln Sie eine Procedure/Function, welche Ihnen die komplette Auflösung in beiden Richtungen samt View's ermöglicht.
Diese abwärtskompatibel zu ihren Oracle Versionen z.B. 10g-12c und nach Möglichkeit ohne Versionsabhängigen Code.
Wenn Sie ein Security Schema besitzen, können Sie dort die Standard Data Dictionary Views der Objects nachbauen z.B. jeweils mit einem Join zu "DBA_OBJECTS".
Speichern Sie die Ergebnisse der Auflösungen in einer Table in diesem gesicherten Security Schema ab und legen Sie z.B. einen Trigger oder einen CQN Event darauf, der bei Differenzen der Ergebnisse ( Hashfunctions or SQL SET Functions ) Alarm schlägt !
* Der Grund warum z.B. Table Function's als eigenständige LOW LEVEL Objekte geführt werden, ist recht simpel.
Stellen Sie sich eine Anwendung vor, welche Daten über Socket's in die Datenbank sendet.
Die Tabellenfunktion ( PL/SQL with XDB/UTL_TCP or JAVA with PL/SQL Wrapper) besitzt damit nicht zwingend eine LOW LEVEL Object vom Type Table, welches sich auch noch über das Data Dictionary ermitteln läßt, erscheint jedoch logisch als Table!
Secure PL/SQL Code - dynamic vs. static
Dynamic SQL oder PL/SQL in PL/SQL findet man häufiger in produktiven Oracle Datenbanken als vermutet.
Wenn sich dieser Code über kritische Daten hermacht, sollte dies ein Warnsignal sein um SQL Injection und anderen Techniken mehr oder minder einen Riegel vorzuschieben. Wie sieht es jedoch mit dynamischen PL/SQL Code aus, der nicht direkt kritische Daten verarbeitet ?
Dieser Code ist für Angreifer überaus interessant.
Meist tritt dieser Code derart häufig auf, das allenfalls die offensichtlichsten SQL Injection Angriffe über Funktionen des Packages dbms_assert abgefangen werden, wenn überhaupt. Eine Zeitbombe tickt daher in vielen Oracle Datenbanken. Die DBA's haben in der Regel keine Verantwortung für Applikationcode. Die Fachabteilungen investieren meist in Funktionalitäten und können nur schwer Budget's für Security Maßnahmen von nicht direkt mit kritischen Daten verbundenen PL/SQL Code verargumentieren.
Hier nun ein Lösungsansatz, der sehr konsequent auf Dynamic SQL und Dynamic PL/SQL setzt. Die Frage ist nur wann, wo und vor allem was wird erzeugt - sprich generiert.
Für den Einstieg unterscheiden wir
- Pre-generated
- On the fly generated
PL/SQLCode.
Pre-generated bedeutet, der Code wurde außerhalb der Produktion generiert, getestet und freigegeben.
On the fly generated bedeutet, der Code wird zur Laufzeit in der Produktion automatisiert erzeugt
Beide Techniken werden überlicherweise in Form von Codegeneratoren eingesetzt.
Wenn dies so ist, kann hier mit einer einzigen Regel einen immenser Sicherheitsgewinn erlangt werden.
- Generiere, soweit sinnvoll, static Code - keinen dynamic Code der Stufen 1-4!
Die Idee : Halte nur den Code für Funktionalität in der Datenbank vor, der praktisch immer gebraucht wird.
Sonderfunktionen und sehr seltene bzw. gefährliche Funktionalitäten müssen nicht permanent als Code in der Datenbank vorhanden sein. Dies ersteinmal unabhängg von der Art und Weise ( static,dynamic)
Wenn alle Creditcard Nr. geändert werden sollen, kann man zudem gleich Pakete generieren, die parallel abgearbeitet werden.Statt Paketen könnnen auch SQL Scripts erzeugt werden, die parallel sämtlich nötige Updates durchführen um das Data Dictionary nicht über Gebühr zu belasten.
Anschließend werden die Pakete und/oder Scripte gelöscht.
Es gibt somit im Normalbetrieb nicht die Möglichkeit alle Creditcardnr, auf eínen Schlag zu ändern, zu selektieren usw.
Wer solche und ähnliche Fälle nicht mit generiertem static Code handhaben möchte, der kann zumindest automatisiert die Prüfungen über dbms_assert und weiteren Plausibilsierungen in den dynamischen Code generieren lassen.
Hierdurch ist die Gefahr von Security Leaks durch typische Ablaufumstände in betrieblichen Umgebungen deutlich minimiert.
Für kritische Tabellen nach Möglichkeit Code zu generieren, der z.B. DML lediglich auf Einzeldatensatzebene und nicht auf Mengen erlaubt, bringt einen zusätzlichen Sicherheitsgewinn.
Für Reports kann temporär z.B. Select Code generiert werden, der anschließend wieder gelöscht wird.
Soweit so gut. In der Realität wird von den Eingangs beschriebenen Techniken, wenn überhaupt 'pre-generated' eingesetzt.
Das ist sinnvoll. 'On the fly generated' wird in vielen Firmen aus diversen Gründen nicht eingesetzt.
Wenn wir 'on the fly generated' mit der Nachvollziehbarkeit von unsicherem dynamic SQL der üblichen Stufen 1-3 vergleichen, bleibt ein Erstaunen nicht aus. Codegeneratoren die in einer Oracle Datenbank arbeiten, sei es nun auf Entwicklungsmaschinen oder gar auf Produktionsmaschinen, kommen meist nicht ohne Metadaten ( Repositorien) aus. Dies werden naheliegenderweise oft in Tabellen abgelegt. Hiermit und mit der Architektur des Codegenerators läßt sich leicht ein verhältnismäßig hoher Aufwand für Angreifer schaffen, zumindest im Vergleich zu den oft hochgefährlichen SQL Injection Lücken die vielfach vorhanden sind und von jedem Spielkind das sich 5 Minuten via Googel mit SQL Injection beschäftigt.
Vor diesem Hintergrund lasse ich mich doch glatt zu der Aussage hinreißen, das 'On the fly' Codegeneratoren auf Produktivsystemen deutlich sicherer sein können als all die vielen kleinen und großen Zeitbomben die in der Realität über dynamic SQL Code vorhanden sind. Wer ganz sicher gehen will, erzeugt für die Codegeneratoren eigene Entwickleraccounts und bleibt in der 'pre-generated' Logik.
Nach diesem Einstieg kommen wir nun zu der Art des Quellcodes.
Von Hand geschriebener Code muss wie wir alle Wissen eine Form aufgeweisen, die es nicht nur Steven Feuerstein ermöglicht, nachzuvollziehen, was dort eigentlich passiert.
Bei generiertem Code ist dies nicht unbedingt notwendig.
Soweit der erzeugte Code nicht selbst als Metadatenpool bzw. anderweitige Auswertungen des Codes für produktive Abläufe genutzt werden, kann der statisch generierte Code aussehen wie Kraut und Rüben.
Ganz im Gegenteil könnte man systematisch Obfucation Techniken einsetzen um den Code bewußt unleserlich zu halten. Außerdem können Codegeneratoren den gleichen Code zyklisch mit immer neuen Namen und mit wechselnden Parameteranordnungen erzeugen.
Kurzum, kein Mensch soll generierten Code in der Datenbank so einfach lesen können.
Ein enormer Sicherheitsgewinn.
Neben dem Vorteil des irregulären Zugriffs auf kritische Daten wird zudem der PL/SQL Code geschützt. Ein Aspekt der nach meiner Erfahrung bislang eine eher unbedeutende Rolle besitzt. Je weniger Angreifer über die Modellierung der kritischen Daten und der Art des Zugriffs Wissen erlangen können, umso besser.
Obfuscation Techniken für die Metadaten von Datenbankobjekten gehören somit in des Gesamtkonzept und werden in einem eigenen Artikel beschrieben.
Ein gut getesteter Codegenerator erzeugt bei noch besser gestesteten Metadaten korrekten Code mit einer Wahrscheinlichkeit von über 99%.
Es ist zudem faszinierend wie produktiv und effektiv Codegeneratoren sind.
Besitzt man ersteinmal ein solche Infrastruktur, kann man für Notfälle vorab generierten Code schnell in die Datenbank übertragen. Falls zum Beispiel Angriffe auf die Tabelle Creditcard erfolgten, kann mit dem 'Notfall' Code der lediglich bestimmten IP Adressen und Anwendungen den Zugriff ermöglicht, eine teuere Downtime vermeiden.
Metaprogrammierung ist zudem ungleich interessanter als von Hand geschriebener PL/SQL Code.
Zum Schluss sei noch bemerkt, das static Code in der Regel meist die beste Performance bietet. Dies gilt ersteinmal in der Einzelbetrachtung.
Fazit :
Die im Raum stehende meist nicht explizit ausgesprochene Forderung, Quellcode in der Datenbank anschauen zu wollen, führt zu hohen Sicherheitsrisiken.
Und es gibt schönere Dinge die man anschauen kann, als akkurat formatierten PL/SQL Code ...
Internes JDBC Gateway Oracle ( Oracle intern + MS SQLSERVER Query )
Der erste Prototyp mit dem Zugriff auf SQL-SERVER Daten aus Oracle heraus März 2014
Der erste Join führt die Oracle scott.emp Tabelle mit der MS SQLSERVER Northwind.Products Tabelle vollkommen
sinnfrei zusammen.
JDBC Gateway
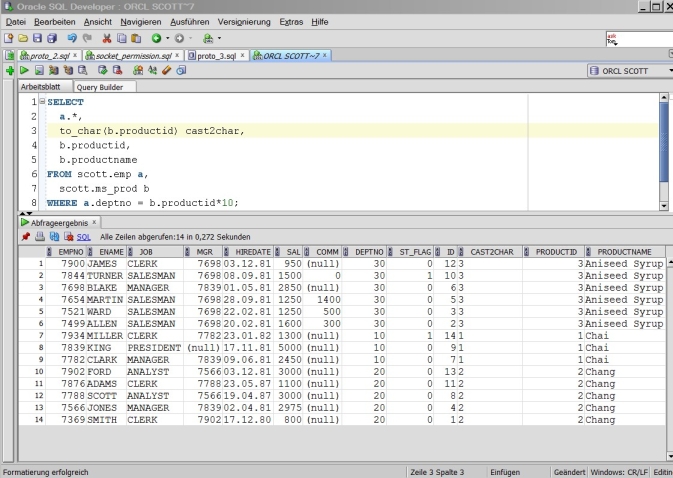
Folgende Remote Datenbanken werden (vorerst) mit Prio auf JDBC 3.0 angepasst und getestet :
- Oracle XE / SE / EE
- MS-SQLSERVER
- IBM DB2
- MySQL
- PostgreSQL
- Sybase
http://java-source.net/open-source/jdbc
Anmerkungen :
Wenn man Microsoft JDBC bewältigt hat, kann es mit den anderen eigentlich nur besser werden.
Worüber ich mir aktuell Gedanken mache
Wie ist es möglich die RefCursor Funktionalität von Oracle anderen SQL Datenbanken einzuhauchen ?
Aus Oracle Sicht mit einem RefCursor auf Daten von anderen SQL-Datenbanken zuzugreifen ist schon jetzt möglich.
Wie sieht es allerdings für den Fall aus, das z.B. MS-SQL Server die Refcursor Funktionalität von Oracle nutzt?
Im einfachsten Fall wird eine Oracle Funktion mit RefCursor Parameter/Return über ein Proxy Object aus MS-SQL Server heraus aufgerufen und verarbeitet beliebige Daten, z.B. DB2 Host.
Dies setzt allerdings ein funktionierendes Proxy Konzept für MS-SQL Server voraus.
Internes JDBC Gateway als Security Feature
Hat man es ersteinmal geschafft, eine Implemtierung auf die Beine zu stellen, ergeben sich vielfältige Möglichkeiten im Bereich Security.
Level 1: Kritische Daten statisch verteilen.
Verteilt man die Kreditkartentabelle auf z.B. 3 Datenbanken unterschiedlicher Hersteller, kann man mit dem JDBC Gateway eine wirklich beschränkte Zugriffskontrolle leicht implmentieren.
Im Config Teil meines JDBC Gateways kann man optional ein Audit für Select und andere DML konfigurieren.
Dies gilt, falls überhaupt erlaubt, auch für DBA's.
Diese sollten jedoch das JDBC Gateway für Application Realms nicht nutzen.
Level 2: Kritische Daten dynamisch verteilen
In zufälligen Zeitabständen oder nach einer bestimmten Anzahl von Zugriffen auf kritische Daten, werden diese automatisch und per Algorithmus gesteuert auf diverse Datenbanken umgeschichtet.
Mit integrierten Verwirrungsdatenanteilen und antäuschenden Select's braucht man kollaborierende DBA's auf allen beteiligten Datenbanksystemen um einen Angriff zu bewältigen.
Vorteil : Kein Mensch weiss, wo die Daten genau liegen.
Auditing sysoperation und personalisierte High Privileged Accounts
Vor einigen Jahrzehnten mag die Designentscheidung von Oracle halbwegs vernünftig gewesen sein.
Sysoperations werden nicht in der Datenbank auditiert.
Entweder alles oder nichts wird auditiert.
Meistens endet das Alles im Nichts nämlich /dev/null.
Spätestens seit den Angriffen auf Datenbanken, die sich kommerziell in verkauften CD's manifestieren, ist es vorbei
mit der Alleinherrschaft der DBA's.
Einfach mal alle aud files löschen ist nicht mehr legitim.
Die Beibehaltung der Oracle Designentscheidung sorgt daher im heutigen Betriebsablauf für allerhand Aufwand, im günstigsten Fall.
Nach meiner Erfahrung hat besonders in Deutschland das Thema Daten und Datenbank Sicherheit jahrelang nicht die Beachtung und Konseqeuenzen erfahren, die notwendig wären.
In den letzten Jahren werden erste Maßnahmen der 'Database Security' umgesetzt, die meist etlichen Brüchen unterworfen sind.
Hier nur einge Punkte :
Ausschließlich DBA Aktivitäten sollen protokolliert werden.
DBA's haben oft SYSDBA Rechte
Alle anderen potentiellen Auditdatentöpfe sind Sache der Fachabteilungen
Es gibt oft keinen eigenen technischen Security Bereich, sodaß DBA's ein DBA Auditing aufsetzen ;)
Der Ausstauch DBA Truppe zu SIEM funktioniert oft schlecht, weil wie schon erwähnt, kein eigener
dezidierter Security Bereich existiert.
Ein persönlich haftender Mitarbeiter trägt oft das Restrisiko aller Security Verfehlungen.
SYSOPERATIONS
Alle sysoperations ungefiltert über syslog an ein SIEM zu leiten,
kann in einer selbstgeschaffenen DDOS Attacke enden.
Warum ?
- Die schiere Menge der Datenbanken...
- Viele Aktivitäten der DBA'S benötigen keine SYSDBA/SYSOPER Privilegien, werden dennoch meist unter SYSDBA ausgeführt.
- SQL-Scripte jedweder Größe werden Zeile für Zeile auditiert. Dank Multiline Messages gleich welchen Formats kommt auch der gesamte Quellcode von z.B. Avaloque zum SIEM
- Viele Softwarekomponenten / Agenten konnektieren sich zyklisch gegen die Datenbanken und erzeugen dadurch ungeheure Datenmengen.
- Alle Oracle Background Prozesse samt Jobs werden auditiert.
Es braucht keine große Vorstellungskraft, das in Firmen mit einigen hundert, wenn nicht
tausenden Datenbanken, ein SIEM mit diesen Auditdatenmengen allein von den Datenbanken nicht mehr
hinterherkommt. Selbst wenn der Transport durch enormen Plattenplatz gepuffert wird, ist die
Aktualität sowie die sicherheitstechnische Relevanz bei direkter Stream Lieferung in Frage zu
stellen.
Auch wenn einige SIEM Systeme skalieren, tun sie dies meist nicht bei Einführung einer Auditdatentransportlösung.
Abhilfe besteht darin gerade von Anfang an Filter zu nutzen.
Ein Filter kann auch eine Aggregation sein.
Die z.B. 5000 Connects eines Agents können eventuell zu einer Message mit den Angaben
zu einem Zeitintervall zusammengefasst werden.
Wie allerdings Filter einbauen, wenn Oracle dies nicht vorsieht ?
Indirekt geht es.
Statt die sysoperations ungefiltert über syslog an ein SIEM zu leiten, kann man syslog-ng verwenden.
Dieser ist nicht nur transaktionssicher sondern besitzt ausgefeilte Möglichkeiten zur Filterung.
Außerdem kann das gute Stück implizit puffern, falls das SIEM ausgefallen ist, vielleicht durch zu viel Traffic...
Weiterhin können selbstmodellierte High privileged Accounts unabhängig von SYSDBA/SYSOPER über eigene Audit Commands im Rahmen des Standard Auditing gezielt auditiert werden.
Bleibt das Problem der ungleichmäßigen Verteilung der sysoperations Auditdatenmengen.
Zu bestimmten Zeiten geht es bei den DBA's ab. Leider eskaliert die unterschiedliche Größe der
Scripte diese Häufungen im Betriebsablauf zu extremen Peaks im Auditdatenvolumen.
Verteilung ist eine Lösung und zwar mengenmäßig in definierten Zeitintervallen.
Wie sieht es allerdings mit besonders gefährlichen oder auf Angriffsmuster passende Auditeinträge aus ?
Diese könnten bei originärer zeitlicher Sortierung viel zu spät ein tiefergehendes Auswertungszeanrio erreichen.
Auch dies läßt sich über Filter und Vorabbewertungen regeln.
Ein Filter kann auch sortieren.
Der syslog-ng Filter ist hierbei allerdings machtlos, da er schlicht zu spät greift.
Eine Verteilung funktioniert in diesem Kontext eigentlich nur mit einem Zwischenspeicher.
Dieser wird hinsichtlich Kritikalität sortiert und entsprechend zeitlich verteilt abgearbeitet.
Diese Überlegung führt tatsächlich zu Lösungen, die z.B. die klassischen aud Files auslesen
in der Datenbank zwischenspeichern filtern und priorisieren um diese anschließend voll parametergesteuert und
zeitlich verteilt in Häppchen an das SIEM zu senden.
Natürlich sind Lösungen außerhalb der Datenbank theoretisch sicherer, doch scheuen viele Firmen die Integrations- und Wartungs-Aufwände von expliziten Security Software Bündelungen. Ein überschaubares Security SQL-Script läßt sich in der Regel schneller ausrollen und in den Betriebsablauf integrieren. Besser eine einfache Lösung als keine und besser als ein neues Monster Projekt.
Eine meiner SQL Lösungensansätze verwendet zur Versendung der Auditmessages tcp sockets aus der Datenbank heraus. Ein Security Schema enthält die gesamte Logik samt Auditdaten und wird durch den Einsatz von Sicherheitsfunktionen unerlaubte Datenveränderungen und Datensichtungen auch von SYDBA's überwacht.
Eine alternative Ausbaustufe könnte wieder den syslog- ng verwenden, der die Daten mit seiner Vorfilterung
nicht direkt an das SIEM, sondern ersteinmal in die Datenbank leitet. Dort gibt es einen Socket zur Versendung an das SIEM, der allerdings über eine vorgeschaltete Mengenkontrolle notfalls in eine Pufferung / Table umleitet.
Wichtig ist, das jede Message bewertet wird in Bezug auf Kritikalität.
Unser Versender Socket wird demnach sowohl vom sysoperations socket als auch von der Puffertabelle befüllt ( union), dies allerdings entsprechend einer Priorisierung nach Kritikalität.
SYSDBA/SYSOPER und deren Nachbildung.
Leider kann man die folgenden 'hart verdrahteten' Privilegien nicht bzw. nicht vollständig an selbst geschaffene Accounts zuweisen.
SYSDBA
Perform STARTUP and SHUTDOWN operations
ALTER DATABASE: open, mount, back up, or change character set
CREATE DATABASE
DROP DATABASE
CREATE SPFILE
ALTER DATABASE ARCHIVELOG
ALTER DATABASE RECOVER
Includes the RESTRICTED SESSION privilege
SYSPOPER
Perform STARTUP and SHUTDOWN operations
CREATE SPFILE
ALTER DATABASE OPEN/MOUNT/BACKUP
ALTER DATABASE ARCHIVELOG
ALTER DATABASE RECOVER (Complete recovery only. Any form of incomplete recovery, such as UNTIL
TIME|CHANGE|CANCEL|CONTROLFILE requires connecting as SYSDBA.)
Includes the RESTRICTED SESSION privilege
Dies ist allerdings nicht das Problem.
Für alle anderen Aktivitäten die diese Privilegien nicht benötigen, kann man sich eigene Rollen und
möglicherweise personalisierte High Privileged Accounts bauen.
Nach meiner Erfahrung bestehen Auditdaten von sysoperations bis zu 95% aus Aktionen, die über die offiziellen Privilegien abbildbar sind.
Ob ein DBA im Regelfall manuell Datenbanken direkt mit Shutdown xxx herunterfährt oder über eine abgesicherte Routine, kommt sich gleich. Statt shutdown immediate in SQLPLUS bietet sich eine Routine auf OS Ebene mit den jeweiligen Parametern an. Selbst mit JAVA und JDBC lassen sich diese Funktionalitäten abbilden.
Warum nicht ein Sudo Konzept auf Datenbankebene bzw. auf OS-Ebene für SYSDBA-Operationen einführen.
Dies jedoch nach Möglichkeit ebenfalls personalisiert.
Die Regel, alle DBA's, ob nun personalisiert oder Shared, generell für den Standardbetrieb mit SYSDBA auszustatten, halte ich für gefährlich.
Das jeder DBA personalisert einen Notfall SYSDBA Account erhält, könnte die Vermeidung von Shared Accounts
zudem ermöglichen. SYS und SYSTEM sollten komplett stillgelegt werden.
Bleibt noch das implizite Sudo Konzept von Oracle, welches bei z.B. Backup oder Export hard-coded zum Einsatz kommt. Selbst diese impliziten Identitätswechsel kann man durch Auflösung im Data Dictionary nachvollziehen. Auch ein Thema für eine vorgeschaltete Aufbereitung von Messages.
Abschließend sei noch darauf hingewiesen, das die eindimensionale Auswertung basierend auf Auditdaten von sysoperations nicht unbedingt zielführend sein muss um Angriffe über Privilegieneskalation usw. zu erkennen.
Bei forensischen Untersuchungen helfen die klassischen Auditdaten der Oracle Systemtrigger enorm.
Diese haben den Vorteil, das man damit ein Audit in der Datenbank für alle DDL Aktionen, auch von SYSDBA, realisieren kann. Jeder grant oder revoke ist sofort ersichtlich und kann notfalls über einen Abwehrschild 'on the fly' neutralisiert werden.
Sehen Sie diese zusätzlichen Auditdaten analog zu den Spurenfetischisten bei Kriminalfällen. Ein Gesamtbild möglicher Angriffe wird durch diese Auditdaten überhaupt erst möglich.
Der Forderung keine Auditdaten in der Datenbank zu speichern, ist bei Nachvollziehbarkeit jeder Aktion nicht zwingend, soweit eine Absicherung dieser Daten hinsichtlich aller DML Befehle inkl. select auch von SYSDBA's existiert. Hierzu kann man Logger Funktionen in Virtual Columns nutzen, die zudem die eigentlichen Auditdaten entschlüsseln, sowie die Continous Query Notification ( CQN), welche Änderungen an den gespeicherten Auditdaten erkennt.
Fazit :
Hier ein Fahrplan den man bei einem übergreifenden Auditkonzept anwenden könnte.
SYSDBA als Default für DBA's und High Privileged Accounts ablösen
Jeweils ein aktiver personalisierter High Privileged Account mit z.B. Secure Application Roles
Sudo Konzept für Shutdown/Startup++ usw. optional asynchron
Personalisierte SYSDBA Notfallaccounts optional mit einer angepassten eigenen Filterlogik
Reale Lasttest gegen Ihr SIEM mit exakten Durchsatzwerten basierend auf Prod sysoperations und Standardauditing samt Simulation von Application Auditing...
Filterlogiken samt Filterpunkten in Ablaufkette aufsetzen bzw. festlegen
Architektur der Filterlogik festlegen und POC
...
Etwas zu konstruieren, das z.B. jede DBA Aktivität einer Person zuordnet, ist nicht sonderlich schwer,
die Sicherheit einer Datenbank zu erhöhen hingegen schon.
Massendaten mit dem Oracle ERRORTRIGGER vermeiden
Ich wundere mich immer wieder, wie wenige Datenbanken eine Härtung mit den System Triggern erfahren.
Liefern doch Logon's, DDL's und Errors's eine gute Datenbasis für ein klassisches SIEM. Bis auf den Error Trigger ist das in der Regel auch völlig unproblematisch. Selbst der Error Trigger ist nicht unbedingt gefährlich. Gefährlich sind Anwendungen jedweder Art, die bestimmte Exception' s einfach nicht behandeln. Besonders tückisch sind Anwendungen die gegen Datenbanken laufen und deren Enwickler die dummen SQL Persistenzspeicher nicht nur innerlich vollkommen ablehnen.
Der Errortrigger ist quasi der Psychiater, der mit der Anwendung auf der Couch in einen regen Dialog kommt. Dieser Austausch kann derart eskalieren, das der Errortrigger Millionen Datensätze in vergleichsweise kurzer Zeit erzeugt. Diese sind natürlich interessant im Sinne der Ablaufsicherheit, Datenkonsistenz usw.. Allerdings sollten diese zigfach identischen auftretetenden Datensätze ( bis auf den Zeitstempel) nur jeweils einmal versendet werden.
Wie kann man diesem Umstand begegnen ?
Die einfachste Lösung wäre , einmalig die Massendaten tatsächlich zu speichern, diese vor der Versendung auszuwerten, sprich zu aggregieren und optimistisch der Filtertabelle des Errortriggers ab einem gewissen Schwellwert automatisiert neue Einträge zu verpassen. Wie man den Overhead der Filtertabelle im Sessionhandlung des Errortriggers durch Caching vermeidet, sollte jeder erfahrene PL/SQL Programmierer wissen und in jedem Fall realisieren.
Stufe 1 : Table caching
Stufe 2: Select mit result cache
Stufe 3: Function mit Resultcache
Stufe 4: ...
Bei diesem Ansatz kann je nachdem, welche Anwendungen sie so besitzen, die Partitioning Option von Oracle ein Vorteil sein.Diese kostet allerdings soviel wie ein Ersatzmotor und Ersatzgetriebe zusammen im Verhältnis zum Kaufpreise ihres Fahrzeugs.
Die Messagetypen des Errortriggers sind nach dieser Methode immer vom Typ AGGREGAT oder COUNTER , wobei lediglich die Ausreißer mit einem Counter > 1 einmalig ! versendet werden, alle anderen Messages besitzen
den Counter 1.
Automatismen mal einfach ohne Prüfung einbauen ist immer gefährlich, wenn nicht fahrlässing. Die einmalig versendeten Messages mit den hohen Countern sollten in jedem Fall sicherheitstechnisch bewertet werden.
Ist die hunderttausendfach auftretende Constraintverletzung ein klassischer Error und/oder Teil eines Angriffs. Nur wenn Sie absolut sicher sind, notfalls im Dialog mit dem Hersteller der Software, kann genau dieser Error vorläufig in den Filter.
Quasi auf Wiedervorlage können Sie genau diesen Filtereintrag setzen, nachdem z.B. ein Update oder Patch ihres Herstellers installiert wurde und dieser beteuert, die Software sei nun endlich fehlerfrei, indem Sie den Filtereintrag vorübergehend deaktivieren aber nicht löschen. Mit einem zusätzlichen Hochheilg Flag können Sie zusätzlich die Versprechungen ihres Herstellers über die Jahre an sich vorrüberziehen lassen. Für Hersteller wie Oracle kann man ein Freitextfeld in die Filtertabell einbauen der dem Duktus des Konzerns entgegen kommt.
- Ist kein Fehler, sondern ein Feature
- Ist undokumentiert und darf nicht verwendet werden.
- Wurde schon vor einem Jahr gefixt.
- Geht nicht anders, wir bauen doch nicht die gesamte Software um ..
- Wird in Oracle 14nsa gefixt
Die aufwändigere Lösung beseitigt sogar die Einmalspeicherung und Löschung der Massendaten von meist wenigen Errors, und arbeitet dennoch performant. Dies allerdings mit allerhand Tricks. Diese Lösung wird kommerziell verwertet.
Tipp : In jeden Fall sollten System-Trigger und Schematrigger im Rahmen einer Härtung zur Anwendung kommen.
Wenn Sie sinnvolle Filter verwenden, ist die Belastung der Systeme gering bis akzeptabel, eben nach Qualität der Filter.
Ich bewundere übrigens die Kollegen, die fast immer kleine elegante Lösungen mal so nebenbei vorstellen. Bei mir sind entweder die Aufgabenstellungen etwas breiter angelegt oder vielleicht bin ich ja einfach nur zu dumm, um die einfachste Lösung zu erkennen. Das Ganze hat bestimmt etwas mit dem Umgang von Komplexitäten zu tun, und wie Einstein schon sagte ...
LISTENER.LOG auslesen mit PL/SQL im Rahmen einer Konzernanwendung
Konzernanwendung kann bedeuten : Muss auf allen Oracle DB's unter Linux/Unix mit Version 11g und nach Möglichkeit auch unter 10g laufen. Das können in einem Konzern schon einige DB's sein. Alles ist mehr oder weniger gleich.Das weniger bedeutet praktisch immer mehr bei der Arbeit, zumindest bei meinen Kunden.
Um es vorweg zu sagen, wer keine Environmentvariable für den Pfad gesetzt hat, wird Schwierigkeiten bekommen eine generische Lösung hinzubekommen. Hat man diese gesetzt, ist darauf zu achten, das diese vor dem Mount der Datenbanken gesetzt war, sonst wird es schwierig mit dbms_system.get_env() besagte Variable auszulesen.
Hat man den Pfad, baut man am Besten eine External Table auf die Listener.log.Dazu benötigt man aber wieder ein Oracle Directory. Dies sollte man zusätzlich mit einem 'ls' aus der Datenbank heraus auslesen können.
dbms_backup_restore und eine Systemtabelle die via View genutzt werden kann, helfen bei diesen Spiel. Bis auf create directory und get_env übrigens alles nicht offiziell dokumentiert.
Finger weg vom Präprozessor der External Table. Einseits extrem gefährlich wenn Shellscripte so einfach im Filesystem rumstehen und jederzeit unter Oracle aus der Datenbank heraus ausgeführt werden können ( mit welchem Inhalt auch immer) als auch technisch nicht deterministisch bei den diversen Filesystemen in Falle eines 'ls'. Besonders häufig kracht es übrigens bei den Oracle Filessystemen. Dies hängt eigentlich nicht am Präprozessor sondern an den Routinen die Filesystem Daten in den Speicher der Oracle Datenbank mappen.
Man merkt es eben spätestens beim Einsatz eines 'ls' Script unter verschiedenen Filesystemen. Das 'ls ' unter Linux , AIX, HP-UX usw. nicht gleich 'ls' ist, kommt noch dazu.
Hat man nun seine Listener.log am Wickel, sollte man sich Gedanken um ein Verfahren machen, das einen Stand der Listener.log komplett ausliest und ohne großen Act den nächsten Stand. Ein rename über utl_file.rename bietet sich hier an. Aber auch hier wieder Vorsicht. Bitte alle denkbaren dokumentierten und undokumentierten Exceptions codieren, man wird sie brauchen. Bei meiner VM mit Oracle Enterprise Linux klappt zwar der rename, die erfolgreiche Löschung eines Files endet generell mit einer Exception. Das hängt wieder mit dem Filesystem und den Prozessen, welche eine Datei angelegt haben zusammen.Wenn der Listener gerade schreibt und mit man will umbenennen, kann man dies in einen asyn. Job auslagern, der es solange probiert bis es gelingt. Auf intensiv genutzten Datenbanken durchaus überdenkenswert, keine Frage, aber den Kniff gibt es nicht kostenlos;-)
Bei symbolischen Links kann man spätestens unter 11g die External Table haken. Da hilft dann nur noch ein einlesen in die Datenbank.
Wenn man nun herausfinden will, welche location sich hinter der vorliegenden External Table aktuell verbirgt, hilft ein Blick in die Tiefen des Data Dictonary.
Bei den üblichen Verdächtigen samt 'dba_external_tables' sind keine Infos über die Datei ( location) zu finden.
Da hilft nur der simpelste Trick aller Zeiten, der kummuliert einige Tage manuelle Suche in einem Entwicklerleben sparen kann!
select * from dba_tab_columns where column_name like '%LOCATION%';
Wie von Wunderhand erscheint sofort : 'DBA_EXTERNAL_LOCATIONS'
Man kann übrigens die Location ändern.
alter table ext_table location ('new_filename');
Ist dies nun ein Sicherheitsrisiko oder nicht ? Mit dem Präprozessor alle mal. Diesen sollte man systemweit ausschalten können.
Auch ohne Präprozessor ist es ein erhebliches Sicherheitsrisiko. Statt der realen Listener.log, kann eine unverfänglich generierte, modifizierte Datei das Original ersetzen. Bei solchen Angriffen hilft nur ein Auditing der Files auf OS Ebene für die Operationen : read, modify, delete, rename usw. Die Oracle Audit Commands für die Definition und Modifikation der External Table samt Directory sollten zudem nicht fehlen.
Zurück zum Ablauf: Aus Listener.log wird listener.curr oder wenn man auf Nummer sicher gehen will numeriert man die Dinger. Dann liest man die Datei aus und beim nächsten Lesejob benennt man die hoffentlich neue Listener.log wieder um.
Die External Table bleibt solange valid, soweit irgendeine Datei vorhanden ist, die auf Namen in der Definition lautet und entweder die richtige Struktur hat oder leer ist. Dann geht es weiter mit der eigentlich Verarbeitung der gelesenen Daten.
Interessant wird es,wenn eine listener.log die Connect's diverser Instanzen protokolliert. Dies möglicherweise mit unterschiedlichen NLS Settings. Hier eine verteilte Transportarchitektur aufzusetzen kann beispielsweise nach folgender Vorgehensweise erfolgen :
Definition der Vorgaben mit Prio
- Sicherheit ( Ablauf, klassische Security)
- Last auf den Systemen/Performance
- Stabilität
- Ranges für Setter ( Parameter, .. )
...Minimierung der Abhängigkeiten im Gesamtkonzept
Benennungsregeln von Files mit Metadaten im Namen ( Date, Timestamp, ... )
Fallunterscheidung ( Initial, regular workflow, Exceptions/Others )
Umbennungslogik File / Location der External Table
Steuerdiagramm ( Jobs isoliert oder Jobnetz, Others !)Die umbenannte listener.log könnte folgenden Namen besitzen :
listener_2 k0140214154001.log.curr_orcl_inst_id
Durch die Vorgabe, das ein umbenanntes listener.log nicht in einem Rutsch an ein SIEM übertragen werden soll, ergibt sich die Notwendigkeit notfalls ein Backlog aufbauen zu müssen.Gleichzeitig soll dies so flott als möglich bei vertretbarer Last abgeräumt werden. Dies natürlich von allen beteiligten Instanzen, wobei für RAC Instanzen eine höhere Gesamtlast im Beispiel angenommen werden soll als bei durchschnittlichen Singe-Instanzen.
Der Schlüssel für das Loadbalancing könnte die Protokolierung der Endzeiten und die Dauer der Übertragungen sein, die letztendlich ausgetauscht werden.
Durch die meist vorliegenden Logdaten kann eine Instanz erkennen, wie oft sie den so dran ist. Isoliert betrachtet hilft dies überhaupt nicht weiter. Wenn man hingegen die eigenen Durchschittsdaten in die jeweilige listener_20140214154001.log.curr_orcl_inst_id einträgt, z.B. in die letzten 10 Records, kommen die Instanzen allmählich ins Gespräch und können zu einem seltenen aber effektiven Loadblancing führen. Wie Menschen sollten sich die Algorithmen hierfür allerdings nicht aufführen. Dann würde nur noch riesige Backlogs angelegt weil jede Instanz ja so beschäftigt ist.
Die Kommunikation erfolgt über ein ls, der Erkennung der anderen Instanzen nach einer speziellen Init-Phase, dem Umbenennen der Instanz im Dateinamen. Frei nach dem Motto : Ich übernehme mal diesen Task, im Sinne des Ganzen.
Allgemeines :
Da ich Anwendungnn realisere die meist ohne Java in der Datenbank auskommen müssen, bleibt meist nur die Ochsentour über PL/SQL übrig. Hier muss man mitunter undokumentierte Funktion verwenden, die einer besonderen Absicherung in funktionaler als auch sicherheitstechnischer Hinsicht bedürfen. Den günstigsten Pfad durch den Versionsdschungel der Oracle Datenbankversionen zu finden kann Neulinge mit bis zu 10 Jahren Oracle Datenbankerfahrung regelrecht in den Wahnsinn treiben.
Wer das Datum in der Listener.log als statisch ansieht wird Schiffbruch erleiden. Bei lokalen Listenern wird dies zumindest vom Datenbank (Server) Parameter nls_date_format abgeleitet.
Nicht lokale Listener können wieder andere Datumsformate haben. Diese dann in Timestamps mit Timezone zu konvertieren
beschäftigt einen zusätzlich.
Fazit :
Alles recht mühsam und wenn die jungen Leute mit den schicken modernen Programmiersprachen den Artikel lesen würden, bekäme ich zur Antwort : Selbst Schuld! Wahr gesprochen. Irgendwie ist die Luft aus dem Uraltteil Oracle DB raus.
Warum man nicht mit Parametern Directories und Teile bzw. Versionen von Files nicht direkt in den Speicher mappen kann, ist mir unverständlich. Ein parametrierter tail von z.B. listener.log in die SGA sollte ohne große Änderungen möglich sein.
Der Blick über den Tellerrand zumindest für nicht XML Dateien ist etwas bescheiden bei Oracle ausgefallen,
DBMS_LOB und die Quantenmechanik
Ob man DBMS_LOB in SQL oder PL/SQL direkt einsetzt, sind zwei Paar Schuhe. Besonders wenn man sich die Ergebnisse auch noch anschaut;-)
Ein DBMS_LOB.SUBSTR in einem select auf ein CLOB knallt, wenn der interne Buffer ( Parameter 2 ) mehr als 4K benötigt. Packt man z.B. die DBMS_LOB Operationen in eine PL/SQL Funktion, welche z.B. ein CLOB zurückgibt, klappt es und man kann seine Funktion in den Select bzw.die View einbinden.
create or replace function oramon.fm_clob ( p_msg in clob ) return clob
as
lv_out clob;
begin
lv_out :=
DBMS_LOB.SUBSTR( p_msg ,dbms_lob.instr(p_msg,'A :',1,1)-1,1)
||DBMS_LOB.SUBSTR( p_msg , SYS_CONTEXT('UNI_CTX', 'msg_limit')-1000, dbms_lob.instr(p_msg,'A :',1,1) )
||DBMS_LOB.SUBSTR( p_msg , 600, dbms_lob.instr(p_msg,'B:',1));
return lv_out;
end;
/
Wenn man die Historie von Oracle ein wenig kennt, dann liegt der Vermutung nahe, das es bei der Annahme von C als Implementierungssprache mindestens zwei Implementierungen von DBMS_LOB gibt. Eine für die SQL-Engine und eine für die PL/SQL Engine. Was der Sinn einer SQL Implentierung mit 4K Limit sein soll, bei einem Package das eben für Längen bis 32k am Stück oder stückweise mehr, ausgelegt ist, versuche ich nicht zu ergründen. Wenn die Implementierung auf C++ mit Templates basiert, wird die Sache auch nicht sinnhafter.
Verteidigungsschild mit Oracle System Triggern am Beispiel DDL/DCL (new 29.11.2013)
Ein DDL/DCL System Trigger unter Oracle erkennt folgende Befehle samt Metadaten :
- Comment
- Create
- Alter
- Truncate
- Drop
- Rename
- Grant
- Revoke
- Audit
- Noaudit
- Analyze
- ASSOCIATE STATISTICS
- DISASSOCIATE STATISTICS
Neben der Protokollierung all dieser Operationen samt Metadaten ist es nun recht einfach, einen
Verteidigungsschild aufzubauen.
Besonders einfach soll dies am Beispiel einer Datenbank mit kritischen Daten erläutert werden.
Es sollen im laufenden Betrieb keinerlei Privilegien ( System, Object) erteilt werden, welche mit Grant abgesetzt wurden.
Die Protokollierungstabelle soll als oramon.oraddl abgebildet sein.
Schritt 1. Flag für Revoke mit add column an oraddl anfügen.
Schritt 2. Check ob alle dml's gegen oradll via enum dml columns versehen sind.
Schritt 3. Procedure erstellen, welche alle Grant Befehle selektiert bei denen das Revoke Flag null ist.
Mit 'replace(replace(sql_text,'grant','revoke'),'to', 'from);' den Revoke Befehl erzeugen und
via execute immediate absetzen.
Revoke Flag setzenSchritt 4. Job mit isubmit aufsetzen und die procedure einbinden, Zeitinterval z.B. alle 10 Sekunden.
Alternativ per CQN ein Change des Resultset ( mit filter grant ) auf oradll als Event definieren und somit
just in time den grant mit revoke zurücksetzen.
Wer z.B. mehrfach versucht 'grant dba to public' abzusetzen, dem kann man die Session killen, den accout locken und das Passwort erstmal auf impossible setzen via 'Alter user xxx identified by values '€6666666666666666666666666...';
Wenn man Glück hat, kann man den Übertäter noch im Haus erwischen und mit einem mündlichen Revoke die Aufenthaltserlaubnis entziehen. Am besten asynchron über den Sicherheitsdienst.
Neben diesem Trivialbeispiel können Sie mit dieser Technik 'on the fly' erzeugten Procedures/Functions auf die Schliche kommen. Hier muss der Angreifer nicht unbedingt von innen kommen. Es kann der Hersteller sein, der eventuell die berühmte Procedure ' aendere_laborbericht ' adhock erzeugt und nach Ausführung sofort wieder löscht. Diese procedure soll im Beispiel illegal implementiert und nicht dokumentiert sein und dient aussschließlich der Ausführung von Straftaten.
Weitergehendes Monitoring :
Denkbar sind somit Filter, die lediglich bekannte und statische procedure/functions zulässt. Dies dann allerdings nicht über den DDL Trigger sondern mit einen Monitoring Job auf v$sqlarea bzw. v$db_object_cache
Alle statischen procedures/functions die z.B. jünger als Einspielzeitpunkt last-release sind und mit den ausgeführten ( v$sqlarea,v$db_object_cache) vergleichen.
Executions von Objekten mit hoher Anzahl und 0 überwachen. Schläferobjekte können hiermit entdeckt werden.
DDL /DCL Trigger :
Weiterhin können Sie via alter system Dump's von Datenbankblöcken erkennen.
Hier könnte man mit einem OS-Exit den entsprechenden Dump in udump löschen.
Die Möglichkeiten sind schier endlos wenn man die Daten von
- After Logon
- Before Logoff
- After DDL /DCL
- After Error
- After Startup
- Before Shutdown
- After Suspend
- After DB_ROLE_CHANGE
Triggern zusammen betrachtet.
Unter zusätzlicher Einbeziehung bestimmter OS Files via external Tables und Filewatcher ( inotify, auditd ) wächst die Wirkung des Abwehrschildes beträchtlich.
Streng genommen ist all dies natürlich kein Activity Monitoring, allenfalls ein Deferred Activity Monitoring. Bei einer Refresh Time von ca. 1s für die gesamten v$ Views können in der Realität jedoch klassische Angriffe über Privilegieneskalation, on the fly generated procedures und asynchronen Ausspähaktionen effektiv unterbunden werden.
Der Schutz des Abwehrschildes hingegen ist ein ganz eigenes Thema und da wird es richtig interessant.
Tipp : Der Einsatz von System Triggern wird zu Unrecht als gefährlich erachtet
Bezüglich Performance und Datenerzeugung sollte vor allem der After Error Trigger mit Filtern kontrolliert werden.
Viele, wenn nicht nahezu alle Anwendungen unterdrücken Fehler. Somit können gewaltige Datenmengen erzeugt werden.
Umgang mit System Triggern
Generell sollten Sie diese bestens testen. Bei DML Operationen gibt es eigentlich nur eine Empfehlung :
DML in Procedure mit pragma_autonomous_transaction auslagern und vor jedem Call aus Trigger prüfen, ob die Procedure existiert und valid ist. Die Procedure via execute immediate indirekt ausführen, sodaß der Trigger nicht invalid wird, falls ein Scherzkeks diese Procedure entfernt hat. Im Fall des Verlustes der procedure direkt einen Eintrag ins Alert-log via exec dbms_system.ksdwrt(2, 'This message goes to the alert log'); und zwar nicht nur als Alert sondern zusätzlich die Gesamten Daten des Triggers !
Deaktivieren / Aktivieren Sie ihre System Trigger bei Änderungen.
Besondere Aufmerksamkeit sollte man im Umgang von Logon Triggern walten lassen.
Sind diese fehlerhaft kann nur sysdba sich noch einloggen. Ein Autodeactivate wäre hier nicht schlecht.
Falls Sie alle sysdba accounts stillgelegt haben und einen fehlerhaften After Logon Trigger haben, sind sie am Ziel angelangt. Eine Datenbank, in die niemand einbrechen kann;-)
Sqlplus prüft Statements nach Shutdown immediate (new 22.11.2013)
Da arbeitet man seit 27 Jahren mit Oracle und entdeckt immer wieder Neues.
SQL> select * from scott.emp where ename = ''';
ERROR:
ORA-01756: quoted string not properly terminated
Anschließend ein shutdown immediate
Retry der Operation
SQL> select * from scott.emp where ename = ''';
ERROR:
ORA-01756: quoted string not properly terminated
Erst wenn eine Prüfung des Statements duchgeführt wird, die nur in der Datenbank möglich ist,
wird die fehlende Connection erkannt und schießt dann offensicht das Connected Bit um.
SQL> select * from ckredit_card;
select
*
ERROR at line 1:
ORA-01034: ORACLE not available
Process ID: 0
Session ID: 0 Serial number: 0
Anschließend wird sofort die fehlende Connection gemeldet, auch wenn das erste Statement abgeschickt wird.
Ein Cachingeffekt liegt nicht vor, da dies auch dann klappt, wenn vor dem shutdown kein Statement ausgeführt wurde.
Sqlplus prüft den SQLBUFFER auf korrekte SQLPLUS Settings und auf formale Statement Integrität.
Die vemutete Logik : Prüfe generell zuerst, ob die Connection zur Datenbank noch lebt, wird nicht angewandt.
Diese wäre durchaus machbar, wenn die erste Fehlermeldung erst nach erfolgreicher Versendung an die Datenbank
mit nochmaligen Erhalt des 1756 Fehler auf eine Fehlermeldung konsolidiert würde.
Im anderen Fall ' not connected ,... , würde die erste Fehlermeldung unterdrückt.
Was micht stört ist nicht die Prüfung, sondern die falsche Herkunft ORA in der Fehlermeldung.
Mit z.B. SQP - 1756, wäre dies geregelt.
Weiterhin ist mir nicht klar, warum Millionen von Clients nur bei bestehender Verbindung zur Datenbank einen ORA-1756
erhalten und SQLPLUS auch ohne Verbindung.
Da SQLPLUS immer noch das Werkzeug für den SQL Scripte Betrieb ist, sollten solche Ungenauigkeiten bzw. Sonderlocken beseitigt werden.
openACC mit GCC oder accULL sowie AMP Support für Visual Studio (new 16.11.2013)
Compilerdirektiven ( Pragma's) ermöglichen es, Codeteile/Schleifen usw. für Beschleuniger z.B. GPU's automatisiert aufzubereiten.
https://developer.nvidia.com/openacc
openACC 2. 0 ist in GCC integriert
accULL ist ein freier open-source Compiler von der Universität
http://cap.pcg.ull.es/en/accULL
C++ AMP Lib mit Visual Studio Support
Damit lassen sich z.B. PGP Schlüssel, SHA-3 Hashes und Passwort-Checker performant und mit wenig Aufwand für Entwickler beschleunigen.
PGP in der Datenbank wäre mal einen Test wert.
'CONNECT BY PRIOR' und 'WITH' Sortierung (new 15.11.2013)
Wer immer die gleiche Sortierung seiner rekursiven SQL's bei Erhaltung der Hierarchie möchte, muss nicht gleich den Quellcode der Datenbank besitzen.
Die Aufgabe ist einfach. Die Ergebnisse von 'WITH' und 'CONNECT BY PRIOR' sollen in den Versionen 9-11 vielleicht auch 12 exakt identisch sortiert sein. Das Ganze dienst ersteinmal der Schonung der Nerven bei intensiven Tests oder bsp. der Konsistenz ausgefuchster Mustererkennungen im Rahmen von Auswertungen unterschiedlichster Summary Reports.
Hier nun der Klassiker :
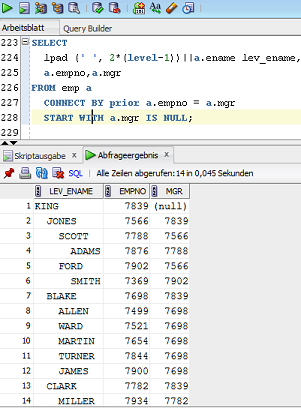
Bei den Ergebnissen bemerkt man, das die Joinspalte empno implizit aufsteigend sortiert verwendet wird.
Dies auf ename zu ändern, kann über den Zusatz ' order siblings by ename' erfolgen.
Die 'WITH' Variante so zu formulieren, das die Ergebnisse identisch zu 'CONNECT BY PRIOR'
sortiert werden , ist nicht schwer.
WITH emp_rec (lev,ename, empno, mgr) AS
( SELECT 1 lev, ename, empno, mgr FROM emp WHERE mgr IS NULL
UNION ALL
(SELECT p.lev+1,
c.ename,
c.empno,
c.mgr
FROM emp_rec p,
emp c
WHERE p.empno = c.mgr
)
) search DEPTH FIRST BY empno
SET g_sort
SELECT lpad(' ',2*(lev-1))||ename,empno, mgr FROM emp_rec ;
Entscheidend ist die Fixierung auf die Tiefensuche und die Fixierung der Suchreihenfolge auf empno.
Die Spalte empno wird natürlich implizit aufsteigend sortiert durchsucht , womit wir exakt unser gewünschtes
Ergebniss erhalten.
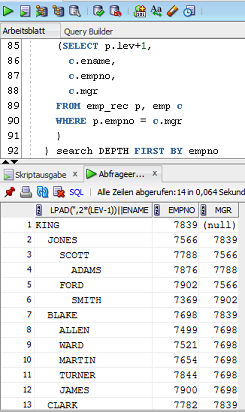
LEAD/LAG und ROW_NUMBER() ein starkes Team (new 14.11.2013)
Bei hierarchischen Abfragen erhält man in der Regel nativ folgendes Muster als Resultset :
Header 1 oder Root 1
Anhängiger Datensatz 1.1
Anhängiger Datensatz 1.2
..
Header 2 oder Root 2
Anhängiger Datensatz 2.1
Anhängiger Datensatz 2.2
..
Für Auswertungen, Vergleiche usw. bietet sich allerdings eher folgende Darstellung an :
Header 1 oder Root 1 - Anhängiger Datensatz 1.1
Header 1 oder Root 1 - Anhängiger Datensatz 1.2
...
Header 1 oder Root 2 - Anhängiger Datensatz 2.1
Header 1 oder Root 2 - Anhängiger Datensatz 2.2
...
Das alte Thema Transpose kommt einem da zwangsläufig in den Sinn.
Nun gibt es mindestens soviele Transpose Lösungen, wie es Oracle Datenbankversionen gibt.
Allerdings haben einige dieser Lösungen einen entscheidenden Nachteil.
Bei größeren Datenmengen wird die Sache teuer, sehr teuer.
Bei der folgenden View , die lediglich eine Teilmenge der Objektpriviligien ermittelt, kommen schon mal einige Zehntausend Privilegien zusammen. Bei dicken Firmendatenbanken, gerade im Bereich Test , werden es
auch schonmal insgesamt mehrere Hunderttausend Privilegien.
Meine Lösung basiert auf dem Einsatz von Analytical Functions, konkret lead/lag sowie row_number() .
Gesagt getan und hier ist die View :
create or replace view some_obj_privs_v2 as
select
obj_or_grantee,
own,
typ,
obj,
gr_typ,
lev,
rown,
CASE
WHEN lev =2
AND grp_nr = 0
THEN row_number() over ( partition BY lev,gr_typ order by rown) -- number generator in window
ELSE grp_nr
END rk,
grp_nr
from
(
select
case when level = 1 then own || '.' || obj || ' (' || typ || ')' else
lpad (' ', 2*(level-1)) || obj || nvl2 (typ, ' (' || typ || ')', null)
end obj_or_grantee,
case when level = 2 then typ||p1 end gr_typ, --- unique key for numbering
level lev,
rownum rown,
own,
obj,
typ,
case
when level =2 and lag (level,1,0 ) over ( order by rownum ) = 1 -- 1 for first record 0 for follower
then 1 else 0
end grp_nr
from
(
/* THE OBJECTS */
select
null p1,
.....
.....
null
from
dba_role_privs
)
start with p1 is null and p2 is null
connect by p1 = prior obj and p2 = prior own
order by rown
);
Die Erläuterung :
Über einen unique key, in diesem Fall das Privileg und der Tablename,( case when level = 2 then typ||p1 end gr_typ ) und durch die Anfangsnummer 1
case
when level =2 and lag (level,1,0 ) over ( order by rownum ) = 1
then 1 else 0
end grp_nr
erhalten wir über
CASE
WHEN lev =2
AND grp_nr = 0
THEN row_number() over ( partition BY lev,gr_typ order by rown)
ELSE grp_nr
END rk,
einen durchnumerierten Bereich von anhängigen Datensätzen (1 - n ) in einem definierten Fenster.
Damit können wir sehr einfach die gewünschte Darstellung abbilden.
select * from
(
SELECT
lag ( own, rk,0) over ( order by rown) owner,
lag ( obj, rk,0) over ( order by rown) object,
lag ( typ, rk,0) over ( order by rown) object_typ,
obj grantee,
typ priv,
grp_nr,
lev,
rown,
rk
FROM some_obj_privs_v2 order by rown )
where lev = 2;
Hierdurch konnte ich auf meinem Uralt Notebook die 4 Minuten Laufzeit für die ursprüngliche Transpose Operation auf wenige Sekunden reduzieren.
Dies gilt natürlich ebenso für die Window Funktion ( partition by ).
Oracle LISTAGG Ersatz (new 13.11.2013)
Wer unabhängig sein muss von Oracle Versionen, der kann mit Listagg(11g) oder wm_concat(< 11g) zwar arbeiten, der Pflegeaufwand der Listings nimmt jedoch deutlich zu.
Daher muss ein einfacher Ersatz her.
CREATE OR REPLACE
PACKAGE str
IS
Buffer VARCHAR2(32767);
Cnt NUMBER := 0;
Grp_sel VARCHAR2(2000):= 'NO GROUP SELECTOR';
FUNCTION cat(
p_buf IN VARCHAR2,
p_delim IN VARCHAR2 default ';',
p_rownum IN VARCHAR2 default cnt+1,
p_grp_sel IN VARCHAR2 default 'flush' )
RETURN VARCHAR2;
FUNCTION get_buf
RETURN VARCHAR2;
END str;
/
CREATE OR REPLACE
PACKAGE BODY str
AS
FUNCTION cat(
p_buf IN VARCHAR2,
p_delim IN VARCHAR2 default ';',
p_rownum IN VARCHAR2 default cnt+1,
p_grp_sel IN VARCHAR2 default 'flush')
RETURN VARCHAR2
IS
BEGIN
IF p_rownum = 1 or nvl(Grp_sel,'*') != nvl(p_grp_sel,'_') THEN
Buffer := '';
Grp_sel := '';
Cnt := 0;
END IF;
Grp_sel := p_grp_sel;
Cnt := Cnt +1;
Buffer := Buffer||p_buf||p_delim;
RETURN Buffer;
END cat;
FUNCTION get_buf
RETURN VARCHAR2
IS
BEGIN
RETURN Buffer;
END get_buf;
END str;
/
Immerhin kann ein Delimiter und ein Group By Selector übergeben werden.
SELECT MAX( str.cat( ename, ';', rownum, mgr ) ), mgr
FROM
( select ename,mgr from emp order by mgr,ename)
GROUP BY mgr;
Entspricht :
SELECT LISTAGG(ename, ';') WITHIN GROUP (ORDER BY ename) AS employees, mgr
FROM emp
GROUP BY mgr;
Result jeweils :
FORD;SCOTT; 7566
ALLEN;JAMES;MARTIN;TURNER;WARD; 7698
MILLER; 7782
ADAMS; 7788
BLAKE;CLARK;JONES; 7839
SMITH; 7902
KING;
null
Privilegien unter Oracle - Schluß mit dem Eiertanz (new 04.11.2013)
Nach einer kurzen Recherche im offiziell überwachten Internet, haben meine Treffer gerademal Rene Nyffenegger und Pete Finnegan ergeben, die das Thema Privilegien unter Oracle ansatzweise beleuchten. Beide Umsetzungen haben etwas für sich, wobei die alten C-Programmierer wahrscheinlich zu Pete Finnegan's Lösungsansatz tendieren werden recursive/functional. Die klassische 'connect by prior' Lösung von Rene Nyffenegger kann erweitert werden, wobei hier Unterschiede in der Abarbeitung/Sortierung bis 10g und ab 11g hervortreten. Dies gilt übrigens auch für 'Connect by prior'
und der Standard 'with' Sortierung wobei diese explizit gesteuert werden kann.
Eine reine SQL Lösung war mein Ziel, sodaß der prozedurale Ansatz ausschied.
Mit System und Objectprivilegien samt rekursiven Rollen ist es nun leider lange nicht getan.
Wer sich die SQL's der Oracle Verwaltungsviews anschaut, wird feststellen, das z.B. PUBLIC und _NEXT_USER ausgeblendet werden. Das es jedoch hiermit eigentlich erst richtig losgeht bezgl. Klassen und Massen von Privilegien, dürfte mit ein Grund sein, warum sich praktisch kaum jemand damit beschäftigt bzw. es niemand nach meinem Kenntnisstand veröffentlicht hat. Es ist auch eine Heidenarbeit.
Die Arbeit darf ich leider nicht veröffentlichen, aber es wird bestimmt ein Produkt geben, das basierend auf allen und wirklich allen effektiven Privilegien für etwas Bewegung im Database Security Markt sorgen könnte. Mein Eindruck war schon immer, das nahezu die gesamte Welt um das Thema Privilegien einen mehr oder weniger großen Bogen machte.
Nun , soviel sei verraten, irgendwann dachte auch ich etwas voreilig, ich hätte alle effektiven Privilegien beieinander, bis mir doch bei einem Test mit sysdba auffiel, das mein Monster recursive SQL diese Privilegien nicht auswies.Verdammte Hacke, das Oracle das Mächtigste und Umfangreichste aller Privilgienansammlungen, nämlich schlicht alle System Privilegien, vollkommen separat verwaltet, war mir temporär entfallen. Die Verwaltung basiert auf einer genialen Kompressionsabsicherung. Ein singulärer Eintrag in der View v$pwfile_users. Die erweiterte Absicherung besteht in dem Nichtvorhandensein einer rowid, welche wie allseits bekannt sein dürfte, in den v$ Views nicht existieren kann, jedoch unter Anwendung einiger streng logischen Operationen bedingte Schlüsse auf erfolgte Änderungen in einer gedachtenTabelle schließen lassen könnte. Mitunter fragt man sich, ob es Oracle wie der NIST geht, die unfreiwillig Mitarbeiter hat, die nie angeheuert wurden.
Die Anbindung der Inhalte der View v$pwfile_users an die Privilegen Map wurde aus Sicherheitsgründen lose gekoppelt vorgenommen. Mann wie Frau muss eben wissen, das die Sonderlocke 'sysdba' alle System Privilegien umfasst. Wer dies nicht weiss hat Pech und weiss auch nicht, welche Möglichkeiten sich damit ergeben. Einfach Genial ! Das Nichtwissende zudem nie tiefer über Namen nachdenken, diese könnten ja ein Fake sein und sysdba nie mit dem System (sys) und der Administration ( dba ) in Verbindung bringen werden, muss offensichtlich ein Naturgesetz sein.Wer es dennoch tut, dem würde vom Support mitgeteilt werden, das dies verboten sei, sofern er denn fragen würde.
select * from sys.system_privilege_map;
Welcher DBA schaut schon regelmäßig in diese Views, es sei denn er nutzt zyklisch Baseline's. Ein einfacher Angriff der einen User sysdba mit dem System Privileg sysdba anlegt, muss in der Hektik des Alltags zudem nicht unbedingt jedem auffallen.
Wer will, der kann auch einen Angriff auf die Baseline SQL's diverser Security Lösungen starten.
create user "SyS" identified by "EvoVIBlackDiamond800PS#";
grant sysdba to "SyS";
select upper(username) from v$pwfile_users; -- Baseline SQL
Dies läßt sich über eine vorgebliche und nicht unwahre Format Function auch noch maskieren.
Und in der Function wird das upper z.B. über ein translate maskiert.
select frm_outp( username ) from v$pwfile_users;
Selbiges für die Baseline's mit user$ und man hat einen eigenen 'Notfall' User, der eigentlich alles kann.
Ein Gott sozusagen oder übertragen auf Oracle, ein Larry Ellison. Und nur "SYS" weiss, das er nicht "SyS" ist.
Tipp :
Sichern Sie ihre Baseline SQL's mit einer Prüfsumme ab und speichern diese mit dem Report in einer separaten
Activity Historie gesichert ab.
Bei professionellen Tools ist dies meist gewährleistet.
Zusätzlich sollten Sie bei Reports und Management Summary Darstellungen gerade bei Usern auf identische Namenseinträge achten!
Weiterhin sei auf die Prüfung der Originalität der Privilegenviews (dba_sys/role/tab/obj ) usw. hingewiesen.
Hier einen via Translate verklausulierten 'Notfall Sicherheits Account ' auszublenden, ist kein Hexenwerk.
Fazit :
Wenn ich dem Datenbankriesen Oracle einen Rat als kleine Einmanneinheit geben darf, dann diesen:
Überarbeitet Euer Privilege / Dictionary Concept von Grund auf und bitte nicht erst in fünf Jahren und ohne Zusatzkosten
für die Kunden.
Wenn man den Spruch ' Da sieht es aus, wie bei Hempel's unterm Sofa' auf Oracle mit seiner Datenbank anwendet, dann würde dies übertragen bedeuten, das etwa 30 Jahre nicht unter dem Sofa geputzt wurde. Das Sofa steht praktisch nicht mehr auf seinen Füssen, sondern wird vom Unrat allmählich in die Höhe gedrückt, allerdings nicht gleichmäßig.
Oder unter dem Riesensportwagen mit 25Metern Länge und 4 Metern Breite verbergen sich 12 Schichten Verspoilerungen wobei nur die letzte aus Carbon ( c) besteht. Der erste Spoiler war übrigens der Klartext für die Komplettverschlüsselung aus Trusted Oracle.
BBS Pseudo Random Generator in Java (new 31.10.2013)
Wer eine Alternative zu den von Datenbankherstellern und Sponsoren eingebauten Pseudo-Zufallsfolgen-Generatoren nutzen möchte, dem sei der BBS Algorithmus hier in einer Java Implementierung empfohlen. Bei Oracle kann dies, soweit Java in der Datenbank genutzt wird, ein genereller Ersatz sein. Ein PL/SQL Wrapper drumherum und fertig.
http://code.google.com/p/randomness-framework/source/browse/trunk/csprng/org/randomness/BBS.java
E-Mail Verschlüsselung und Dateiverschlüsselung für Anfänger Teil 1 ( new 29.10.2013)
Nicht nur für Laien sind funktional umfangreiche Programme wie Mozilla Thunderbird mit seinen vielen Einstellmöglichkeiten der blanke Horror. Der eindimensionalen Funktionsdenke so mancher Community bzw.manches Programmierers gedanklich dauernd hinterher zu hecheln, ist nicht jedermanns Sache. Dann kommt noch ein Plugin names Enigmail hinzu und Sie werden vollends in die Programmiererdenke hineingezogen, ob Sie nun wollen oder nicht.
Wieso haben High-End Hifi Geräte oft nur einen Drehschalter bzw. Kopf und nicht 223 Knöpfe, die auf alle 8 Ebenen wahllos verteilt werden ?
Die Ziel lautet somit : Minimierung des sich Hineindenkens in immer wieder neue und selten konsistente Gebilde mit hunderten von Funktionen, zumindest für Menschen, die verstehen wollen (oder müssen), was sie denn da tun. Oder Sie gehören zu den Glücklichen, die ein gutes Gedächnis haben, und sich absonderlichste Navigationen in dynamischen Menüs als Graph im fotografisches Gedächnis speichern können, notfalls auch verschlüsselt. Die Punktwissen Merker sind somit klar im Vorteil.
Aus didaktischen Gründen werden im folgenden kleine gut verdauliche Häppchen serviert, statt einer kompletten Gans.
Dies ist somit ersteinmal nicht der High-End Vollverstärker mit einem Kopf, aber das ist gewollt bzw. in Ermangelung der Software zwiingend.
Was kann man tun, wenn man Thunderbird + Enigmail nicht nutzen will und trotzdem verschlüsseln will ?
Ersteinmal sollte festgelegt werden, ob Sie komplette E-Mails mit Text und Anhängen verschlüsseln wollen, oder ersteinmal nur die Anhänge ( Dateiverschlüsselung) und mit wem Sie kommunizieren möchten ?
Grundsatz : Aus Prinzip sollten Sie alles verschlüsseln bzw. immer einen verschlüsselten Anhang mit versenden.
Dies dient einzig der Beschäftigung der gigantischen NSA Rechner, die ab einem gewissen verschlüsselten Datenaufkommen nicht mehr hinterher kommen werden mit dem entschlüsseln.
Nehmen Sie beim Anhang Rücksicht auf die mobilen Endgeräte ihrer Kommunikationspartner und deren Internettarif und halten die Dummy Verschlüsselungsanhänge besonders klein!
Als Inhalt im Dummy Anhang eignen sich Geheimdienstwitze :
Auf einem Treffen westlicher Geheimdienste im Schwarzwald will man
herausfinden, welcher der beste ist. Die Agenten bekommen die Aufgabe
gestellt, ein Wildschwein zu fangen. Alle Teams machen sich auf den Weg.
Nach einer Stunde kommen die CIA-Leute zurück. Sie haben einen von Kugeln
durchlöcherten Klumpen Fleisch dabei, der nach einigen Untersuchungen als
Wildschweinkadaver identifiziert wird. "Nicht schlecht", sagt die Jury,
"100 Punkte".
Nach zwei Stunden kommen die Agenten des Mossad zurück. Sie bringen eine
ganze Wildschweinfamilie an, jedes Tier mit einem einzigen Kopfschuß
getötet. "Nicht schlecht", sagt die Jury, "200 Punkte".
Man wartet weiter. Es wird Abend. Kurz bevor die Sonne untergeht hört man
Lärm aus dem Wald. Dann sieht man die BND-Leute ankommen: Vier halten
einen sich verzweifelt wehrenden Hirsch fest, während der fünfte auf das
Tier einprügelt und es anbrüllt: "Gesteh, daß Du ein Wildschwein bist.
Komprimiert und mit AES 256 verschlüsselt samt 20 Stellen Passwort ca. 1kb
Empfehlung : Beginnen Sie ersteinmal mit der symmetrischen Dateiverschlüsselung z.B. für E-Mail Anhänge.
Der E-Mail Text ist in diesem Fall einfach ein Teil des Anhangs oder eben der vollständige Anhang.
Dies setzt voraus, das sie ihren E-Mail Text mit einem Editor/Textverarbeitungsprogramm Ihrer Wahl schreiben und diesen Text ganz normal abspeichern. Das man vertrauliche E-Mail Texte nicht mit Word unter Windows mit Internetanbindung erstellen sollte, versteht sich von selbst.
Am Anfang kann es sinnvoll sein, das Sie ersteinmal nicht die Vollautomatik der Verschlüsselung anstreben. Aus folgenden Gründen :
- Sie wollen vielleicht das Konzept verstehen und die notwendigen Schritte, um Dateien oder komplette E-Mails zu verschlüsseln.
- Sie wollen die Kontrolle darüber haben, mit wem Sie explizit über S/MIME, PGP oder behelfsweise auch über symmetrische Verfahren kommunizieren wollen.
- Sie hassen implizite Kettenaktionen von Software, bevor Sie diese nicht vollständig verstanden haben.
Gerade, wenn Sie kein IT-Profi sind und mit normalen Menschen geschützt kommunizieren möchten, d
kann es sinnvoll sein, mit einer symmetrischen Verschlüsselung zu beginnen. Nicht zuletzt, wegen der Nachvollziehbarkeit.
Dateiverschlüsselung symmetrisch mit 7-Zip - Paranoia Level 0
Begriffe :
7-Zip ist Freeware und mit grafischer Oberfläche für Windows Betriebssysteme verfügbar.
Für Linux gibt es 7-Zip lediglich in einer Kommandozeilenversion
Wine ist eine Linux Bibliothek, die es ermöglicht, viele Windows Programme direkt unter Linux zu starten.
Portable Versionen von Programmen sind Programme die von z.B. einem USB Stick aus gestartet werden können
und damit nicht auf einem Betriebssystem permanent installiert sein müssen.
Symmetrische Verschlüsselung nutzen für Verschlüsselung und Entschlüsselung den selben Schlüssel.
AES-256 ist eines der sichersten symmetrischen Verschlüsselungsverfahren- bisher!
OS steht für Operating System - Betriebssystem Beispiele: Linux, Unix, Android, Windows XP, DOS, CP/M, Symbian, ..
Passwort und Passphrase sind synonym
Bootable Sticks sind USB Sticks von denen Sie Betriebssysteme auf ihrem Rechner/Endgeräte booten können.
GUI bedeutet Graphical User Interface und sinngemäß Grafische Oberfläche - keine Kommandozeile
Dual_EC_DRBG ist ein von der NSA kompromitierter Zufallsfolgengenerator
7-Zip:
Die einfachste Form der Verschlüsselung mit 7-Zip mag belächelt werden, doch sind immerhin AES-256 Verschlüsselungen damit möglich. Ob die NSA den Quellcode von 7-Zip zufällig hat, kann ich Ihnen nicht beantworten.Ein Restrisiko haben sie dadurch, allerdings dürften viele anderen Angreifer ein Problem mit AES verschlüsselten 7-Zip Archiven haben. Mit 7-Zip läßt sich schon etwas anfangen, wenn denn der Schlüsselaustausch bzw.die Schlüsselerzeugung und der Gesamtablauf der Nutzung geregelt ist.
Ein statischer Schlüssel/Passwort über einen längeren Zeitraum zu nutzen, der noch dazu bei symmetrischen Verschlüsselungen hüben wie drüben bekannt sein muss, ist generell problematisch. Sicherer sind kleine Schlüsselberechnungsprogramme, die einen Schlüssel nach einem mehr oder minder cleveren Verfahren erzeugen und nie speichern. Im Beispiel nehmen wir bewußt ein nicht sonderlich sicheres aber hoffentlich anschauliches Beispiel: Der Geburtstag von einer gemeinsamen Freundin z.B. 05.12 also 512 multipliziert mit dem aktuellen Tag 29.10 also 2910 an der Stelle n im Passwort, wobei n die aktuelle Anzahl der Mails sind, die sie mit diesem Kommunikationspartner bislang ausgetauscht haben, solange geteilt durch 2 bis der erste ganzzahlige Rest in 100 - Länge der ersten Multiplikation +1 passt. Der Rest bis zur Gesamtlänge 100 wird mit pseudozufälligen Zeichenfolgen aufgefüllt aber nicht mit Dual_EC_DRBG !
Die Modifikationen nach einem halben Jahr wären bei diesem humoresken Verfahren, einfach der Austausch des Geburtstags und z.B. der Verminderung des aktuellen Tages um die Anzahl der Änderungen, die Sie an dem Verfahren von Anfang an gezählt, durchgeführt haben. Alle Zahlenberechnungen natürlich abs().
Auch wenn die maximale Länge des Schlüssels bei AES-256 32 Zeichen beträgt und mehr Zeichen, bezogen auf die Verschlüsselung, keinen Sicherheitsgewinn bringen, können Sie dennoch längere Schlüssel für 7-Zip nutzen, wenn Sie sich diese dadurch besser merken oder herleiten lassen. Inwieweit 7-Zip den Schlüssel, den Sie eingeben, mehrfach nutzt (Verschlüsselung , Zugang zum Archiv,.. ) ist mir nicht bekannt. Insgesamt betrachtet kann ein Schlüssel mit mehr als 32 Zeichen bei 7-Zip durchaus höheren Sicherheitsgewinn bringen.
Soweit so gut, nur sind auch kleine Programme angreifbar. Daher empfiehlt es sich separate Rechner mit einem simplen Nicht Microsoft Betriebssystem als natives OS ohne Internet Anbindung für die Erzeugung von Schlüsseln und der Verwaltung von E-Mail Merkmalen zu verwenden.
Die Eingabe des Schlüssels muss im Fall von 7-zip nicht manuell per tippen erfolgen, sondern kann über Copy&Paste erfolgen.
Da wir dies tunlichst nicht auf unserem Internet Rechner tun sollten, bleibt wohl nur die Windows XP VM Lösung auf unserem Uraltrechner mit Linux oder die 7-Zip Portable Lösung von einem USB Stick direkt via Wine unter Linux zu laden.
Regel 1: Die Erstellung und Speicherung von Mailtexten sowie die Schlüsselerzeugung, als auch die Verschlüsselung von Dateien sollten auf einem Rechner ohne Internetzugang erfolgen.
Regel 2: Wenn Sie symmetrische Verschlüsselungsverfahren nutzen, verwenden sie nach Möglichkeit nur Einmal-Schlüssel, die generell nicht explizit gespeichert werden. Die Erzeugung dieser Einmal-Schlüssel sollte über ein Programm auf dem Rechner ohne Internetzugang durchgeführt werden und dieses Pogramm muss in seiner Parametrierung mit ihrem Kommunikationspartner abhörsicher abgesprochen werden.
Intervall : z. B. 3 Monate oder 6 Monate
Regel 3: Falls Sie noch kein Programm für die Schlüsselerzeugung besitzen, sprechen Sie übergangsweise einen oder mehrere Schlüssel mit mindestens 20 Zeichen und maximal mehr als 32 Zeichen Länge abhörsicher mit ihrem jeweiligen Kommunikationspartner ab. Begrenzen Sie die Gültigkeit der jeweiligen Schlüssel oder verwenden diese in einem Reihum -Verfahren bzw. anderen Verfahren.
Regel 4 : Ihre Arbeit in elektronischer Form sollte nach Möglichkeit auf einem Nicht-Internet Rechner erfolgen.
Stellen Sie notfalls einen Internetfähigen Notebook oder Altrechner neben den Arbeitsrechner, wenn Sie für Ihre Arbeit im Internet recherchieren müssen.*
* Inwieweit eine Bluetooth Verbindung zwecks Datenaustausch hinreichend abgesichert werden kann, muss ich noch Erfahrung bringen. Ansonsten sollten Sie sich zwei USB Verlängerungskabel kaufen, um die Abnutzung der originalen USB Anschlüsse zu minimieren. Der USB Stick sollte regelmäßig komplett ersetzt werden und mögliche Software, die ab Kauf dort vorliegt sicher gelöscht bzw. mehrfach überschrieben werden.
Einen Brief manuell zu schreiben, kann dauern. Füller einweichen, reinigen, schreiben, Hände waschen, Brief zu kleben, Briefmarke suchen, zur Post gehen da die Briefwaage kaputt ist und checken lassen ob 58 Cent ausreichend sind.
Alternativ schreiten Sie mit der 7-Zip Methode in ihren Panic Room, setzen sich an den Uraltrechner, der mit einem schlank gewählten Minimal-Linux z.B. Liberte Linux rennt, wie ein 72'er Porsche 911 Carrera. Schreiben ihre Mail.unter Linux. Erzeugen entweder Ihren Schlüssel oder kopieren Ihren statischen Schlüssel aus einem PasswordSafe unter Linux , verschlüsseln den Text mit 7-Zip unter Windows XP in der VM oder via Wine vom USB Stick, kopieren das durch 7-Zip erzeugte Archiv auf einen täglich neu 'gefrästen' USB Stick und marschieren zu ihrem Internetrechner.Dann setzen Sie bitte mindestens eine Dummy Mail ab, mit einem Klartext und einem Zip File, in dem z.B.ein kurzer Witz über Geheimdienste verschlüsselt wird. Diese Verschlüsselung sollten Sie ebenfalls auf dem Nicht-Internet Rechner zuvor durchgeführt haben. Wenn wir schon blöffen, dann richtig. Der Klartext der Dummy Mail dienst der Aufmerksamkeit diverser Algorithmen von diversen Dienste, wobei hier nicht die Windows eigenen Bremsassistenten gemeint sind und der Klartext darf je nach Traute auch mutiges enthalten. Vorschlag : 'Diese Mail samt Anhang dient ausschließlich dem Zweck, Rechnern von Geheimdiensten und anderen Abhörern extrem viel Arbeit zu bereiten.'
Anschließend verschicken Sie ihre eigentliche Mail mit dem erzeugten Archiv. Damit Sie hier nicht in den Verdacht geraten, der eigentliche Text sei im Anhang, sollten Sie mindestens zwei schnell geschriebene Klartextsätze mit mindesten 2 aber nicht mehr als 5 Rechtschreib und/oder Tipp Fehlern und z.B. der Ankündigung des endlich rausgegangenen Dankesschreibens im Klartext verankern oder Sie verwenden den mutigen Text aus dem vorherigen Absatz, der generell verwendet, durchaus Sinn machen kann.
Bedenken Sie, das bei jeder Kommunikation Stichworte wie Angebot, Info Broschüre, Bedienungsanleitung, Vertrag, Rechnung und ca. 2 Mio weiteren Begriffen für Dienste interessant sind, die sich mit Wirtschaftsspionage beschäftigen.
Nicht zuletzt sind ältere Privat Bürger für diese Dienste interessant.
Wer die Beschäftigung speziell der NSA Rechner im Visier hat, kann auch eine festgelegte Anzahl von Mails an seinen Kommunikationspartner senden, von denen im einfachsten Fall immer die n-te Mail die eigentliche Information enthält. Wenn Sie also automatisiert oder von Hand genau zehn E-Mails an ihren Kommunikationspartner senden, jede mit einem verschlüsselten Anhang, dann sollte Ihr Kommunikationspartner wissen, das z.B. E-Mail Nr. 7 die eigentliche Nachricht enthält.
Die gerade beschriebene Prozedur hat nur scheinbar den Nachteil, das sie länger dauert als eine klassisch geschossene GUN-E-Mail aus der Hüfte.
Erstens stehen Sie mal auf und beugen so einer Thrombose vor. Weiterhin werden Sie rationalisieren lernen. Das heißt, Sie werden ein oder zweimal am Tag, Mails am Stück lesen und beantworten. Den Rest des Tages können Sie in Ruhe arbeiten., dank der NSA! Voreilig oder gar im Zorn verschickte E-Mails schließen Sie damit ebenfalls aus und die Zeit und Nerven die Sie hierdurch sparen, wiegt den Zeitaufwand für das beschriebene Prozedere bei weitem auf.
Wer es arbeitstechnisch vermag, sollte alles bis auf das E-Mail Handling sowie das Surfen, auf den Nicht Internet Rechner verlagern.Die Zeit die Sie hierbei durch Nicht Surfen sparen, verlängert Ihr Leben deutlich.
Das dies technisch jeweils alles unter Linux als auch unter Windows funktioniert und beide OS alternativ über USB Sticks bootbar sind, und das die meisten Programme vom USB Stick als Portable Version ladbar sind, ist allseits bekannt. Ich empfehle dennoch die strikte Trennung der Hardware in Internet und Nicht Internet Rechner, gerade für nicht so geübte Benutzer. Und selbst der geübteste Profi sollte sich überlegen, welche Folgen ein einziger Fehler in der Abfolge auf dem Rechner haben kann, der zumindest zeitweise Internet Zugang besitzt.
Im Paranoia Level 1-2 wird die VM Software diverser Hersteller als potentiell korrumpiert angesehen.
Daher wird empfohlen, formal abgesichertte VM's auf Internet Rechnern als nicht sicher anzusehen.
Die verwendeten USB Sticks sollten zudem mit Prüfsummen bezgl. des belegten Platzes überprüft werden, da Sie kurzzeitig mit dem jeweiligen USB Stick Kontakt zu Ihrem Windows Internet Rechner haben werden.
Der Gesamtablauf, der bewußt detailliert beschrieben wird, dient nicht nur der Absicherung Ihrer Kommunikation, sondern dem Training mit unterschiedlichen Betriebssystemen arbeiten zu können und dem Prinzip : Teile und herrsche !
Die Abfolge im Workflow beinhaltet die Nutzung von fertigen Programmen mit grafischer Oberfläche die jeweils
einen begrenzten Funktionsumfang besitzen. Die Vorraussetzungen sollten geschaffen sein, um Menschen mit wenig Computer Wissen erste Möglichkeiten der Absicherung ihrer Kommunikation an die Hand zu geben.
Workflow : E-Mail Text als Datei verschlüsseln
Linux starten
GUI-Editor starten
Text eingeben
Text speichern
Text mit einem GUI-Verwaltungsprogramm archivieren
optional mit unix2win konvertieren
USB Stick mit 7-Win Portable in Linux Rechner einstecken
7-Zip unter Linux von USB via Wine starten
Die erstellte Textdatei in 7-Zip zur Verschlüsselung hinzufügen
optional weitere Dateien (Anhänge) hinzufügen
Option AES-256 Verschlüsselung unter 7-Zip auswählen
GUI-Schlüsseltresor starten mit passphrase!
Schlüssel aus Schlüsseltresor via copy&paste in 7-Zip Password kopieren
Nachschauen, welche E-Mail Nr. Sie mit Ihrem Kommunikationspartner als die reale festgelegt haben.
Alle Dateien verschlüsseln und Archiv auf USB Stick speichern
Mit USB Stick zu Internetrechner gehen und dort den Stick einstecken
E-Mail Programm starten
for i = 1 to n ( minimal 2 Mails direkt hintereinander bzw. in max. einer Stunde )
Adressat auswählen und Klartext ( Fake ) eingeben bzw. copy&paste
Verschlüsseltes Archiv ( Fake oder Real ) von USB Stick als Anhang laden
E-Mail versenden
end
Verschlüsseltes Real Archiv auf bel. Rechner redundant bzw. mit Online Backup archivieren
Verschlüsselte Archive auf USB löschen bzw. überschreiben.
Neues Fake Archiv aufspielen ( Vorratsdatenspeicheung )
Workflow : E-Mail abrufen und entschlüsseln
Windows E-Mail Programm starten
Check ob Virenscanner eingeschaltet ist
E-Mails abrufen
Verschlüsseltes Archiv auf USB Stick herunterladen
USB Stick auf Viren, Trojaner, AdAware usw. prüfen
Mit USB Stick zu Linux Rechner gehen
USB Stick einstecken
7 Zip Portable unter Linux via Wine laden
Archiv von USB auswählen und entschlüsseln starten
Schlüsseltresor starten
Schlüssel auswählen und mit copy&paste in 7zip übertragen
Dateien entschlüsseln
Entschlüsselte E-Mail Text Datei mit Editor anzeigen -
Entschlüsselte Dateien mit Verwaltungsprogramm archivieren
Verschlüsseltes Archiv von USB Stick löschen bzw. überschreiben
Hier die Liste der notwendigen Software:
- Linux z.B. Liberte Linux
- Linux Editor z.B. Leafpad oder GEdit
- Linux Schlüsseltresor z.B. KeePass Password Safe
- Linux Wine
- Windows 7-Zip Portable oder nativ
Alternativ :
- Vmware Player for Linux
- VirtualBox for Linux
- Windows XP
Optional :
- Linux unix2win
- Linux Text Archivierung z.B. ecoDMS
Das erwähnte Programm für die Schlüsselerzeugung wird derzeit unter Linux entwickelt und benötigt folgenden Input von Anwenderseite :
Die E-Mail Adressen Ihrer Kommunikationspartner sollten dort hinterlegt sein.Sämtliche Schlüsselerzeugungen für eine einzelne E-Mail Adresse muss über dieses Programm erfolgen, da ein simpler Zähler der eigentlichen E-Mail zu einer Adresse für die Zuordnung auf beiden Seiten notwendig ist.
Die Anzahl der Schlüsselexporte ( copy&paste) wird gezählt.
Die Anzahl der Real-Mails wird gezählt.
Die Anzahl der Dummy Mails sollte, wenn dieses Feature genutzt wird, ebenfalls nur über dieses Programm festgelegt werden.
Den folgenden Absatz sollten die meisten überspringen, es sei denn, Sie vertrauen keinem US-Produkt mehr nach 1994.
Dateiverschlüsselung unter DOS- Eigenbaulösung, Paranoia Level 5 aufwärts bis Snowden Max!
Paranoia Level 5 auf der nach oben offenen Snowden Scala, veranlasst mich ein DOS Programm zu erstellen, welches nichts anderes ist, als die Portierung des AES-256 oder besser noch des Original Rijndael Algorithmus.Dieses Programm ist eingebettet in eine DOS VM und jedem, der sich mit DOS noch halbwegs auskennt, muss eigentlich nur das erhaltene Kryptogramm / Datei in die DOS Box transferieren und eine Batchdatei starten und es erfolgt die Entschlüsselung samt Anzeige in einem DOS Editor. Dort kann anschließend ein neuer Text erstellt werden und dieser wird mit dem Eiinmal-Schlüssel für Ihren Kommunikationspartner verschlüsselt.
Nachteilig an dieser Lösung kann das Schlüsselmanagement sein. Prinzip bedingt, gib es bei symmetrischen Verschlüsselungsverfahren nur einen Schlüssel, der somit an beiden Enden der gewollten Kommunikation bekannt sein muss.
Statische Schlüssel per Telefon, Handy, oder gar im Klartext per Mail auszutauschen, empfielt sich nicht. Ab Paranoia Modus 6 sollten Sie zudem das persönliche Treffen bevorzugen, allerdings nur in Wohnungen in denen keine Möbel eines schwedischen Herstellers auf Sie warten und in denen keine aufwendigen Whisky Flaschen und besonders deren Verpackungen anwesend sind.Die Spielekonsolen aus Amerika sollten Sie vorrübergehend in den Heizungsraum stellen.
Das simple DOS Programm ist eben nicht ganz so simpel. Die Hauptarbeit steckt in der Verwaltung und Berechnung eines Schlüssels nach einer Grundregel und diversen Parametern ( alle auf einer DOS Maske, schön geordnet). Die Grundregel und die Parameter sollten Sie mit Ihrem jeweiligen Kommunikationspartner zyklisch neu festlegen und austauschen. 32Bit unsigned Integer samt Arithmetik sollte natürlich performant abgebildet sein, damit AES praktikabel wird.
DOS wird deswegen verwendet, da es als vergleichsweise sicher gegen Angriffe von außen eingestuft werden kann. Dies gilt für das OS und besonders für Compiler, Linker sowie die Bibliotheken. Das ältere DOS Versionen auch mal abstürzen, wissen Sie sicher nocht. Ab 2.11 ging es nach meiner Erinnerung so einigermaßen.
Ja, ich habe sie noch fast alle alten unverseuchten Entwicklerwerkzeuge. Diese sind bestens gesichert und redundant im Odenwald verteilt !
Lattice-C,Power-C, Watcom-C, Microsoft-C, Turbo-C, usw. samt Linker und besonders die nicht kompromitierten Bibliotheken.
Dateiverschlüsselung mit PGP, Paranoia Level 0
Wesentlich weniger Aufwand für den Programmierer verursacht die Dateiverschlüsselung mit PGP.
Erste Regel : Windows ist nichtvertrauenswürdig.
Zweite Regel : Linux ist nicht vertrauenswürdig, allerdings mehr als Windows.
Dritte Regel : Niemals den geheimen Schlüssel auf Windows Systemen speichern.
Installieren Sie das GnuPGP Package auf Ihrem Linux Rechner oder der VM und erstellen sich einen Schlüsselbund.
...
Multilevel secure database encryption with subkeys
Das in China mittlerweile langlebigere Uhren gebaut werden können, als die bekannten Edelhersteller es vermögen,
wird Ihnen jeder unabhängige Uhrenexperte bestätigen. Ein Grund ist übrigens härteres Material z.B. beim Stahl.
China kann allerdings auch im Bereich Database encryption ein System präsentieren, das ich zumindest noch nicht kannte.
Hierarchisch angeordnete Keys und Subkeys können nicht nur auf Datensatzebene sondern auf Spaltenebene mit vertretbaren Aufwand bei der Schlüsselverwaltung feingranulare Zugriffskonzepte samt Entschlüsselung abbilden.
http://mshwang.ccs.asia.edu.tw/www/myjournal/P007.pdf
Oradebug fix - disable standard auditing / sysoperations
Oracle hat einen Fix anzubieten und dieser existiert offensichtlich schon seit 9 Monaten
Die Menge der allseits bekannten undokumentierten Funktionen von Oradebug lassen sich offensichtlich mit 'restricted' explizit, aus Sicht von Oradebug, ausblenden. Der Befehl 'poke', aus Sicht von Oradebug, ist nach wie vor in den Lib's der Oracle Datenbank enthalten !
Zur Erinnerung : Mit oradebug poke address 0/1 kann z.B. das Oracle Auditing komplett und nicht mit Standardfeatures nachvollziehbar, ausgeschaltet und nach dem eigentlichen Angriff wieder eingeschaltet werden.
Meine Empfehlung an Oracle lautet : Vollkommene Entfernung der Funktionalität von 'poke' und anderen undokumentierten Funktionen aus den Libs der Oracle Datenbank. Ein Notfall OS Package ( orapush) kann bei Bedarf nachinstalliert werden. Nach Behebung des Notfalls wird dieses Package nach Security Standards sauber und rückstandsfrei deinstaliiert.
Von einer geschlossenen Lücke kann damit nur bedingt die Rede sein. Inwieweit z.B. der Parameter
'_sixteenth_spare_parameter
' oder andere den undokumentierten 'poke' Befehl aus einer anderen Oracle Anwendung ermöglichen bzw. 'poke' einfach nur einen anderen und bisher nicht bekannten Namen besitzt, wissen wir derzeit nicht.
Zudem steht der Default bei Parameter
'_fifteenth_spare_parameter' auf 'all', wodurch trotz Fix, die Abschaltung des Auditing möglich ist!
Ist Oracle 12c durch SHA-2 angreifbar ? ( update 07.10.2013)
Warum
Oracle in der neuen Version 12c lediglich SHA-2 ergänzend im Crypto-Package anbietet und selbigen für das
Password Handling nutzt und zusätzlich nicht SHA-3, könnte man böswillig als
vorbereitete Hintertür bezeichnen. Wie allgemein bekannt sein dürfte,
sind die erfolgreichen Angriffe gegen MD5 /SHA-1 auch gegen SHA-2
durchführbar. Die Algorithmen gehören zu einer Familie und SHA-2
unterscheidet sich hauptsächlich durch längere Hashwerte bzw. größere
Schlüsselräume von seinen Vorgängern.
Die bisherige Aussage der NIST, SHA-2 sei nach wie vor sicher, ist zumindest nach den letzten Tagen ( Stand : 11.09.2013) nicht mehr viel wert.*
SHA-3 gehört nicht zu dieser Familie und ist zumindest gegen diese Angriffe gefeit.
Im Januar 2011 wurde Keccak ( SHA-3) final beschrieben und im Sommer 2012 zum Nachfolger von SHA-2 gekürt. Oracle 12c wurde Mitte 2013 veröffentlicht. Zeit genug war also.
Hier ein Link auf die Beschreibung von Keccak / SHA-3
http://sponge.noekeon.org/CSF-0.1.pdf
sowie einer Untersuchung von 14 Java Implementationen von Hash Funktionen sowie deren Performancr als Kandidaten
für SHA-3 (2010)
http://www.diva-portal.org/smash/get/diva2:347979/FULLTEXT01.pdf
Tipp : Besorgen Sie sich genau die Source von Keccak, die jahrelang weltweit erfolgreich getestet wurde. Die NIST plant die 384 und 512Bit Varianten aus dem Standard zu nehmen.
http://keccak.noekeon.org/ -> Software and other files -> Reference and optimized code in C
Kalkulieren Sie die Möglichkeit ein, das SHA-2 von der NSA geknackt wurde!
Zwei bislang berechtigte Security Empfehlungen für Oracle Datenbanken wanken nun.
- Vermeidung von Java in der Datenbank
- Vermeidung von external procedures
Nach dem Prinzip des kleineren Übels, plädiere ich nun bei kritischen Code für den Einsatz beider Optionen.
Eine C-Library, die sich und die Listener bei Benutzung ersteinmal selbst überprüft, kann generell bei allen kritischen Programmteilen eingesetzt werden. Java in der Datenbank sehe ich eher als vorläufige Lösung, um sich aus der Abhängigkeit des Oracle Funktions-Universum partiell befreien zu können. Externe Java Aufrufe werde ich noch testen.
Einen angenehmen Nebeneffekt gibt es im Fall des Einsatzes von C-Libs zusätzlich. Der Quellcode von PL/SQL und Java muss zumindest für die dort implementierten Teile nicht mehr geschützt werden.
* Die NIST räumt die rechtlich erzwungene Zusammenarbeit mit der NSA ein. Dies als direkte Folge des Beweises
einer Implementierung einer Backdoor in dem Pseudo Random Generator DUAL_EC_DRBG.
Sichere Erzeugung von Schlüsseln und deren Speicherort
Ein
Kommentar in einer bekannten Zeitung hat mich wieder an die Problematik
der Schlüsselerzeugung erinnert. Auch nach meiner Erfahrung werden in
Oracle DB's sehr häufig die Packages dbms_random und dbms_crypto benutzt, um Schlüssel
für z.B. AES oder andere zu erzeugen. Wenn jemand die Deterministik der
genannten Packages / pro Datenbankversion stochastisch ermitteln kann,
dann jener Dienst, der offensichtlich sogar den Papst bei seinem
Gesprächen mit dem Herrn abhört. Ob dieser Dienst die Leistung überhaupt
aufbringen muss, sei dahingestellt. Quellcode lesen und verstehen,
könnte diesen Schritt überflüssig machen. Aufgrund der begrenzten Länge
der Schlüssel, auch bei AES mit 256 Bit, kann ein schlechter
Zufallszahlengenerator eine signifikante Schwachstelle nicht nur bei der
Schlüsselerzeugung sein. Wie stark die intern verwendeten
Zufallszahlengenerator für ihre genutzte Implementationen der jeweiligen
Verschlüsselungsverfahren korrumpiert sind, weiss fast kein Mensch. Man
sollte sicherheitshalber vom schlechtesten Fall ausgehen, oder an Herrn Keith Alexander eine Anfrage adressieren. Selbst ein Larry Ellison darf dazu nichts sagen!
Da beí symmetrischen Verfahren die Schlüssellängen nicht besonders lang sind, empfiehlt sich bei Verdacht des Einsatzes von deterministischen Zufallgeneratoren eine asymmetrische Verschlüsselung z.B. PGP.
Dort empfehlen vorsichtige Zeitgenossen schon Schlüssellängen von 4096-Bit oder mehr, damit auch NSA-Cluster in schwitzen geraten. Wie man übrigens asymmetrisch in einer Datenbank verschlüsselt,wird in einem separaten Artikel beschrieben.
Eine simple Überlegung soll hier nochmal wiederholt werden.
Wenn bisher vergleichsweise nur eine verschwindend geringe Menge an Daten und Mails überhaupt verschlüsselt sind, kann die NSA ihre exorbitanten Rechnerleistung genau auf diese Verschlüsselungen ansetzen.
In dem Augenblick, in dem die Bürger und Firmen viele, eventuell gar alle Mails und einige Daten in Datenbanken verschlüsseln, bricht die beschriebene Erfolgsquote der Entschlüsselung derart drastisch ein, das dies regelrecht als Sicherheitskonzept anzusehen ist.
Wieso ich jetzt die Mails mitbetrachte ?
Ganz einfach: Die Vorarbeit für Wirtschaftsspionage erfolgt meiner Meinung nach über das Abhören von Mails, Telefonaten, Surfverhalten usw.. Bevor ein verschlüsseltes Datum aus Ihrer Firma zur NSA gelangt, müssten demnach viele verschlüsselte Mails entschlüsselt sein. Zumindest für diese Form der Angriffe, würde die asymmetrische Verschlüsselung von Mails und Firmendaten in Datenbanken Sinn machen.
Automatisiert erstellte verschlüsselte Dummy Mails können diesen Effekt sogar forcieren.
100 Dummy Mails mit 8192 Bit Schlüsseln und eine reale Mail, das ist nur eine Maßnahme gegen die Überwachung!
Die
Erzeugung von Schlüsseln abgeleitet aus dem eigenen erreichbaren
Datenuniversum kann ein Vorteil für Firmen mit großen Datenmengen sein,
für kleinere Firmen oder Privatpersonen läuft es jedoch auf richtige
Zufallszahlen Generatoren hinaus. Alternativ wird die Methode der PUF's '-Physical
unclonable functions' wird im Vortrag der NIST - siehe unten - näher
erläutert.
Die Speicherung der Schlüssel sollte nach Möglichkeit nicht in der Datenbank erfolgen. HSM's könnten ein guter Ort sei, wobei der Zugriffscode disjunkt von Features und Produkten der Datenbankhersteller gehalten werden sollte. Alternativ sollten Sie den Code selbst entwickeln und von mindestens zwei unabhängigen Security Spezialisten, die mit mindestens einem Finger pro Spezialist für ihre Ehrlichkeit Ihnen gegenüber haften, prüfen lassen.
Tipp : Versuchen Sie die Risiken für die Sicherheit Ihrer Daten mit Phantasie,
dem
Einsparpotential an Aufwand gegenüberzustellen, den mitgelieferte
Funktionen bzw. Features der Datenbankhersteller im Modus 'schnell,
schnell' suggerieren.
Für
mich verbietet es sich daher, irgendein kostenpflichtiges Security
Feature bzw. Option der Datenbankhersteller in der eigenen Datenhaltung
einzusetzen, wenn ich den Oracle, IBM oder MS überhaupt nutzen würde.
Um
es auf den Punkt zu bringen. Ich schreibe sogar eher eine eigene
Implementierungen von Security Algorithmen z.B. Rijndael statt AES und
binde diese über eine externe Bibliothek in das Datenbanksystem ein, mit allen
Konsqeuenzen bezgl. Absicherung, die damit bekanntlich einhergehen.
Wer es professionell angehen will, dem sei folgender Vortrag als theoretischer Einstieg für PUF's empfohlen.
Secure Key Storage and True Random Number Generation
http://csrc.nist.gov/groups/ST/key_mgmt/documents/Sept2012_Presentations/STRUIK_NIST_KMW_2012.pdf
Die 'neuen' Erkenntnisse der NIST sollen nicht verschwiegen werden
NSA-Affäre: Generatoren für Zufallszahlen unter der Lupe 10.09.2013
NIST lässt Zufalls-Generatoren neu prüfen 11.09.2013
http://www.heise.de/security/meldung/NIST-laesst-Zufalls-Generatoren-neu-pruefen-1954677.html
Zitat Bruce Schneier (15.11.2007)
'My recommendation, if you're in need of a random-number generator, is not to use Dual_EC_DRBG under any circumstances. If you have to use something in SP 800-90, use CTR_DRBG or Hash_DRBG.'
2013 wurde der Beweis erbracht, das die NSA gezielt eine Backdoor in DUAL_EC_DRBG durch den Standardisierungsprozess implementierte.Bedenken Sie, das seit der Empfehlung für CTR_DRBG und Hash_DRBG fast 6 Jahre vergangen sind!
________________________________________________________________________________________________________
Oracle DB Security Top 30
- Standard Passwörter ändern
- Niemals Username = Passwort !
- Hinreichende Passwortkomplexität je nach Userkategorie + weak Passwort Check
- Einführung von Oracle User-Profile und Passwort Verfification Functions
- Unnötige Accounts löschen, sperren bzw. mit unmöglichem Passwort versehen
- Aktuelle Oracle Patches ( CPU's, ...) einspielen
- Data Dictionary absichern
- Listener absichern mit Fallunterscheidung bis 9i, ab 10g
- Glogin.sql absichern gegen Angriffscode
- Shell History unterbinden bzw. löschen
- Unterbinden Sie Remote OS Authentification
- Check aller Exports, Backup's, Redo Logs, Traces, Audits, ... auf Klartext Passworte
- Check auf Identitätswechsel - become user implizit, explizit
- Keine Hinterlegung von Passworten in Skripten/Programmen
- Passwortänderung nur über den SQLPLUS Befehl : password
- Revoke gefährlicher Packages from Public - UTL_TCP, ....
- Check auf Verwendung von Execute immediate, DBMS_SQL, DBMS_SYS_SQL,...
- Ausschluß von SQL-Injection durch die richtige Verwendung von dbms_assert / binds
- Transportverschlüsselung SQL-Net Listener
- Logon/Logoff/Error/DML/DDL Database Trigger einführen
- Unsichtbare User erkennen bzw. update über DML Trigger abfangen
- Least Privilege static - sowenig Rechte wie möglich oder erstmal keine -siehe unten
- Least Privilege dynamic optional mit Aktivität - z.B. VPD,Database Vault, Hedgehog
- Klassifizierung Ihrer Daten bzgl. Kritikalität/Schutzbedarf
- Einführung Protokollierungsstandard
- Trennung Datenbankadministration und Data Mining der Protokolldaten
- Data Mining - Trennung von Policy Verstößen und Forensik
- Check ob in/transparente Datenverschlüsselung sinnvoll (Crypto/TDE + HSM's)
- Check ob externe Authentifizierungsdienste sinnvoll z.B. Kerberos, Radius
- Check auf Kopien kritischer Tabellen ( System - Produktion )
Der theoretische Tipp, Kleinbuchstaben unter 11g als Passwortbestanteil zu
erzwingen lassen wir hier außen vor. In Umgebungen mit bis 10000 Oracle
Instanzen und tausenden von Anwendungen, die überwiegend bis Version 10g
entwickelt wurden, kein realistischer Tipp.
User Passworte mit 10-12 Zeichen und nach Test der Anwendungen zusätzlich
mit Sonderzeichen schon eher!
Komplexität der Oracle Passwörter 10g / 11g
Ein User-Passwort mit 7 Stellen welches mit A beginnt, wie z.B. ANNETTE, kann vergleichsweise schnell zu ermitteln sein. Mit einem ausführlichen Brute-Force Vorgehen ( systematisch alle Zeichenkombinationen bilden), kann man die Rechenzeit auf etwa 4 Minuten begrenzen, wenn im Passwort lediglich Großbuchstaben enthalten sind. Wenn gar gegen eine Tabelle mit Standard Passwörtern vorab abgeglichen wird, u.a. mit Frauennamen, ist das Beispiel-Passwort in wenigen Sekunden geknackt. Mit 8 statt 7 Stellen und Großbuchstaben ist das Passwort in ca. 1,5 Stunden geknackt, also auch kein Hexenwerk.
Bis Version 10g der Oracle Datenbank, konnte man leider keine Kleinbuchstaben für ein Passwort verwenden, da das Passwort vor der DES-Hash Berechnung generell auf Großbuchstaben konvertiert wird. Durch die Verwendung von Zahlen und Sonderzeichen erhöhen sich allerdings die Knackzeiten deutlich, dennoch ist bis zu 8 Stellen die Rechenarbeit der schnellsten Knackprogramme in wenigen Tagen geleistet.
Bis Version 10g sind Passworte erst oberhalb von 9 Zeichen, also 10 Zeichen oder mehr, und nur unter der gesicherten Verwendung von Großbuchstaben, Zahlen und Sonderzeichen halbwegs sicher bezgl. Angreifern die mit Knackprogrammen und DES-Hashes arbeiten.
Wählen Sie keine Namen von Menschen und Dingen die man mit Ihnen in Verbindung bringt als Passwort oder Passwort Bestandteil !
Die erwähnte 'gesicherte Verwendung' wird über eine Password Verification
Function erreicht.
Die maximale Passwortlänge bei Oracle beträgt in allen Versionen 30
Zeichen
Mit Version 11g von Oracle gibt es endlich die Möglichkeit das Password Case-sensitive einzugeben, also auch mit Kleinbuchstaben. In Verbindung mit den Zahlen von 0-9 ergibt sich allein hierdurch ein 62 Zeichenvorrat für die Erstellung des Passworts.
Wie stark der Aufwand für Angreifer mit Case Sensitive zunimmt, zeigen folgende Zeiten, die auf mittleren Rechnern jedoch mit den schnellsten Knackprogrammen ermittelt wurden.
SHA-1 :
8 Zeichen Passwort aus 62 Zeichenvorrat ( Groß/Klein+Zahlen) läßt sich ca. 3,2 Tagen knacken. Mit 9 Zeichen dauert es schon 201 Tage !
Damit nicht genug, man kann zusätzlich viele Sonderzeichen in einem Passwort verwenden.
Es soll nicht verschwiegen werden,
das auch mit den älteren Oracle Versionen bis 10g
viele Sonderzeichen im Passwort verwendet werden können.
Da die neueren Algorithmen der SHA-1 Erzeugung performanter sind, als diejenigen
für DES, kann allein mit der zusätzlichen Verwendung von Sonderzeichen und
einer Passwortlänge > 10 Zeichen für eine 10g eine höhere Sicherheit im
Vergleich zu einer 11g erzielt werden, soweit eben keine Kleinbuchstaben
genutzt werden.
Um ein Password mit 10 Stellen aus Großbuchstaben und Zahlen zu knacken
benötigt man
via DES 1,5 Monate mit SHA-1 etwa 2 Tage.
Erst mit der Verwendung von Kleinbuchstaben wendet sich das Blatt zu
Gunsten des SHA-1.
Passwort 10 Stellen aus 62 Zeichen verursacht aktuell etwa 34 Jahre
Rechenaufwand.
Bei 11g sollte in jedem Fall die Verwendung
von Kleinbuchstaben für Passwörter aktiviert und erzwungen werden.Setzen Sie
hierzu den init.ora Parameter auf :
Dieser Tipp muss leider durch den wenig praktikablen
Workaround für den
O5LOGON Cryptographics Flaw, zumindest für 11g revidiert werden !
SEC_CASE_SENSITIVE_LOGON = FALSE
Mit einer Verification Function welche mit den
entsprechenden Profile verknüpft wird, kann die Verwendung von Kleinbuchstaben
erzwungen werden.
Ein Beispielpasswort könnte folgendermaßen aussehen:
"kA0#$8Sz_oOpeR"
Nicht einfach zu merken, aber man kann sich ja helfen.
"Bu#lg#ar#ie#n2007"
65 ^7 ( Groß/Klein-Buchstaben/Zahlen/ #$_ ) ergibt einen Vorrat an
4.902.227.890.625
verschiedenen möglichen Passwörtern.
Zum Vergleich sind die 7 Stellen aus Großbuchstaben mit etwas mehr als 8 Milliarden Kombinationen keine große Herausforderung für den einfachsten Netbook.
26 ^7 ergibt einen Vorrat an
8.031.810.176
Kombinationen.
Eingabe des Passworts und Abhängigkeiten vom Zeichensatz
Die Eingabe des Passworts erfolgt reguär über den/die Befehl(e) :
create/alter user <user> identified by <pwd>;
Um einen User anzulegen mag das ja noch angehen.
Eine böse Falle gibt es übrigens ganz regulär schon seit Ewigkeiten bei Oracle
grant create session a, b, c identified by a,b,c;
legt die User auch gleich mit dem Privileg an, falls diese nicht schon existent sind.
Gefährlich wird es, wenn Sie solche Befehle in Scripten haben
grant dba to a,b,c,d,e identified by a,b,c,d,e;
Welche User sind tatsächliche Kandidaten für die DBA Rolle und schon existent
und welche nicht ?
Vermeiden Sie in jedem Fall die Änderung des Passworts über 'alter user'.
Stattdessen verwenden Sie besser den SQPLUS Befehl : password
Dieser wird das neue Passwort nicht anzeigen und es kann daher nicht mitprotokolliert werden. Wichtiger noch ist die Verschlüsselung des Passworts bei der Kommunikation mit der Datenbank.
Ändern Sie nach Anlage der User zeitnah die Passwörter mit 'password'.
Für beide Varianten gilt :
Wenn Sie das Passwort nicht mit Double Quotes einkleiden, sind u.U. eingeschränkte Kombinationen von Zeichen im Passwort möglich.
Um alle gültigen Zeichen im Passwort verwenden zu können, benutzen Sie bitte folgende Syntax :
create user KA identified by "10gDES_11gSHA-1";
SQL>
password
Kennwort für KA wird geändert
Altes Kennwort:
Neues Kennwort:
Neues Kennwort erneut eingeben:
Kennwort geändert
Neues Kennwort : "IdealStandard#4KS"
Die gültigen Zeichen hängen in letzter Instanz vom verwendeten Zeichensatz in der Datenbank ab.
Hier ein Programm zur Ermittlung aller ungültigen und gültigen Zeichen für ein Passwort in Abhängigkeit vom Zeichensatz NLS_CHARACTERSET in einem vorgegebenen Bereich von ASCII Zeichen.
Aufruf :
exec check_pwd_chr ( 33, 254 );
CREATE OR REPLACE
PROCEDURE check_pwd_chr(
p_from IN NUMBER,
p_to IN NUMBER )
IS
lv_valid VARCHAR2(2000);
lv_not_valid VARCHAR2(2000);
lv_nls_char_s VARCHAR2(30);
lv_cnt pls_integer;
ecode NUMBER;
emesg VARCHAR2(200);
BEGIN
lv_cnt := p_from;
SELECT value
INTO lv_nls_char_s
FROM nls_database_parameters
WHERE parameter = 'NLS_CHARACTERSET';
<<my_loop>> WHILE lv_cnt <= p_to
LOOP
BEGIN
EXECUTE immediate 'alter user a identified by
"'||chr(lv_cnt)||'"';
EXCEPTION
WHEN OTHERS THEN
BEGIN
ecode := SQLCODE;
emesg := SQLERRM;
dbms_output.put_line(TO_CHAR(ecode)
|| ' ' || emesg);
lv_not_valid := lv_not_valid||'
'||chr(lv_cnt);
lv_cnt := lv_cnt+1;
GOTO my_loop;
END;
END;
lv_valid := lv_valid||' '||chr(lv_cnt);
lv_cnt := lv_cnt+1;
END LOOP;
dbms_output.put_line
('NLS_CHARACTERSET : '||lv_nls_char_s);
dbms_output.put_line ('INVALID PWD CHARACTERS : '||lv_not_valid );
dbms_output.put_line ('VALID PWD CHARACTERS : '||lv_valid );
END;
/
Ausgabe :
-1741 ORA-01741: Unzulässiger Bezeichner mit Länge Null
NLS_CHARACTERSET : WE8MSWIN1252
INVALID PWD CHARACTERS : "
VALID PWD CHARACTERS : ! # $ % & ' ( )
* + , - . /
0 1 2 3 4 5 6 7 8 9
: ; < = > ? @
A B C D E F G H I J K L M N O P Q R S T U V W X Y Z
[ \ ] ^ _ `
a b c d e f g h i j k l m n o p q r s t u v w x y z
{ | } ~ € ‚ ƒ „ … † ‡ ˆ ‰ Š ‹ Œ Ž ‘ ’ “ ” • – — ˜ ™
š › œ ž Ÿ ¡ ¢ £ ¤ ¥ ¦ § ¨ © ª « ¬ ® ¯ ° ± ² ³ ´
µ ¶ · ¸ ¹ º » ¼ ½ ¾ ¿ À Á Â Ã Ä Å Æ Ç È É Ê Ë Ì Í Î
Ï Ð Ñ Ò Ó Ô Õ Ö × Ø Ù Ú Û Ü Ý Þ ß à á â ã ä å æ ç è
é ê ë ì í î ï ð ñ ò ó ô õ ö ÷ ø ù ú û ü ý þ
Für den Test sollten folgende Profile Paramter des betreffenden Accounts
auf UNLIMITED gesetzt werden.
ALTER PROFILE your_profile
LIMIT PASSWORD_REUSE_TIME UNLIMITED
PASSWORD_REUSE_MAX UNLIMITED;
Remote OS Authentification
Sie kennen sicher die OPS$ User. Der Prefix ist änderbar, der Effekt der OS Authentification kann über folgende Syntax genutzt werden.
OS steht übrigens für Operating System
create user ops$ka identified externally;
Einloggen kann man sich dann recht knapp mit :
sqlplus /
Leider ist das nicht die volle Wahrheit .
Wenn Sie einen OPS$ Account, exakt mit diesem Prefix, in folgender Form anlegen :
create user ops$ka identified by "Tiger-Lady#512";
kann man sich sowohl über das Passwort als auch über das OS einloggen.
Dem kann man eigentlich nur
verbeugen, indem man den Parameter
os_authent_prefix auf null setzt.
Weiterhin sollten Sie in jedem Fall die remote OS Authentication
unterbinden.
Wenn der Client User Scott auf einer Sun Maschine angelegt wurde und auf
dem Datenbankserver ( DB_HR_PROD) besitzt der Parameter
remote_os_authent den Wert TRUE kann sich der Client User mit
sqlplus /@DB_HR_PROD anmelden.
Noch dramatischer ist die Konsequenz, das dies für alle Unix Rechner gilt, die
diesen OS User besitzen.
Somit sollten die init.ora Parameter hierzu folgendermaßen lauten :
os_authent_prefix = ""
remote_os_authent = FALSE
Unter Windows muss zusätzlich die Domain in den Namen des Userschemas integriert werden, welche für mehr Sicherheit steht.
create user "OPS$HACKER-DOMAIN\GRAVITY" identified externally;
grant create session to "OPS$HACKER-DOMAIN\GRAVITY";
Wenn die Datei sqlnet.ora folgenden Eintrag enthält :
SQLNET.AUTHENTICATION_SERVICES= (NTS)
sollte es auch mit :
sqlplus /
klappen.
Hash Funktionen DES und SHA-1 + Salt
Was versteht man eigentlich unter Passwort ermitteln ?
Meist wird das Ausprobieren verschiedener Kandidaten als Passwort bei der Eingabe vermutet. Bei Oracle Datenbanken funktioniert das eher selten bis nie.
Bis Version 10g müsste hierzu der Profile Parameter FAILED_LOGIN_ATTEMPTS auf UNLIMITED stehen.
Ab Version 11g wurde der initi.ora Parameter SEC_MAX_FAILED_LOGIN_ATTEMPTS
eingeführt. Dieser besitzt den Default 10, könnte jedoch mutwillig auf UNLIMTED gesetzt
werden !
Gemeinhin versteht man bei Oracle Datenbanken unter 'Ermitteln des Passworts', den Hash des Passworts je nach Version mit oder ohne Salz mehr oder minder geschickt sprich flott nachzubilden.
Was ist ein eigentlich ein Hash ? Der Hash ist das Ergebnis einer Hash oder Streuwertfunktion. Die ab Version 11g eingesetzte SHA-1 Hashfunktion kann beispielsweise 2 hoch 68 - 1 Bit exakt und nahezu eindeutig auf 160 Bit reduzieren, ohne das dies mit heutigen Mitteln reversibel wäre. Bis Version 10g wurde der DES Algorithmus verwendet und in einer 64 Bit Form hinterlegt.
Der Grund für den Einsatz von Hashfunktionen liegt einfach darin begründet, dass Oracle das Passwort nicht im Klartext im System hinterlegen will.
Auch wenn der neuere SHA-1 Hash Algorithmus vom amerikanischen Geheimdienst NSA im Auftrag der US-Standardisierungsbehörder NIST entwickelt wurde, gilt dieser nach Meinung von Krypto Experten als sicher und bisher auch ohne eingebaute Hintertür. Es handelt sich um eine Weiterentwicklung des MD4 Algorithmus.
Gebrochen wurde der SHA-1 Algorithmus von der Chinesin Xiaoyun Wang, welche Kollisionen statt in 2^80 zuerst in 2^69 später in 2^63 Funktionsaufrufen generieren konnte.
Die Frage, warum die halbe Welt auf den Nachfolger von SHA-1 wartet und nicht den RIPEMD-160 verwendet, soll jeder für sich selbst beantworten.
Wo liegen nun diese Passwort Repräsentationen in der Datenbank ?
Systemtabelle : sys.user$
- DES Hash ( alt ) in Spalte Password <= 10g
- SHA-1 Hash + Salt ( neu ) in Spalte SPARE4 >= 11g
Eigentlich sind die Hashfunktionen für relativ kurze Passwörter nicht der ideale Schutz.
Daher hat Oracle ab Version 11g für die Bildung des Hashes SHA-1 aus dem eigentlichen Passwort ein zufällig generiertes Salz hinzugeführt. Dies ist in erster Linie ein Schutz gegen den Einsatz von Rainbow Tables und als Tarnung des eigentlichen Algorithmus anzusehen, da für ein Klartextpasswort mehrere Hashes je nach Salz erzeugt werden können.
Ohne den DES Hash und mit nur einem Sonderzeichen versehene 11g Passwörter erschweren Angreifern das Leben enorm. Leider gilt das für auch für einige Passwort Checker, bei denen man sich immer gefragt hat, wie machen die das so schnell ?
Bei der Spalte SPARE4 der user$ handelt es sich somit um einen SHA-1 Hash aus der Zusammensetzung des Passworts, sowie eines zufällig generiertem Salz. Nach Bildung des Hashes wird nochmals dasselbe Salz konkateniert.
Tabellle sys.user$ Spalte :
SPARE4 enthält : SHA-1( passwort||salt)||salt
Es liegt auf der Hand, das bei dieser Form des Angriffs der Spare4 bekannt
sein. Hierzu gibt es diverse Methoden, die fast alle darin münden, den Hash
letztendlich aus der Systemtabelle sys.user$ auszulesen.
Über die System-View DBA_USERS sind die Hashes ab 11g immerhin nicht mehr auslesbar.
Unbekannte und unmögliche Passwörter
Als Schutzmaßnahme für bestimmte Accounts die vorläufig nicht benutzt werden sollen, gab es bis Version 10g die Möglichkeit ein unmögliches Passwort zu setzen.
Das bedeutet das es unmöglich ist, sich mit diesem Passwort anzumelden.
ALTER USER DBSNMP IDENTIFIED BY VALUES 'invalid_PW'
Ab Version 11g gibt es diese Funktionaliät in dieser Form nicht mehr.
Statt ein unmögliches Passwort zu setzen, ist es offensichtlich einfach ein unbekanntes Passwort zu setzen. Wenn man einen SPARE4 Eintrag mit hohem Wiedererkennungswert wie z.B.
S:66666666666666666666666666666666... setzt, scheint der Ersatz gefunden.
Man hat ein einfaches Muster und sieht sofort, wenn jemand das Passwort geändert hat.
Leider ist dem nicht so.
Da sowohl Passwort und dessen Komplexität nicht bekannt sind, kann es sein, das sich hinter dem obigen Beispieleintrag für SPARE4 ein triviales Passwort der Länge 3 bestehend aus Großbuchstaben + Salz verbirgt. Es besteht die Gefahr, das dieses Passwort in kürzester Zeit ermitttelt werden könnte.
Lösung 1 :
Eine Lösung besteht in der Entwicklung eines Programms, welches ein zufälliges Passwort z.B. der Länge 20 -30 Zeichen aus z.B. 62 oder 65 Zeichen Vorrat erzeugt und dies als Basis für die SPARE4 Erzeugung verwendet.
Unser schönes einfaches Muster des SPARE4 wurde zwar nicht verwirklicht, allerdings ist über das fixe vorgegebene Salz eine starke wenn auch nicht hundertprozentige Verfizierungshilfe geschaffen.
SHA-1 ( 'unbekanntes Passwort'||'66666666666666666666' )||'66666666666666666666'
Es versteht sich von selbst, das für produktive Zwecke nur das Programm zur Laufzeit das Passwort kennt und eben nicht ausgibt.
Für den produktiven Einsatz empfielt sich neben der zufälligen Länge in einem Range zusätzlich die Auswahl aus z.B. [a-z] [A-Z][0-9] [#$_] bei jedem Zeichen.
Hier eine PL/SQL Funktion die ein zufälliges Passwort erzeugt :
Das verwendete Package random ist von Jeff Hunter
http://www.idevelopment.info/data/Oracle/DBA_tips/PL_SQL/PLSQL_9.shtml
Test Aufruf :
select rand_pwd ( 25,30) from dual;
CREATE OR REPLACE
FUNCTION rand_pwd(
min_l NUMBER,
max_l NUMBER)
RETURN VARCHAR2
IS
pwd VARCHAR2(30);
pwd_chars VARCHAR2(65);
cnt pls_integer;
BEGIN
pwd_chars :=
'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789#$_';
cnt := 1;
WHILE cnt <= floor(ABS(dbms_random.value(min_l,max_l)))
LOOP
pwd :=
pwd||SUBSTR(pwd_chars,random.rndint(length(pwd_chars))+1,1);
cnt :=
cnt
+1;
END LOOP;
RETURN pwd;
END ;
/
Funktionsergebnis :
OFv021FH1ZBAM79Soad$YOw
Der Aufruf dieser Funktion erfolgt in der Function zur Erzeugung des SHA-1
select build_hash( rand_pwd(20,30), '66666666666666666666') from dual;
CREATE OR REPLACE
FUNCTION build_hash_ka(
my_pwd IN VARCHAR2,
my_salt IN VARCHAR2)
RETURN VARCHAR2
IS
lv_pwd_raw RAW(128);
lv_enc_raw RAW(2048);
lv_hash_found VARCHAR2(300);
lv_salt VARCHAR2(20);
lv_detect VARCHAR2(20);
lv_cnt pls_integer;
lv_pwd VARCHAR2(30);
BEGIN
lv_cnt := 1;
lv_pwd_raw :=
utl_raw.cast_to_raw(my_pwd)||hextoraw(my_salt);
lv_enc_raw := sys.dbms_crypto.hash(lv_pwd_raw,
3);
lv_hash_found:=utl_raw.cast_to_varchar2(lv_enc_raw);
RETURN to_char(lv_enc_raw);
END;
/
Ausgabe :
'E9769EE2226DDFDC8508DC8BB188AB7CD647E67F'
Dies wird mit dem fixem Salz konkateniert und dem Präfix 'S:' versehen.
'S:E9769EE2226DDFDC8508DC8BB188AB7CD647E67F66666666666666666666'
Lösung 2:
Eine weitere Lösung besteht darin, ein nicht gültiges Zeichen in das Passwort einzufügen.
Im Prinzip reichts als Passwort ein Zeichen, das über die normale Policy niemals genutzt werden darf. z.B. '"' ein Double Quote.
SHA-1( '"'||'66666666666666666666')||'66666666666666666666'
Damit haben Sie ein bekanntes aber unmögliches Passwort und können Ihre Accounts schützen.
Erzeugter Spare4 basierend auf > "||66666666666666666666 <
S:6845B2F3A2DC58D8FDC4A11CA7125448E96C332A66666666666666666666
Dies Lösung wurde auf einer Oracle 11.2.0.3 mit dem Zeichensatz AL32UTF8 verifiziert.
Wenn Sie einen User unter 11g mit 'identified by values' anlegen, wird nur der SPARE4 angelegt. Das Feld 'password' in der sys.user$ , der DES Hash, ist nicht gefüllt. Außerdem wird die Passwort Verification Function nicht durchlaufen !
Prüfen Sie solche Verfahren auf unbedenklichen Testsystemen und beachten Sie, das der init.ora Parameter case_sensitive_logon auf true gesetzt ist. Gehen Sie weiterhin sehr gewissenhaft mit der Anzahl der Zeichen in SPARE4 um. Nicht exakte Längen ( != 62 ) führen minimal zu einem ORA-600 !!
Externe
SHA-1 Verfizierung
Haben Sie sich schon mal gefragt, ob Oracle tatsächlich den offiziellen SHA-1
Algorithmus
nutzt. Trösten Sie sich, ich zuerst auch nicht. Nachdem ich allerdings mein
C-Programm zur Erzeugung eines 30 Zeichen Passworts mit SHA-1 testen
wollte, kam es zu Unstimmigkeiten.
Wenn man den bekannten Quellen glauben darf, besteht der Spare4 Eintrag
aus
- Sha-1 ( pwd||salt) || salt
Das Salz bekommt man über :
select substr(spare4,43,20) as salt from user$ where name = 'user';
Also gesagt getan:
Passwort und Salt konkateniert und durch das Programm gejagt.
Leider stimmte das Ergebnis nie mit dem SHA-1 Anteil des Spare4 Eintrags aus
der Datenbank überein.
Bei näherer Betrachtung fällt auf, das das Salz als Hexdezimaler Wert in einem
Varchar2 gespeichert wird. Weiterhin wird meist die Hash Funktion des
DBMS_CRYPTO Packages in der RAW Variante für die Oracle interne Verifizierung
verwendet. Also alles auf Raw konvertieren.
Der Trick besteht in der differenzierten Konvertierung von Passwort und Salz,
wie ich mir bei Pete Finnigan abgeschaut habe.
Das Passwort kann entweder mit :
lv_pwd_raw := UTL_I18N.STRING_TO_RAW ('Tiger', 'AL32UTF8');
oder mit :
lv_pwd_raw:= utl_raw.cast_to_raw('Tiger');
nach Raw konvertiert werden.
Für das Salz hingegen muss die Funktion hextoraw verwendet werden, da dieses
wie gesagt als Hex Wert vorliegt.
lv_pwd_raw := lv_pwd||hextoraw('031C7289587B9D8DAAAD');
Nach externer Verifizierung der SHA-1 Hashes von Oracle ist übrigens davon
auszugehen, das sich Oracle an die Referenz des SHA-1 hält.
Passwort merken, wenn es 12 Stellen und mehr hat
Stufe 1 : Basics
Hier einige sehr subjektive Hinweise zu Brücken, die dem einen oder anderen User das Merken von Passworten mit 12 oder mehr Stellen vielleicht erleichtert.
Generell eigenen sich bestimmte Sprüche, Gedichtzeilen, Liedertexte,... die sich tief in das Langzeitgedächnis eingegraben haben.
Davon dann entweder ganze Wörter bzw. die Anfangsbuchstaben case sensitive und eine Zahlenkombination
"John Maynard war unser Steuermann,
aushielt er, bis er das Ufer "
1972 durfte ich das Gedicht auswendig lernen
ergibt somit :
JMwuSaebedUg1972
Schwäbisches Statement zu einem geplanten unterirdischen Bahnhof
im Jahre 2010
" Des brauchet mir net "
Desbrauchetmn2010
Soweit die französische Zahlenlogik present ist :
Die Zahl 99 aber mit deutschen Wörtern
VierMalZwanzig109 <quatrevingtdixneuf>
Oder ein Hobby mit technischen Daten.
Mein erstes Auto war ein Ford 20 M P7b Bj. 71 mit 2,6 Liter Motor und einer 4,11 er Hinterachse. T steht für Trenner
20mTP7bT1971T26TL411
Bitte nicht die Automarke verwenden !
Mein Kollege empfiehlt Wörter sinnlos aneinanderzureihen und mit einer Zahlenkombination zu versehen.
Stabhochkegler93
Zwingerpipette99
FlüchtigeNachhaltigkeit93
Hüten Sie sich vor:
NeagtivesWachstum
Eine besonders originelle Variante besteht darin, im Passwort eine Nachricht an den Angreifer zu hinterlegen.
"Du Dösbaddel, das ist eh nur ein Dummy Account um Dir auf die Schliche zu kommen"
DDdieneDAuDadSzk
Auf die Blacklist gehören, wie schon erwähnt, Klarnamen
von Frauen, Männern, Autoherstellern, Fahrradmarken, Städten, ...
Weiterhin keine Geburtstage, KFZ- Kennzeichen, Hausnummern, ...
Umstritten verhält es sich mit dem integrativen Ansatz Bankverbindungen oder gar Pin Codes in einem Passwort zu hinterlegen. Ab 12 Stellen ist es zwar recht unwahrscheinlich, das es geknackt wird, ich würde es dennoch nicht empfehlen.
Stufe 2 : Ersetzungen 1:1
Aus der Passwort Vorlage
'Sigmar-ist-bei-Pelzig'
wird
'$!@ma<-!st-be!-%elz!@'
Stufe 3 : Ersetzungen 1:N
Aus Sigmar wird
'$$$!!!@@@mar'
Stufe 4 : Systematische Ersetzungen
Ändern Sie Ihre Ersetzungszeichen nach einem System :
Verschiebung um eine Anzahl Zeichen positiv oder negativ in einem bestimmten
ASCII Zeichen Intervall bzw. Intervallen mit Intervall Wechsel.
Ändern Sie bei Einsetzungen die Anzahl der Zeichen, welche ein Ausgangszeichen ersetzen
Ein Programm zu diesem Zweck wird hier demnächst veröffentlicht.
Ein weitere Hilfe könnte das Major System sein.
Dieses basiert auf der Zuordnung von Lauten zu Ziffern sowie Wörtern zu Zahlen.
0 s, z, ß, ss, c
(weich) vgl. englisch zero
1 t, d, th t könnte man mit einer
1 verwechseln, d ist lautverwandt
d und t haben einen Abstrich (Linie nach unten)
2 n n hat zwei Beine
3 m m hat drei Beine
4 r vier endet mit r
5 l L erinnert an die römische
Ziffer 50
L = Hand mit abgespreizten Daumen = 5
Finger
6 ch, j, sch, g (weich) sechs hat
viele s
j wie Dschungel
g als gedrehte 6
7 k, ck, g (hart), c (hart) 7 ist
eine Glückszahl
K setzt sich aus zwei 7 zusammen
8 f, v, w, ph V8-Motor bei VW
das handschriftliche f hat genau wie 8
zwei Schleifen
9 p, b 9 ist ein gespiegeltes p
oder gedrehtes b (beide sind lautverwandt)
Vokale sind frei nutzbar um Worte zu bilden.
Aus der '8' wird das Wort 'Affe'
So kann die alte PIN : '3087' der EC Karte schnell zu einem : 'msvc' werden in der einfachen Form mit 1:1 Zuordnung. Sie können jedoch auch Worte und Sätze bilden.
Damit die Romantiker vielleicht doch noch zum Zuge kommen, ist die Rückwärtsanwendung in der folgenden Form möglich :
Aus 'Schatz ich liebe Dich' wird '061065916' und sieht aus wie eine Telefonnummer.
Hochpriviligierte User nehmen gern beschreibende Kürzel Ihrer Systeme und kombinieren diese mit dem Ersetzungsansatz, wenn überhaupt.
Davor möchte ich dringend warnen.
Kürzel von PROD, TEST, DEV, ... oder auch HR, FIN, ERP, ... eventuell mit Zahlen versehen sind schnell in Standardpassworttabellen integriert. Da nutzt auch eine Ersetzung nach einfachen Mustern wenig. Die Algorithmik der schnellsten Knackprogramme richtet sich zudem nach Auswertungen von Statistiken bzw. wenn möglich, nach Auswertung von User Profiles und Verification Functions und arbeiten in der Abfolge nach Wahrscheinlichkeiten.
Oracle User Profiles
Wußten Sie das die beiden Parameter
- password_reuse_max
- password_reuse_time
mit dem Default UNLIMITED die erneute Verwendung des selben Passworts zu jeder Zeit erlaubt ?
Bitte setzen Sie einen oder beide Parameter ungleich UNLIMTED.
Die Anbindung eines Users an ein Profile erfolgt mit :
alter user <user_name> profile enduser
Nutzen Sie eigene Profiles nach Einstufung der User in eine bestimmte Kritikalität.
Das 'Default' Profile sollte die Passwort Lebensdauer für genau einen Tag erhalten.
PASSWORD LIFE TIME = 1
Oracle Password Verification Function
Die Verwendung einer Password Verification
Function ist die einzige Möglichkeit,
die Komplexität von Passwörtern sicherzustellen, sofern man die offiziell
dokumentierten Befehle zur Anlage bzw. Änderung benutzt.
Hier ein Pl/SQL Codefragment welches die REGEXP Implementierung von
Oracle verwendet.
-Prüft auf eine Zahl einen Buchstaben und ein Sonderzeichen
- IF NOT( regexp_like(password,'[[:digit:]]')
- AND regexp_like(password,'[[:alpha:]]')
- AND regexp_like(password,'[[:punct:]]')
- ) THEN
- raise_application_error(-20123,
- 'Password muss eine Zahl einen Buchstaben und ein Sonderzeichen enthalten');
- END IF;
Zusätztlich ist es möglich, eine Tabelle mit nicht erlaubten Zeichenketten
( Frauennamen, Männernamen, Autonamen, ... ) zu hinterlegen.
Das zu prüfende Passwort kann mit der Tabelle abgeglichen werden.
Die Anbindung an den User erfolgt über das Profil mit :
alter profile enduser limit password_verify_function verify_function_endusr
Oracle DES Hashes entfernen
Ab Version 11g hält Oracle sowohl den alten DES als auch den neuen SHA-1 Hash+Salt in der sys.user$ vor. Um nun generell die Verwendung der SHA-1 Hashes+Salt zu erzwingen, wäre es hilfreich sich der alten Hashes zu entledigen.
Warum sollte man dies erzwingen ?
Die Existenz des DES Hashes der implizit das Password in Großbuchstaben umwandelt, ist eine große Hilfe beim Knacken der Passwörter. Die Kombinationen von Groß und Kleinbuchstaben mit oder ohne Zahlen sind stark eingeschränkt und können vergelichsweise schnell ermittelt werden.
Wie die Entfernung von Oracle empfohlen wird, erläutert der Artikel MOS -463999.1.
MOS steht für My Oracle Support früher Metalink.
______________________________________________________________________
Erstmal keine Rechte - ein ungewohnter Ansatz für mehr Datensicherheit
Je mehr statische Zugriffsrechte in einem Datenbanksystem vorhanden sind, umso
mehr Angriffsfläche für Missbrauch wird geboten. Dem alten Katz und Maus Spiel
kann man durchaus entgehen, wenn man von Anfang an einem zunächst
ungewöhnlichen Ansatz folgt.
Hier der Kernpunkt :
Es gibt zu einem produktiven Anmeldezeitpunkt keinerlei Zugriffsrechte außer
'Create Session' für den entsprechenden Account.
Dies gilt für alle Accounts, auch für die hochpriviligierten Accounts.
Grundprinzip :
Ausgehend von einem Account bzw. einer Rolle stehen alle
Authentifizierungsregeln sowie alle Objekt und Systemprivilegien in einer
gekapselten Tabellen basierten Metastruktur.
Je nach Kritikalität der Daten, auf die ein Account zugreifen darf, wird
ein Authentifizierungscheck dynamisch erzeugt und durchgeführt.
Auf das positive Ergebnis folgt eine 'on the fly' Rechteerzeugung samt
Zuweisung und Auditierung.
Es folgt der operative Datenzugriff des Users über die Anwendung mit der
festgelegten Protokollierung.
Vor dem Logoff der jeweiligen Session werden die Rechte entzogen.
Falls die Session vorzeitig abbricht, sorgt ein dezidiert gestarteter Job für
den Rechtentzug, der über den zentralen Error Trigger der Datenbank sofort
ausgeführt wird.
Falls die Datenbank abstürzt, sorgt ein Startup Database Trigger für den Entzug
aller Rechte im Exclusive Mode, bevor die Datenbank normal geöffnet wird.
Umsetzung :
Als erstes implementieren wir folgende Trigger konkret oder als Skeleton :
- Database Error
- Database After logon
- Database Before logoff
- Database DDL
Wir implementieren die Metastruktur ausgehend vom Account bzw. der Rolle :
- Authentifizierungsregeln
- Auditierungsbefehle
- Objektprivilegien
- Systemprivilegien
jeweils mit Zuweisung und Entzug
Optional ist hier VPD bzw. OLS integrierbar.
Weiterhin benötigen wir eine dynamische PL/SQL Routine, welche die
Authentifizierungsregeln, die Auditiierungsregeln als auch die Privilegien
generiert und zuweist bzw. entzieht (profile, audit, noaudit, grant, revoke )
Weiterhin wird ein zentraler Job aufgesetzt, der jede Rechteänderung auf
Systemtabellenebene mit den expliziten 'on the fly' Rechtevergaben abgleicht.
Implizite Rechteänderungen durch Oracle werden herausgefiltert.
Übrig bleiben potentielle Rechteänderungen, die auf einen Angriff hinweisen.
Wir benötigen abschließend einen 'before logoff' Trigger, der die Rechte
über die erzeugten PL/SQL Module wieder entzieht.
Vorteile :
- Zentrale Kontrolle über die Zugriffsrechte.
- Keinerlei statische Angriffsflächen.
__________________________________________________________
Forensik
- Anzeichen für Datenmissbrauch
Datenmissbrauch hat viele Gesichter.
Der böse Einzelhacker aus der russischen Förderation oder noch besser aus dem
fernen China muss oft für allerlei Schandtaten herhalten, die er nicht begangen
hat.
Wirtschaftkriminalität ist sicher ein Fakt aber führen Sie sich folgendes
Augen:
Wie oft wurde bei Ihnen real eingebrochen, mit Tür und Fenster öffnen und wie
oft hatten Sie unschöne Erlebnisse mit Kollegen, Bekannten ja sogar Feunden und
Partnern, die Ihnen in irgendeiner Form Nachteile oder Schaden verursachte ?
Genug der Vorrede. Der Feind steht zu 99% auf Ihrer Mitarbeiterliste. Der Rest
kommt tatsächlich von außen.
Generell gibt es vielfältige Motivationen bezgl. Datenmissbrauch.
Spieltrieb von unbeachteten oder verkannten Genies
Geheimdienste und andere Behördern - Daten sammeln
Konkurrenzfirmen - Was geht ab beim Branchenprimus ?
Eigeninteressen von Mitarbeitern
Falsches Ziel - man hat Sich getäuscht
oder Kombinationen.
Da gibt es Menschen mit langjährigen Ablaufwissen und Zugängen, die nie
konsolidiert wurden. Diese Gruppe will oft gar keinen Missbrauch betreiben,
allein die Gewissheit, das Sie könnten wenn Sie wollten, stellt diese Gruppe
häufig ersteinmal zu zufrieden.
Da ist die Gruppe der Trainee's, die systematisch immer mehr Zugriffsrechte
anhäufen und schnell so manchen Topmanager bezgl. Berechtigungen in den
Schatten stellen. Auch diese Gruppe ist überwiegend ersteinmal nicht
professionell auf Datenmissbrauch aus.
Für beide bisher genannten Gruppen besteht jedoch eine hohe Anfälligkeit gegen
Anwerbung von der Konkurrenz, von Geheimdiensten, Hackern, ... .
Weiterhin gibt es Accounts mit deutlich zu hohen Privilegien. Dies hat mehrere
Ursachen und nebem der Standardunterstellung Faulheit gibt es in vielen Firmen
kein angemessenes Berechtigungskonzept. Selbst wenn es ein verbindliches
Berechtigungskonzept gibt, wird dies unter diversen Gründen, seien diese real
oder vorgeschoben, aufgeweicht.
Viele Hacker wissen genau um die menschliche Psyche. Und diese hat meist gerne
weitreichende Berechtigungen und wird nur in wenigen Fällen zyklisch überprüft
und konsolidiert.
Was machen diese Leute nun eigentlich mit Ihren, wie auch immer erlangten
Rechten ?
Auch hier ist die Bandbreite gewaltig :
Mr Super Hacker bricht ein und klaut sämtliche Kundendaten mit einen
Auftragsvolumen ab z.B. 2 Mio jährlich. Dumm nur, das er das Datenmodell nicht
verstanden hat und es nicht der Umsatz sondern ausstehende Zahlungen >= 2
Mio. waren.
Der Bankmitarbeiter reduziert die Hypthotek seines guten Kumpels von Euro
500.000 auf null und erhält dafür Euro 100.00, die dieser bei Ihm als
Kreditsachbearbeiter über einen Kredit erhält. Das Spiel läuft dann ewig so
weiter bis es doch noch jemand merkt, es sein denn, die Herrschaften können der
Wiederholung wiederstehen.
Der langjährige Abteilungsleiter, der sämtliche Software System Einführungen
miterlebt hat, ist von der Konkurrenz angeworben worden, exakt für ein Produkt
gefälschte Daten zu hinterlegen. Ziel ist es das Marketing, die
Produktentwicklung, das Management bezogen auf dieses Produkt in die Irre zu
führen. z. B. Das definierte Produkt verkauft sich bestens, da müssen wir
nichts groß machen, soll die Auswertung ergeben. Der Abteilungsleiter denkt
einige Zeit nach, läßt einen Prozeß/Security Check mit exakter Dokumentation
der Transaktionskonzepts anfertigen und schafft die Manipulation tatsächlich
mit zwei Updates über eine Excel Maskierung von Oracle SQLPLUS
ren SQLPLUS.EXE EXCEL.exe
Wie kommt man nun solchen Missbrauchsvorfällen auf die Schliche ?
Mit einer systematischen Spurensuche.
Wir machen es wie viele andere auch, wir sammeln Daten.
Abgrenzung Policy Verstöße und Forensik :
Konkrete Vorgaben bzw. Regeln wie z.B. ein technischer Users darf keine Audit
Trail Einträge löschen sind Policy Verstöße, auf die aktiv reagiert werden
darf. Forensik über gesammelte Daten, hat ersteinmal nichts mit aktiven
Eingriffen zu tun. Die Daten werden mit Hilfe von Data Mining nachgeschaltet
ausgewertet und vielleicht entdecken Sie ja, das ein spezieller Mitarbeiter
Funktionen in Ihrem Anwendungssystem hat, die nie im Pflichtenheft standen.
Die strikte Trennung dieser beiden Bereiche ist zwar möglich, unsere Empfehlung
ist jedoch die Installation eines Frühwarn bzw. Notfall Systems über eine
simple Bewertung von Indizien. Meldet sich ein bekannter User von einer
Maschine an, die bisher noch nicht bekannt ist und verändert Gehälter mit
SQLPLUS oder einem anderen Programm und nicht über die Anwendung und
versucht anschließend das Audit Trail zu manipulieren, so ergibt sich aus
den vier Punkten beispielsweise folgende Bewertung :
- Logon from foreign Machine 2
- Use of SQLPLUS/Excel as techn. user 5
- UPDATE salary via SQLPLUS 10
- INSERT/UPDATE/DELETE Audit Trail 5
Gibt zusammen 22 Punkte . Ab z.B. 12 Punkte darf automatisiert aktiv
eingegriffen werden. Ab z.B. 7 Punkte, wird eine Email an die
entsprechenden Security Officer verschickt.
In diesem Fall wäre die Beendigung der Session allein schon wegen Punkt 4
hinreichend und begründet durch den schweren Policy Verstoß.
Da dies allerdings der letzte Punkt des Angriffs im zeitlichen Ablauf ist, und
die Punkte 1 bis 3 jeweils einzeln nicht hineichend für z.B.
eine Beendigung der Session sind, greift das Bewertungssystem über
Aktionsabfolgen.
Welche Daten benötigen wir für Forensik und die angrenzenden Sicherheitssysteme
?
- Alle Datenbank und OS Logons/Logoffs, ob erfolgreich oder nicht, sowie die Anzahl der Loginversuche.
- Alle lesenden Zugriffe auf kritische Tabellen/Views
- Alle Strukturänderungen im Data Dictionary sowie von kritischen Tabellen/Views
- Alle Datenmanipulationen von kritischen Tabellen/Views
- Alle Fehler in der Datenbank und auf dem OS bzw. Netzwerk
- Alle neuen bzw.geänderten Datenbankobjekte sowie veränderte bzw. neu angelegten OS Files
- Alle Konfigurationsänderungen im Bereich Datenbank, OS, Netzwerk, Storage
- Auflistung der operativen Anwendungen, mit denen Daten geändert werden dürfen sowie das Gegenstück.
- Zyklische Checks auf Tabellen/Spalten/Daten bezgl. Kopie, Existenz, Fälschung.
- Zyklische Checks auf Möglichkeiten von SQL Injection durch unsicheren PL/SQL oder hinreichende Berechtigungen.
Ein besonderer Punkt ist die Protokollierung des Aufrufs mehr oder minder
bekannter Oracle Funktionen, die hochkritisch sind. Hierzu benötigen wir einen
Scanner der alle Aufrufe erkennt.
Wie bekommen wir das Ganze in den Griff ?
Wir beschränken uns ersteinmal auf die Datenbank am Beispiel einer Oracle 11g.
Wir gehen idealisiert von einem sauber konfigurierten und eingestellten
Datenbanksystem aus.
Besonders die Authentifizierung und Autorisierung soll nahezu perfekt
abgebildet sein.
Unter diesen Voraussetzungen genügen unter bewußtem Ausschluß der Performance,
genau vier logische Datenbanktrigger für alle Punkte ausser den zyklichen
Checks und dem Call Scanner :
- LOGON/LOGOFF
- DML
- DDL
- ERROR
Mit dem Logon Trigger können wir alle Clients, die wir nicht kennen ersteinmal
ablehnen.
Dies bedingt einen Verifizierungs und Freigabeprozeß z.B. für einen Excel
Zugriff auf die Datenbank, wenn es denn ein Excel ist.
Mit dem DML Trigger können wir auf Ebene der Systemtabellen ( sys.auth$, ...
) jede Rechteänderung nachvollziehen.
Mit dem DDL Trigger können wir Kopien, Substitute, ... erkennen.
Mit dem Error Trigger können wir systematische Angriffe erkennen, wenn wir die
Standardfehler kennen und entsprechend filtern. So manches
Standardsoftwaresystem unterdrückt allerhand Exceptions.
Für die zyklischen Checks stellen wir eine Liste mit kritischen bis sehr
kritischen Tabellen auf.
Dies könnte z.B. die Tabelle mit allen Kreditkartennummern Ihrere Kunden sein,
oder aus Sicht des DBA's die Tabelle sys.user$.
Wir suchen dann in der Datenbank, besser dem Data Dictionary nach Kopien dieser
Tabellen.
Generalisiert suchen wir nach Kopien, Extrakten, Substituten von
Tabellen oder Spalten mit vertraulichen Daten aus den Bereichen, HR, Finance,
Produktentwicklung, ... .
Spaltennamen sind übrigens meist recht aussagekräftig. Passworte oder bestimmte
Personendaten lassen sich oft bei der Auswertung des Data Dictionary ermitteln.
Die Gesetze des jeweiligen Landes schreiben vor, welche Daten von Mitarbeitern
und Kunden gespeichert werden dürfen. Sind Sie sicher, das nicht teils höchst
subjektive und nicht gesetzeskonforme Einschätzungen von Mitarbeitern und
Kunden bei Ihnen gespeichert werden.
Zurück zu den Kopien von bestimmten Tabellen. Wenn Sie solche in
Produktivsystemen finden, gibt es nur noch wenig Spielraum für denjenigen der
diese angelegt hat.
Warum ?
Nach dem Erkennen über den zyklischen Check, werten wir die Daten des DDL, DML
und Logon Trigger aus und haben den Bösewicht. Wie schon erwähnt, steht er
höchstwahrscheinlich auf der Mitarbeiterliste Ihrer Firma auch wenn er über
einen russischen Proxy seine Aktivitäten zu kaschieren versucht.
Forensik
- Top 5
Neben der
Auswertung aller obigen Punkte des Activity Monitoring
zusätzlich :
- Suchen nach unsichtbaren Usern
- Suchen nach Kopien von kritischen Tabellen ( Struktur )
- Suchen nach Kopien von kritischen Spalten ( Struktur)
- Suchen nach Kopien Daten z.B. von SPARE4/DES/Kreditkartennummern Inhalten
- Suchen nach Angriffsmustern über Abfolgen von Aktionen in Protokolldaten
No
SQL Injection
SQL Injection kennt heute fast jeder. Weniger bekannt sind einsetzbare Muster,
die der SQL Injection in bestimmten Bereichen einen Riegel vorschieben.
Neben den Einsteiger Tipps mit Double Quotes und dbms_assert gibt einen
entscheidenden Ansatz, der hier beschrieben wird.
Viele Angriffe basieren auf der Tatsache, das Prozeduren/Funktionen Parameter
übergeben werden, die eigentlich nicht vorgesehen waren.
Durch die Standard Methoden des Quoting und Remarking können im Fall Dynamic
PL/SQL
gefährlicher Code explizit, singulär oder zusätzlich ausgeführt werden.
Stmt:="Alter user "||getuserid()||" identified by
""||userpassword||""";
execute_sql (stmt);
Erwartet wird etwas in dieser Art :
Alter user xxx identified by "tiger"
Nun passiert es - statt lediglich "tiger" wird eine Modifikation übergeben
:
"tiger" connect through sysman with role
dba--"
Das letzte Double Quote " welches
fix im Ursprungscode codiert wude, wird durch -- als Kommentar geparst und
somit aus Sicht des Angreifers neutralisiert.
Daraus wird im Ergebnis durch Nutzung der Proxy User
Authentifizierung eine heftige Privilegieneskalation :
Alter user xxx identified by "tiger"
connect through sysman with role dba--"
Wir haben indirekt DBA Rechte !
Die erste Erkenntnis lautet : Wenn schon Prozeduren/Funktionen, dann bitte
mit lückenloser Plausibilisierung aller möglichen Eingaben.
Neben den schon erwähnten Standard Tipps hierzu, läuft das Ganze auf einen
eigenen Parser zwecks Validierung der Eingabe Parameter hinaus. Die Anworten
die Sie diesbezgl. von Ihrem Vorgesetzten erwarten können, wollen wir Ihnen
ersparen.
Zum Ansatz :
Klassisch werden im Bereich Dynamic SQL, gemeint ist Dynamic PL/SQL, mit den
Stufen 1 -4 hantiert. Vom einfachen dynamischen Einsetzen einer
where-Clause bis hin zum volldynamischen SQL Statement ist alles zu machbar. In
einigen unserer Projekte wurden Packages geschrieben, welche über Metadaten in
Tabellen Packages generieren, die wiederum Packges generierren.
Letztere wurden auch noch operativ eingesetzt. Zweck dieser Techniken ist bei
uns immer die Effizienz bei der Erzeugung und Änderung von PL/SQL
Code gewesen. Die manuell geschriebene Menge an Code ist sehr
überschaubar, im Vergleich zu den Mengen, die erzeugt werden können. Die
Metastruktur mit den Generatorfunktionen ist sehr flexibel. Den einzigen
Mangel aus Sicht der Security war eben die Erzeugung von z.B. Dynamic SQL
- Prozeduren, welche Parameter besitzen und nicht
sauber plausibilisiert wurden.
Solche Techniken werden in der Regel nicht "on the fly" eingesetzt
sondern "pre-generated".
Sie sind somit vollständig der Softwareentwicklung zuzuordnen.
Der sichere Ansatz ist vom Prinzip her identisch, mit einem Unterschied :
Es werden nur statische Prozeduren/Funktionen erzeugt und wenn Parameter, dann
zumindest für DML/DDL nur indirekt über Synonyme.
Die Rahmenbedingungen :
Eine Metastruktur mit den entsprechenden SQL Anteilen, diese allerdings
verschlüsselt.
Das kann durchaus ein "Grant dba to ka" sein, aber auch ein
Stück Metacode für eine Prozedur.
xxx
Der Knackpunkt ist der Aufbau der Metastruktur. Diese ist vereinfacht eine
Baumstruktur, die ausgehend von der Wurzel, ähnlich einem Build, alle
notwendigen Schritte durchläuft.
Die Steuerung, die nicht über direkte Parameter läuft, kann über Synonyme und
einem einfachen von/bis partiell genutzt werden.
Der select auf die Metastruktur erfolgt über einen gekapselten "Select
Into" mit dem hart hinterlegten Synonym für den Root Einstieg in die
Metastruktur.
Solche Sicherheitsmaßnahmen sind allerdings nur dann notwendig, wenn der Ansatz
"on the fly" gefahren wird.
Die Metastruktur ist wie schon erwähnt verschlüsselt und operativ im read-only
Mode.
Implemet
Secure
PL/SQL Programming
SQL Injection kennt heute fast jeder. Weniger bekannt sind einsetzbare Muster,
die der SQL Injection in bestimmten Bereichen einen Riegel vorschieben.
Neben den Einsteiger Tipps mit Double Quotes und dbms_assert gibt einen
entscheidenden Ansatz, der hier beschrieben wird.
Viele Angriffe basieren auf der Tatsache, das Prozeduren/Funktionen Parameter
übergeben werden, die eigentlich nicht vorgesehen waren.
Durch die Standard Methoden des Quoting mit Concat und Remarks kann im
Fall Dynamic PL/SQL
gefährlicher Code ausgeführt werden.
Stmt:="Alter user "||getuserid()||" identified by
""||userpassword||""";
execute_sql (stmt);
Erwartet wird etwas in dieser Art :
Alter user xxx identified by "tiger"
Nun passiert es - statt lediglich "tiger" wird eine Modifikation
übergeben :
"tiger" connect through sysman with role
dba--"
Das letzte Double Quote " welches
fix im Ursprungscode codiert wude, wird durch -- als Kommentar geparst und
somit aus Sicht des Angreifers neutralisiert.
Daraus wird im Ergebnis durch Nutzung der Proxy User
Authentifizierung eine heftige Privilegieneskalation :
Alter user xxx identified by "tiger"
connect through sysman with role dba--"
Wir haben indirekt DBA Rechte !
Die Idee :
Plausibilisierung der Parameter bzw. Eingaben
Statt statisch zig-fach codiert, liegt der Prüfungscode ( Plausis) in einer
Metatabelle.
Von dem Plausi Baukasten in der Metatabelle kann beliebig referenziert
werden. Das heißt, eine einzelne Prüfung kann in diversen Procedures/Functions
eingesetzt
und verwendet werden.
Schutz des Quellcodes vor neugierigen Blicken
Über Markieren potentiell gefährliche Quellcodezeilen in existierenden
Prozeduren
und Funktionen, werden nur die gefährlichen Teile des Quellcodes
ausgelagert.
Diese markierten Quellcodezeilen werden automatisiert
und verschlüsselt in einer
Metatabelle abgelegt. Weiterhin werden die Prozeduren und Funktionenin in
gültige
Skelett Objekte verwandelt. Bei Bedarf werden diese dann automatisiert
mit dem
Original Quelltext versehen. Damit dieser Quelltext nicht direkt
lesbar ist, wird eine
implizit erzeugte Prozedur 2.ter Ordnung wrapped kompiliert
und in die eigentliche
Prozedur als Aufruf integriert.
Anwendungsfälle :
Gefährliche Procedures/Functions mit Dynamic SQL ( NDS, DBMS_SQL) oder gemischt.
Dynamische Vergabe von Privilegien über System Logon-Trigger in Abhängigkeit
von
Art der Authentifizierung, IP Adresse, Tag, Tageszeit, Funktion/en des
Mitarbeiters, ...
Beispiel :
Wir haben eine potentiell gefährliche
Stored Procedure, welche das Passwort
in der Datenbank ändern kann oder eben per SQL-Injection mißbraucht werden
kann.
Das gute Stück, hier 'account_mgmt' genannt, ist häufig bei Kunden
anzutreffen und sieht kurz und knapp ( Zeit ist Geld ) etwa derart aus :
PROCEDURE
account_mgmt(
p_name IN VARCHAR2,
p_pwd IN VARCHAR2)
AS
BEGIN
execute immediate 'ALTER USER
'||p_name||' IDENTIFIED BY '||p_pwd;
END;
/
1.) Wir setzen eine Prüfebene mit einem klassischen IF_THEN_ELSE
ein.
PROCEDURE account_mgmt(
p_name IN VARCHAR2,
p_pwd IN VARCHAR2)
AS
BEGIN
IF ( p_name in
('KARSTEN', 'RAYNA' ) AND regexp_like(p_pwd,'^.*[^A-Z,0-9].*$')
THEN
execute immediate 'ALTER USER '||p_name||' IDENTIFIED BY '||p_pwd;
ELSE
send_msg ( ' Param not valid. ' , 'CSO'); END;
END IF;
END;
/
2.) Wir formatieren die Prozedur so um, das jede Bedingung und
jedes Statement in einer eigenen Zeile stehen.
Statt :
IF ( p_name
in ('KARSTEN', 'RAYNA' ) ) AND
regexp_like(p_pwd,'^.*[^A-Z,0-9].*$')
THEN
schreiben wir :
....
IF
( p_name in ('KARSTEN',
'RAYNA' )
AND
regexp_like(p_pwd,'^.*[^A-Z,0-9].*$')
THEN
...
3.) Wir
markieren die Codezeilen die geschützt werden sollen
mit z.B. '-->~~< S_1'
oder mit '-->~~< O_1'
S_1 steht für Statement_1 und wird mit
'null;' ersetzt.
O_1 steht für Otherss_1 und wird mit 'null'
ersetzt.
....
IF
( p_name in ('KARSTEN',
'RAYNA' )
-->~~<
OT_1
AND
regexp_like(p_pwd,'^.*[^A-Z,0-9].*$')
-->~~<
OT_2
THEN
execute immediate
'ALTER USER '||p_name||' IDENTIFIED BY '||p_pwd; -->~~< ST_1
ELSE
send_msg ( ' Param not valid. ' , 'CSO');
END; -->~~< ST_2
END IF;
...
Zusätzlich fügen wir als erste Zeile nach dem
initialen 'BEGIN'
folgende Signatur ein.
v_stmt := 'p_name, p_pwd ' -->~~< SG_1
Dies ist die Markierung für die Einsetzung der
Wrapped Prozedur, die
automatisch erzeugt werden wird.
Hier der Zustand der Prozedur
Initial von Hand
PROCEDURE
account_mgmt(
p_name IN VARCHAR2,
p_pwd IN VARCHAR2)
AS
v_stmt
VARCHA2(200);
BEGIN
v_stmt := 'p_name, p_pwd
' -->~~< SG_1
IF
( p_name in
('KARSTEN', 'RAYNA' ) -->~~< OT_1
AND
regexp_like(p_pwd,'^.*[^A-Z,0-9].*$')
-->~~< OT_2
THEN
execute immediate 'ALTER
USER '||p_name||' IDENTIFIED BY '||p_pwd; -->~~< ST_1
ELSE
send_msg ( ' Param not valid. ' , 'CSO'); END; -->~~< ST_2
END IF;
END;
/
4.) Wir starten mit folgendem Aufruf :
SELECT chg_src_code ( 'HR', 'ACCOUNT_MGMT', 'RE_ENG')
FROM dual;
Wir speichern lediglich die markierten Zeilen
samt Markierung in einer Metatabelle
Natürlich verschlüsselt mit 'dbms_crypto' oder besser noch
mit einer
eigenen Routine, z.B. die von Jonas Gehrunger
http://www.albert-offenbach.de/index.php?option=com_content&view=article&id=510:1-platz-beim-wettbewerb-explore-scienceq&catid=3:news&Itemid=120
4.) Wir setzen die Metatabelle in den Modus 'read-only'
ALTER TABLE dyn_src ADD CONSTRAINT dyn_src_read_only
CHECK(1=1) disable VALIDATE;
oder ab 11g mit dem entsprechenden Befehl
ALTER TABLE dyn_src READ ONLY;
Weiterhin sind folgende Auditbefehle
abzusetzen :
audit alter table by userschema by access;
audit execute on hr.sec_hlp by access;
5.) Wir initialsieren die Prozedur über unsere Funktion im Modus 'INIT'.
Hierbei werden die markierten Zeilen mit dem jeweiligen
Default ( null, null; ) ersetzt.
Der Default steht in als zweiter Parameter in der Markierung
'-->~~< SQLSTM_1 null dummy'.
Anschließende wird die Prozedur implizit kompiliert.
Wir haben jetzt eine gültige Prozedur(valid) , die
allerdings nichts sinnvolles aber auch
nichts gefährliches tun kann.
Die Idee ist, das solche Skelett - Prozeduren und
Funktionen nur bei Bedarf mit Inhalt
gefüllt werden. Nach Abschluss der Verarbeitung sollte die
Prozedur wieder auf
dasSkelett zurückgesetzt werden.
Dies ist der gesicherte Zustand der Prozedur. Macht nichts
und kann nicht mißbraucht werden.
CREATE
OR REPLACE PROCEDURE HR.account_mgmt (
p_name IN VARCHAR2,
p_pwd IN VARCHAR2)
AS
v_stmt VARCHAR2(500);
BEGIN
v_stmt := 'p_name, p_pwd '
-->~~< SG_1
IF
null
-->~~< OT_1
AND
null
-->~~< OT_2
THEN
null;
-->~~<
ST_1
ELSE
null; -->~~< ST_2
END IF;
END;
/
6) Zur operativen Nutzung unserer Prozedur rufen wir unser Verwaltungsfunktion
im
Modus 'SECPL' und 'H' für Hard bzw. 'B' für
'BIND' auf.
Jetzt passiert folgendes :
- Es wird aus dem
Quelltext der Prozedur ( user_source ) und dem Inhalt der
Tresors ein
anoyn. PL/SQL Block erzeugt.
- Alle Parameter können
hart hinreingeneriert 'H' oder als Bind's 'B' verarbeitet werden.
- Der Aufruf des Block
entschlüsselt zuerst und führt den Block dann aus.
- In jedem Fall zerstört
sich die aktuelle Memory Instanz über den letzten Aufruf.
- Falls der Parameter
'H' verwendet wurde, müssen bei neuerlichem Aufruf alle Schritte der
Neuerzeugung durchgeführt werden.
- Im Fall 'B' für Bind
werden im verschlüsselten String lediglich die Parameter mit replace
ausgetauscht.
Der Vorteil liegt auf der Hand. Durch diese Anordnung ist
uns der Weg
zurück zum Klartext der Prozedur im Wartungsmodus möglich.
Der eigentliche Code ist im PL/SQL Block. Die Original
Prozedur besitzt den
Zustand 'INIT' + den Call für den Aufbau sprich Ausführung
des PL/SQL Blocks'
als erstes Statement !
CREATE OR
REPLACE PROCEDURE HR.account_mgmt (
p_name IN VARCHAR2,
p_pwd IN VARCHAR2)
AS
v_stmt VARCHAR2(500);
BEGIN
gen_blk( 'account_mgmt', p_name , p_pwd )
-->~~< SG_1
IF
null
-->~~< OT_1
AND
null
-->~~< OT_2
THEN
null;
-->~~< ST_1
ELSE,
null; -->~~< ST_2
END IF;
END;
/
Mit dem Parameter 'SECPL' wird ein anoymer PL/SQL Block aufgebaut. Der String hierzu ist
vollständig verschlüsselt. Unverschlüsselt ist nur während der Ausführung im
Speicher und zerstört sich anschließend selbst.
7.) Im Modus 'MAINT' wird, soweit vorhanden, der Aufruf der 'Wrapped
Procedure'
account_mgmt_sec (p_name, p_pwd ) -->~~<
SG_1
entfernt
-->~~< SG_1
und anschließend der Klartext des Quelltexts aus der Metatabelle
in die Prozedur integriert.
Jetzt kann der Entwickler die Prozedur
'account_mgmt' wie gewohnt bearbeiten.
PROCEDURE
account_mgmt(
p_name IN VARCHAR2,
p_pwd IN VARCHAR2)
AS
v_stmt
VARCHA2(200);
BEGIN
v_stmt := 'p_name, p_pwd
' -->~~< SG_1
IF
( p_name in ('KARSTEN',
'RAYNA' ) -->~~< OT_1
AND
regexp_like(p_pwd,'^.*[^A-Z,0-9].*$')
-->~~< OT_2
THEN
execute immediate
'ALTER USER '||p_name||' IDENTIFIED BY '||p_pwd; -->~~< ST_1
ELSE
send_msg ( ' Param not valid. ' , 'CSO'); END;
-->~~< ST_2
END IF;
END;
/
8.) Das Verstecken des Quellcodes ist zwar ganz nett. Der entscheidende Schritt
ist
allerdings die Plausibilisierung. Denn ohne dies könnte die
'Wrapped Procedure' mit
SQL-Injection aufgerufen werden. Auch wenn die
Lebensdauer dieser Procedure nur
sehr kurz sein sollte, ist es theoretisch denkbar.
Damit deutlich wird, wie aufwändig die Plausibilsierung ist,
möchte ich für die Password
Überprüfung mal die wichtigsten Prüfungen auflisten :
- Länge von z.B. 12 - 18
- Zeichensatzüberprüfung Festlegung mit welchen die Prozedur arbeiten soll
- Datenbankversionsprüfung und Einstellung 'CASE_SEC_SENSITIVE' Einstellung
- CHECK User auf Art der Authentififizierung
- Check auf USER und PROFILE sowie Kollission mit Password Verify Function
- Kein '-' bzw. '--'
- Zahlen von 0-9 positiv Anzahl > 1
- Zeichen a-z/A-z Anzahl > 1
- Sonderzeichen '$%&#_§' Anzahl > 1
9.) Ob man sprechende Namen für gefährliche Prozeduren sollte, ist eine
schwierige Frage.
Ich würde aus 'account_mgnt' jedenfalls nicht
'lddfgf232TR' machen, weil damit in
erster Linie die Entwickler verwirrt werden und ein
Angreifer sofort sieht, welche Procedures für Ihn
Potential haben könnten.. Wie wäre es mit
'str_betwn'.
Vorteile :
Original Procedure / Function wird nie gelöscht und muss nicht zwingend
recompiliert werden.
States und andere Abhängigkeiten können somit erhalten werden.
Der Quellcode befindet sich nur im Wartungsmodus 'MAINT' in der
Procedure/Function
Die Metatabelle fungiert als Quellcode Tresor und enthält lediglich zu
schützende Codezeilen und nicht den gesamten Quellcode
Der Ansatz läßt sich neben dem Sicherheitsaspekt als generelle Lösung für dyn.
pl/sql nutzen. Es lassen sich alle Arten von PL/SQL Fragmenten beliebig
einbauen.
Typen, Cursor, Varray's, Bindvariablen, dms_assert,
Aus Sicht der Entwickler kann alles wie bisher bleiben.Der Code wird direkt
editiert.
Alternativ kann getester Code direkt in die Metatabelle eingefügt
werden, nachdem
diese in read/write gesetzt wurde.
Performance :
Da es es keinerlei EInschränkungen bezgl. der Verwendung von PL/SQl Performance
Techniken gibt, bleiben als
Overhead die Leseoperationen auf die Metatabelle die Entschlüsselung (
einmalig). Untersuchungen zu Cursor Caching und VPD Context Einstellungen
werden in einem separaten Artikel erläutert.
Die Geamtlösung umfasst ein Package mit Hifsfunktionen ( crypto, checksum,
..
Die Metatabelle enthält Checksummen in Blöcken überlappend geschachtelt sowie
einen simplen Freigabemechanismus für jede einzelne Codezeile.
Das gesamte Package wird operativ ebenfalls im Codetresor liegen.
Es gibt zwei Versionen :
- Produktiv mit lediglich den Modi 'INIT', 'SECU'.
- Wartung mit allen Modi 'RE_ENG', 'INIT', 'MAINT', 'SECU'
Bei Interesse können Sie mich unter ka@db-consult-aalderks.de erreichen
___________________________________________________________________________________________
Ausblick : Die nächste Stufe ist der Ausbau in Richtung MetaTabellen
getriebene Erzeugung von Procedures/Functions und Packages zur Laufzeit in
beliebiger Tiefe bzw. in beliebiger Anzahl.
Beispiel :
Der Parameter 'Jahresabschuß' erzeugt alle notwendigen Procedures/Functions
und/oder Packages, die eben für den Jahresabschluß notwendig sind. Nach
erfolgreichem Lauf des
Jahresabschluss werden alle erzeugten Procedures/Functions und Packages
gelöscht.
Ausnahme ist ein initialer Dummy, der allerdings nicht nur für den
Jahresabschluß herhalten muss.
Massivst
Parallel - Performance unter Oracle
Um die Jahrtausendwende wurde ich zu einem Kunden gerufen, der ein spezielles Problem hatte. Ein Datenmodell mit mehreren hundert Tabellen besaß durchgängig ein Flag names Aktuell. Dieses Aktuellkennzeichen musste jede Nacht nach einfachen Regeln überprüft und ggfs. geändert werden. Sinn des Ganzen war eine Markierung, ob ein Datensatz aktuell ist oder eben nicht. Alternativ gab es die logischen Stati Historie und Zukunft. Soweit so gut. Ein vorhandenes PL/SQL Programm benötigte mittlerweile mehr als 8 Stunden um jeden Datensatz jeder Tabelle auf dem aktuellen Stand zu halten.Das Batchfenster drohte zu platzen. Die Analyse des PL/SQL Programms ergab, das der Programmierer eine Riesenschleife über alle Tabellen, eine innere Schleife über jeden Datensatz programmierte und dann per 'dbms_sq'l jedesmal, wenn eine Änderung des Aktuellkennzeichens anstand, den kompletten dyn. SQL Zyklus abarbeitete.
Mein Ansatz ging in Richtung ‘Divide and Conquer‘ mit dyn. PL/SQL statische PL/SQL Prozeduren zur generieren. Die Idee war die Tabellen, ob sie nun 10 Werte oder 2 Mio Datensätze enthielten, in limitierte Pakete bzegl. Antzahl der Datensätze aufzuteilen ( z.B. count between 1 and 20.000 via rowid). Diese Pakete bekammen dann ein pre-generated und nun statisch codiertes Update Statement mit den Prüfregeln verpasst. Allerdings mengenorientiert. Damit es keine Engpässe bei der geplanten Parallelverarbeitung gab, wurden soviele Rollback Segmente angelegt, wie später Jobs ( DBMS_JOB) maximal parallel aktiv waren und - statisch - im generierten Code zugewiesen. Die einzige Herausforderung war es nach Möglichkeit zu verhindern, das bei der parallen Verarbeitung über DBMS_JOB unnötige Locks auf einer einzelnen Tabelle entstehen. Dies war allerdings auch nicht schwierig, da im pre-generated Code alle Infos abgelegt waren. Vielleicht habe ich es auch über die Namen gelöst.Schlussendlich liefen etwa 20 Jobs parallel gegen das Datenmodell und arbeiteten Tausende von vorher generierten statischen Update Prozeduren ab. Das Ergebnis hat mich selbst überrascht.
Aus über 8 Stunden wurden etwa 4 Minuten, 2 Minuten generieren und 2Minuten Laufzeit.
Woran lag es nun, das die Zeiten derart drastisch verkürzt wurden. Mein Ansatz mit der Parallesierung war gewiß nicht schlecht, doch diese Dimensionen kommen nicht durch die Parallelisierung. Hauptgrund für den Performance Boost ist das Fehlen von parse und bind Statements.In der ersten Lösung kummulierten millionenfache Parse/Binds Statements zu einem gewaltigen Engpass. Den Programmierer trifft keine Schuld. PL/SQL war Neuland für ihn. Er bekam ein Steven Feuerstein Buch in die Hand gedrückt und hatte nach Lehrbuch nichts falsch gemacht.
SYS_GUID() als Default Function spart bis zu zwei Trigger
Ich weiß gar nicht, ob Sie's schon
wussten, ... ( Rüdiger Hoffmann )
1.)
Statt einer Sequenz und einem Trigger, der eindeutige Nummern einträgt
kann man sich das Leben einfacher machen.
Die Funktion SYS_GUID() liefert einen eiindeutigen RAW Wert und ist die einzige
Funktion
die in der Default Clause einer Table Definition erlaubt ist.
create table creditcard
(
id raw(16)default sys_guid()primary
key,
creditcard varchar2(30) not null )
/
2.)
Wenn man zusätzlich mitbekommen möchte, ob Datensätze
in bestimmte Tabellen eingefügt werden,
kann man für genau diesen Fall auf einen individuellen Row Table Trigger
verzichten.
Selbst geschriebene Funktion sind laut Oracle Dokumentation und den
entsprechenden Fehlermeldungen
nicht in der Default Clause von Tabellendefinition erlaubt.
Das stimmt nicht ganz. en
Da der SQL Parser nicht erkennt, ob es die Standardfunktion SYS_GUID() ist oder
eine selbstgeschriebene Funktion ist,
kann man eine eigene SYS_GUID() Funktion schreiben, die zusätzlich zur
Erzeugung der GUID das Insert Statement erkennt und protokolliert. Die
Filterlogik für die betreffenden Tabellen kann über einen System Logontrigger
in einem logischen Array im Speicher abgelegt werden.Die eigene
SYS_GUID() Funktion greift dann mit wenig Kosten auf die
Zusatzfunktionalität zu oder nicht.
Der Vorteil für diese Lösung liegt in wesentlich weniger Code und in der
zentralen Verwaltung einer Funktion/Schema.
In einem Datenmodell mit 500 Tabellen fallen
- 500 before insert row Sequence Trigger
- 30 before insert row Trigger
weg.
Die Funktion muss DETERMINISTIC sein und wenn eine Persistierung benötigt wird,
- PRAGMA AUTONOMOUS TRANSACTION.
Die Macht der Virtual Columns Teil1
Scope: Erkennung von legalen und illegalen Select Statements gegen kritische Spalten mit differenzierter Behandlung. Normale Anwender,hochpriviligierte Anwender als auch klassische Angreifer von Innen und Außen können unterschiedlich behandelt werden, ohne generell und einzig die Holzhammermethode 'Terminate Session' zu verwenden. Um die Mitarbeiter zu schützen, wird das Event-Actor Prinzip empfohlen.
Vorteil : Man kann blind, ohne Sichtbarkeit der Mitarbeiternamen erkennen, wie die jeweiligen Policies eingehalten werden,
Ein sehr einfaches Beispiel :
Das Aufgabe ist nicht ungewöhnlich.
Ein Schutz für kritische und sehr kritische Daten.
Wir haben eine Tabelle Creditcard.
Es soll die Spalte Credicard Nr. geschützt werden.
Der Zusatz klingt auch noch harmlos : Protokollierung aller Select's gegen die Tabelle, die Creditcard Nr. enthalten.
Der nächste Zusatzanforderung ist schon interessanter :
Wie im Activitiy Monitoring, soll die Möglichkeit des Eingriffs vor der Ausführung dieses Select's möglich sein.
Was könnten aus der Security Brille betrachtet Eingriffe sein ?
Falls derjenige der selektiert, als Angreifer oder nach Unternehmenspolicy als nicht autorisiert erkannt wird, und der Select somit als illegal eingestuft wird über
IP, Machine, Program, Time, ...
könnten die Eingriffe folgende Ergebnisse liefern bzw. folgende Aktionen durchführen :
- Honeypot Values
- Null Values
- Terminate Session
- ...
Nur eben nicht die reale Creditcard Nr liefern. Das Standardverhalten des Eingriffs sind bei als legal eingestuften Select's die Entschlüsselung, das Zusammensetzen oder andere Methoden der Herleitung unserer realen Creditcard.Nr..
Die Erkennung von Angreifern kann z.B. über System Logon Trigger und entsprechende Logik/Rule Engines implementiert werden und wird in diesem Beitrag nicht näher erläutert.
Wie man die Hauptanforderungen über eine simple Virtual Column in der betreffenden kritischen Tabelle abbilden kann, soll nun gezeigt werden.
Den Beispielcode für die enrypt und decypt Function habe ich aus einem Artikel von Heinz-Wilhelm Fabry (Oracle) übernommen.
http://www.oracle.com/webfolder/technetwork/de/community/dbadmin/tipps/crypto/index.html
Schritt 0:
- grant execute on dbms_crypto to scott;
Schritt 1:
Schlüsselt - Audit_Select Tabelle :
CREATE TABLE schluesseltabelle
(
schluessel RAW(300) NOT NULL,
startdatum DATE NOT NULL,
enddatum DATE
);
CREATE TABLE audit_select
(
table_s VARCHAR2(30) NOT NULL,
column_s VARCHAR2(30) NOT NULL,
osuser_s VARCHAR2(30) NOT NULL,
schema_s VARCHAR2(30) NOT NULL,
program_s VARCHAR2(100) NOT NULL,
machine VARCHAR2(100) NOT NULL,
tmstamp TIMESTAMP
);
INSERT
INTO schluesseltabelle
(
schluessel,
startdatum
)
VALUES
(
DBMS_CRYPTO.RANDOMBYTES(32),
sysdate-7
);
Function :
CREATE OR REPLACE
FUNCTION dcrypt(
eingabe IN RAW)
RETURN VARCHAR2 DETERMINISTIC
IS
PRAGMA AUTONOMOUS_TRANSACTION;
v_os VARCHAR2(30);
v_schem VARCHAR2(30);
v_mach VARCHAR2(100);
v_prg VARCHAR2(100);
v_daten RAW(200);
v_schluessel RAW(32);
v_verschluesselung PLS_INTEGER := DBMS_CRYPTO.ENCRYPT_AES256 +
DBMS_CRYPTO.CHAIN_CBC + DBMS_CRYPTO.PAD_ZERO;
BEGIN
SELECT schluessel
INTO v_schluessel
FROM schluesseltabelle
WHERE sysdate BETWEEN startdatum AND NVL(enddatum, sysdate);
v_daten := DBMS_CRYPTO.DECRYPT( src => eingabe, typ =>
v_verschluesselung, KEY => v_schluessel);
SELECT osuser,
schemaname,
machine,
program
INTO v_os,
v_schem,
v_mach,
v_prg
FROM v$session
WHERE sid IN
(SELECT sys_context('USERENV','SID') FROM dual
);
INSERT
INTO audit_select VALUES
(
'CREDITCARD',
'CREDITCARD_NR',
v_os,
v_schem,
v_mach,
v_prg,
systimestamp
);
COMMIT;
RETURN UTL_I18N.RAW_TO_CHAR(v_daten, 'AL32UTF8');
END;
/
Schritt 2:
Zusätzlich benötigen wir eine simple Enryption Function
CREATE
OR REPLACE
FUNCTION ecrypt
(
eingabe IN VARCHAR2
)
RETURN RAW DETERMINISTIC
IS
v_rohdaten RAW(200);
-- Variable für verschlüsselten Wert
v_schluessel
RAW(32);
-- Variable für 256-bit Schlüssellänge
v_verschluesselung PLS_INTEGER := -- Kennung für
Verschlüsselungsalgorithmus
DBMS_CRYPTO.ENCRYPT_AES256 + DBMS_CRYPTO.CHAIN_CBC +
DBMS_CRYPTO.PAD_ZERO;
BEGIN
SELECT schluessel
INTO v_schluessel
FROM schluesseltabelle
WHERE sysdate BETWEEN startdatum AND NVL(enddatum, sysdate);
v_rohdaten := DBMS_CRYPTO.ENCRYPT( src =>
UTL_I18N.STRING_TO_RAW (eingabe, 'AL32UTF8'), typ => v_verschluesselung, KEY
=> v_schluessel);
RETURN v_rohdaten;
END;
/
Schritt 3:
Wir definieren die Tabelle Creditcard und fügen einen Datensatz ein. Interessant ist hier die Definition der Virtual Column credit_card_nr mit der Funktion dcrypt und dem Parameter card_nr_ecrypt.
CREATE TABLE creditcard
(
id
NUMBER,
-- persistent
card_nr_ecrypt RAW(400)
,
-- persistent
credit_card_nr AS (dcrypt(card_nr_ecrypt)
) -- flüchtig
);
/
INSERT
INTO creditcard
(
id,
card_nr_ecrypt
)
VALUES
(
1,
ecrypt('5554334334453344')
);
COMMIT;
Select * from creditcard;
Ausgabe :
Select * from audit_select;
Ausgabe :
Im Beispiel werden lediglich alle Select's mit der
Spalte Creditcard Nr. in der Tabelle Audit_Select mitprotokolliert.
Sie werden sich wundern, wer da noch so alles zugreift :
- gather_table_stats
- interne pre / preprocessor select's
- Geheimdienst A
- Trainee A
- Noch-Mitarbeiter A
- Monitoring Tool A
- Security Tool A !
- Chef A
- gefühlter Chef A
- ...
Ich bitte zur Kenntniss zu nehmen, das die Gruppe der DBA's nicht in den Beispielen auftaucht, ebenso nicht der einsame chinesische Hacker aus der Provinz Jiangsu, obwohl das 'su' schon im Namen der Provinz ist.
Bewertung : Dieser Ansatz eignet sich sinnvollerweise für Neuentwicklungen.Allerdings sind mitunter die schützenswerten Tabelllen oder besser Spalten quantitativ recht überschaubar. Der Änderungsaufwand hält sich in Grenzen, wenn man den Code vorher generiert.
Warum vorher ?
Mit einer volldynamischen Function ( Type 4) hätte man zwar viel Quellcode gespart, die Kosten ( parses / binds ) könnten den Ansatz in Realumgebungen jedoch gefährden. Sinnvoller wäre es, die diversen Functions vorher schematisch zu erstellen/generieren.
Hier nochmal die einzelnen Schritte ::
- Zusätzliches Spaltenattribut Colum Enrypted in Tabelle einbauen und Org. Datum verschlüsseln
- Decrypt Funktion mit statischem Code für diese Tabelle/Code generieren
- Org. Column mit Virtual Colum und Funktionsaufruf ersetzen !
Vergleichsbetrachtung :
Im Vergleich mit der Wunderwaffe McAfee Database Activity Monitoring ( Hedgehog) bietet diese Lösung für einen speziellen Fall sogar Vorteile.
Wenn ein Select als illegal eingestuft wird und terminiert werden soll, kann es sein, das Hedgehog bevor er die Session terminiert hat, einige Datensätze an den Angreifer durchläßt.
Der hier beschrieben Ansatz kann dies in jedem Fall unterbinden!
Der Angreifer bekommt z.B. nur 'XXXXXXXXXXXXXX' als Creditcard Nr. zurückgeliefert. Die Session kann zusätzlich in aller Ruhe terminiert werden.
Performance Aspekte:.
Soweit es vergleichsweise wenige kritische Tabellen/Spalten betrifft, sehe ich kein Problem.Beim allgemeinen Ansatz schon eher. Allerdings müssen ja nicht alle kritischen Spalten 'on the fly' erzeugt/errechnet werden. Wenn z.B.die anonymisierten Daten in irgendeiner Form in einem eigenen Schema vorliegen, wird einfach der Zugriff 'umgebogen'.Dies erfolgt in der aktuellen Ausbaustufe auf Schemaebene über das Identity Managementsystem ( Logon Trigger). Bei einer partiellen Anonymisierung in der Funktion der Virtual Column.
Genaue Performancemessungen folgen.*
Fazit :
Aktuell kann sinnvollerweise in Verbindung mit dem erwähnten Identity Managementsystem ein mindestens 2-stufiges Zugriffsschutzsystem mit reinen Bordmitteln realisiert werden.
Im nächsten Teil wird gezeigt, wie man sehr einfach mitbekommt, ob
andere Schemauser auf die Spalte Creditcardnr. zugegriffen haben inkl. sys und
system.
Sqlplus / as sysdba ausschalten
Einloggen lokal mit Password erzwingen, und
sysdba's deaktivieren
sqlnet.ora
SQLNET.AUTHENTICATION_SERVICES=(NONE)
Einloggen von z.B. sys und system ganz unterbinden
Schritt 0: Prozess Notfall Reaktivierung festlegen und
umsetzen . 4 Augen Prinzip ...
Schritt 1:
- sqlnet.ora
- SQLNET.AUTHENTICATION_SERVICES=(NONE)
Schritt 2:
- sec_case_sensitive_logon=false
- wegen O5LOGON Cryp. Flaw
Schritt 3:
- Eigene/n Admin User anlegen
Schritt 4 :
- Unmögliches Password setzen für die betreffenden Schemauser
- Alter user x identified by values '43435464665666666.... '
Schritt 5 :
- Audit auf 'Alter User' aktivieren
Data Treasures oder warum verschlüsseln allein nur bedingt hilft
Die berühmte Kreditkartentabelle wird mit jedem Tag, an dem man über sie nachdenkt, gefährlicher.
Manch einer wünscht sich den hölzernen Zettelkasten zurück, immer im Blick, außer man geht mal kurz ...
Eine Verschlüsselung mittels AES 256 sollte doch eigentlich helfen ?
Ein typischer Kunde :
Wir haben mittlerweile nicht nur die eigentliche Kreditkartennummer verschlüsselt sondern zusätzlich alle Referenzen zum Karteninhaber maskiert und fühlen uns zumindest an dieser Ecke sicher.
Leider ist dem meist nicht so.
Hier der Aufbau von Kreditkartennummern :
http://www.kreditkarte.net/ratgeber/kreditkartennummer
- Die 1.-4. Ziffer geben den Hersteller bzw. Herausgeber an,
- Die 5. Ziffer gibt innerhalb des Herstellers die Art der Kreditkarte an
- Die 6. Ziffer gibt an, ob es sich um eine Partnerkarte, Zweitkarte oder Firmen-Kreditkarte handelt
- Die nachfolgenden Ziffern geben die Kontonummer des Kreditkartenkontos an
- Die letzte Ziffer ist eine Prüfziffer,
anhand derer die rechnerische Richtigkeit der Kreditkartennummer geprüft
werden kann
Wie kann mit diesem Wissen eine
Brute-Force Attacke vom Aufwand her reduziert werden ?
Die fast immer erfüllten impliziten Voraussetzungen für solche Angriffe
lauten :
Der Angreifer hat Zugriff auf alle verschlüsselten Kreditkartennummern die im
Beispiel maximal 16 Stellen besitzen sollen.
Meistens haben die betrfeffenden Tabellen, sowie die Spalten einen sprechenden
Namen wie Creditcard/Creditcard_nr.
Der Angreifer kann davon ausgehen, das die Kreditkartennummer am Stück und in
der richtigen Reihenfolge verschlüsselt wurde.
Der Angreifer kann davon ausgehen, das ein bestimmter
Verschlüsselungsalgorithmus für alle Kreditkartennummern verwendet. wurde -
meist AES 256.
Wenn der Angreifer die Wahl hat zwischen einem Angriff auf einen
Kreditkartenanbieter direkt oder einer Bank, die Kreditkarten für ihre Kunden
verwaltet , wird er sinnvollerweise die Datenbasis wählen, die mehr implizite
Informationen enthält.
Ein Angreifer, der sich jetzt noch auf einen bestimmten Kartenherausgeber beschränkt und vielleicht nur GOLD Kartennummern sucht, reduziert die Anzahl der Stellen für die Brute Force Attacke deutlich.
Bleiben also noch 12 Stellen und
eine Prüfziffer mit 3 Stellen. Der Algorithmus für die Prüfziffer ist ebenfalls
ausführlich im Web dokumentiert.
Tja, mit soviel impiziter Information und den heutigen offiziellen
Möglichkeiten, massive Rechenleistung für wenige Stunden zu mieten, kann
mit dem dümmsten aller Verfahren, dem Ausprobieren, die
Kreditkartennummer schnell ermittelt werden. Noch schneller könnte es mit
den gerade im Bau befindlichen Rechenzentren der NSA oder anderer Dienste
erfolgen, aber diese Dienste wissen wahrscheinlich sowieso schon welche
Karten Sie besitzen und wo diese überall gespeichert sind und was Sie morgen
kaufen werden!
Was tun ?
Einzig die Spalte Creditcard_NR nicht aussagefähig umzubenennen ( XYZ_NUM)
macht wenig Sinn, da sie gerade dadurch aussagefähig wird. Tabellennamen und
alle Spaltennamen zu maskieren würde funktionieren, allerdings nur solange, bis
ein Angreifer den Braten gerochen hat. Zu statisch-weg damit. Regelmäßige
Umbenennungen von Tabellennamen und Spaltennamen sind zeitaufwändig und
fehleranfällig in der Gesamtbetrachtung, wenn die Automation nicht
wohldurchdacht ist.
Eine Idee basiert darauf, die Daten der Kreditkartentabelle nach per Zufall
erzeugten Funktionen zu konkatenieren und darüber eine AES 256 Verschlüsselung
mit Salt und Filler zu erzeugen.
Wo der Schlüssel liegt und die Formatmaske/Formatfunktion abgespeichert
wird, möchte ich aus nachvollziehbaren Gründen nicht verraten.
Jede Row in unserer Tabelle Creditcard ( id number, creditcard_d
varchar2( 4000) ) hat somit einen eigenen Aufbau, der bei jedem Update
geändert wird.
Wie kommt man nun an die Klartext Daten heran ?
Ein Weg, kann die Nutzung einer Table Function sein, die
mittels einer PL/SQL Funktion, die selbst widerum gesichert ist über den weiter
oben beschriebenen High Secure PL/SQL Mechanismus, die Daten stufenweise
zurückverwandelt.
Diese PL/SQL Funktion zur Entschlüsselung und geordneten Formatierung bietet
vielfältige Möglichkeiten um die Daten nicht in einem Rutsch im Klartext
zurück zu liefern. Hier entsteht ein gewisser Spielraum für die Gewichtung von
Performance versus Security. Und selbst wenn ein einziges Funktionsergebnis per
Dump geknackt würde, ist der Aufwand für die Gesamttabelle nach menschlichem
Ermessen zu hoch, abgesehen von dem einem Rechenzentrum der NSA.
Mit dem Wissen um die heutigen Festplattenlesezugriffe, Datenbankblockgrößen,
SAN Caches, Netzwerktransporten und CPU's ergibt sich ein praktikabler
Weg um die Daten mit akzeptabelen Kosten in den Klartext zurück zu
verwandeln. Mit bis zu 4 KBytes Festplattenblockgröße und bis zu 32 KByte
Datenbankblockgröße, lassen sich spezielle Security Tabelspaces anlegen, die
den physikalischen Aufwand deutlich reduzieren. In Memory bzw. Self Destroying
Cache Techniken, können es bezgl. Performance mit so mancher Creditcard Tabelle
aufnehmen, bei der die eigentliche Kreditkartennummer unverschlüsselt aber als
Performance Booster als PK verwendet wird.
Auch wenn es reizt, sollte man keine View über die Tabe Function aufbauen. Das
wäre ein Honeypot mit äußerst teurem Akazienhonig.
Wie man es nun mit der Benennung der Tabelle hält, sollte jeder selbst
entscheiden.
Meine Namenskonvention im Beispiel wäre ein Flip-Flop Paar aus
'Honeypot_Creditcard' und 'Creditcard'. Die High Secure PL/SQL Function der
Table Function regelt auch dies. Allerdings benötigen wir dafür ein
zusätzliches Datum, das im System versteckt wird und die aktuelle Bedeutung
welche Tabelle welche Daten beinhaltet.
Ein Ausbau des Ansatzes in Richtung Clob Netze, die je nach Tagesparole,
kritische Daten von verwürfelt verschlüsselt bis hin zu verwürfelt Klartext
bereitstellen ist denkbar. Dies wäre der Tresor in de fm alle kritischen
Daten gespeichert werden. Die Physik unterstützt solche Ansätze, wie bestimmte
No-SQL Datenbanken zeigen, durchaus performant.
Der Versuch einer sicheren Datenbank über Open Source
Friß oder stirb gilt nur für Langzeitabhängige der großen US-Software Schmieden.
Selbstbestimmung kann jeder erlangen, der sich von unnötigen Abhängigkeiten befreit.
PostgreSQL könnte ein Anfang sein. Fangen wir aus der Sicht von kritischen Daten an.
Anpassungen,
die ich an PostgreSQL vornehmen würde, bevor das gute Stück meine
Fahrradsammlung verwalten darf.
Das Geheimste an meiner Fahrradsammlung ist ein Rad mit 12-Gang Nabenschaltung
von 1998, für das ich tatsächlich
eine Ersatznabe besitze. Das soll natürlich niemand wissen !
· Optionale native Verschlüsselung der Daten auf Festplatte ohne transparente Sicht in der Datenbank
· Lückenlose Verfolgung aller Rechte-Änderungen mit Detection für Privilege Escalation
· Geschützter Zugriff auf das Inhaltsverzeichnis/Metadaten der Datenbank mittels Zertifikaten
·
Zentral
verwalteter regelbasierter Zugriff über alle Schniittstellen / API's inkl. OS
/Shell
virtual patching und terminate bzw. redirect von Datenbankoperationen
· Hermetische Abriegelung der Datenbank im Auslieferungszustand - The Wall
· Spezielle Versionen für Entwickler, Tester , Produktion ( Sicherheitsstufen 1-5 ) jeweils auch als read only!
· Data Treasures für kritische Daten
· Code Treasures für kritischen Code in der Datenbank
· Integriertes dynamisches Identity Management bi direktional
· Transparente Datenmaskierung
· Selbstzerstörungsoption bei festgelegten Ereignissen
· Autopilot für Fake-Datenbanken - Die Spione sollen auch etwas bekommen
· Audit für jede, wirklich jede Aktion ermöglichen
· Jeden Zugriff inkl. read /select auditieren
·
Jede Datei,
die mit der DB arbeitet auditieren (read, append, delete, change perm )
.
Der aufwändigste Punkt ist allerdings die Untersuchung auf vorhandene Sicherheitslücken mit dem Einsatz, der bei Oracle's klassicher Datenbank betrieben wurde bzw. wird.
Die Privilegienfülle von bestimmten Accounts kann bei solch einer Auslegungung durchaus bestehen bleiben. Die Nutzung wird allerdings nicht nur durch Authentication und Authorisation ermöglicht, sondern durch mandatory Freitexteingaben, die den Arbeitszyklus beschreiben bzw. begründen.
Allein durch den letzten Punkt,wird das unnötige Herumgeschraube an den Datenbanken erheblich reduziert. Damit steigt die Sicherheit, so oder so!
Der nächst Schritt ist ein
Fachanwaltstermin, der mir die Regeln für die Lizenz von PostgreSQL ermittelt.
Darauf folgt hoffentlich ein Code Review.
Teil 2 folgt ...